

OPC DA
The features or components discussed in this document are available in TDengine Enterprise only. TDengine OSS does not include these features or components.
This section describes how to create data migration tasks through the Explorer interface, synchronizing data from an OPC-DA server to the current TDengine cluster.
Overview
OPC is one of the interoperability standards for secure and reliable data exchange in the field of industrial automation and other industries.
OPC DA (Data Access) is a classic COM-based specification, only applicable to Windows. Although OPC DA is not the latest and most efficient data communication specification, it is widely used. This is mainly because some old equipment only supports OPC DA.
TDengine can efficiently read data from OPC-DA servers and write it to TDengine, achieving real-time data storage.
Creating a Task
1. Add a Data Source
On the data writing page, click the +Add Data Source button to enter the add data source page.

2. Configure Basic Information
Enter the task name in Name, for example, for environmental temperature and humidity monitoring, name it environment-monitoring.
Select OPC-DA from the Type dropdown list.
If the taosX service is running on the same server as OPC-DA, Proxy is not necessary; otherwise, configure Proxy: select a specified proxy from the dropdown, or click the +Create New Proxy button on the right to create a new proxy and follow the prompts to configure the proxy.
Select a target database from the Target Database dropdown list, or click the +Create Database button on the right to create a new database.

3. Configure Connection Information
Fill in the OPC-DA Service Address in the Connection Configuration area, for example: 127.0.0.1/Matrikon.OPC.Simulation.1, and configure the authentication method.
Click the Connectivity Check button to check if the data source is available.

4. Configure Points Set
Points Set can choose to use a CSV file template or Select All Points.
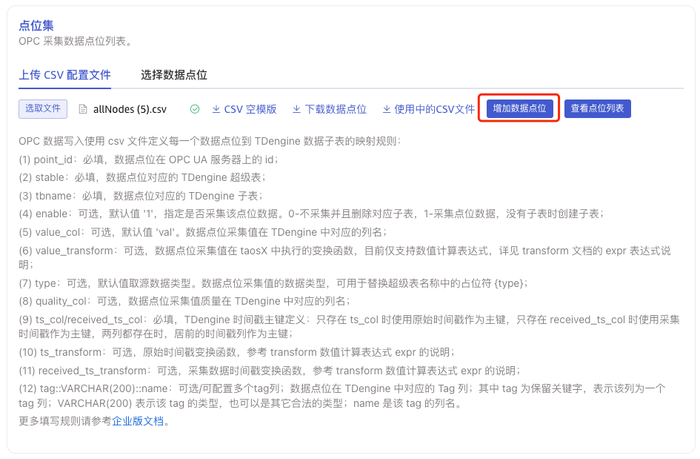
4.1. Upload CSV Configuration File
You can download the CSV blank template and configure the point information according to the template, then upload the CSV configuration file to configure the points; or download the data points according to the configured filter conditions, and download them in the format specified by the CSV template.
CSV files have the following rules:
- File Encoding
The encoding format of the CSV file uploaded by the user must be one of the following:
(1) UTF-8 with BOM
(2) UTF-8 (i.e., UTF-8 without BOM)
- Header Configuration Rules
The header is the first line of the CSV file, with the following rules:
(1) The header of the CSV can configure the following columns:
| No. | Column Name | Description | Required | Default Behavior |
|---|---|---|---|---|
| 1 | tag_name | The id of the data point on the OPC DA server | Yes | None |
| 2 | stable | The supertable in TDengine corresponding to the data point | Yes | None |
| 3 | tbname | The subtable in TDengine corresponding to the data point | Yes | None |
| 4 | enable | Whether to collect data from this point | No | Use a unified default value 1 for enable |
| 5 | value_col | The column name in TDengine corresponding to the collected value of the data point | No | Use a unified default value val as the value_col |
| 6 | value_transform | The transform function executed in taosX for the collected value of the data point | No | Do not perform a transform on the collected value |
| 7 | type | The data type of the collected value of the data point | No | Use the original type of the collected value as the data type in TDengine |
| 8 | quality_col | The column name in TDengine corresponding to the quality of the collected value | No | Do not add a quality column in TDengine |
| 9 | ts_col | The timestamp column in TDengine corresponding to the original timestamp of the data point | No | ts_col, request_ts, received_ts these 3 columns, when there are more than 2 columns, the leftmost column is used as the primary key in TDengine. |
| 10 | request_ts_col | The timestamp column in TDengine corresponding to the timestamp when the data point value was request | No | Same as above |
| 11 | received_ts_col | The timestamp column in TDengine corresponding to the timestamp when the data point value was received | No | Same as above |
| 12 | ts_transform | The transform function executed in taosX for the original timestamp of the data point | No | Do not perform a transform on the original timestamp of the data point |
| 13 | request_ts_transform | The transform function executed in taosX for the request timestamp of the data point | No | Do not perform a transform on the received timestamp of the data point |
| 14 | received_ts_transform | The transform function executed in taosX for the received timestamp of the data point | No | Do not perform a transform on the received timestamp of the data point |
| 15 | tag::VARCHAR(200)::name | The Tag column in TDengine corresponding to the data point. Where tag is a reserved keyword, indicating that this column is a tag column; VARCHAR(200) indicates the type of this tag, which can also be other legal types; name is the actual name of this tag. | No | If configuring more than one tag column, use the configured tag columns; if no tag columns are configured, and stable exists in TDengine, use the tags of the stable in TDengine; if no tag columns are configured, and stable does not exist in TDengine, automatically add the following two tag columns by default: tag::VARCHAR(256)::point_idtag::VARCHAR(256)::point_name |
(2) In the CSV Header, there cannot be duplicate columns;
(3) In the CSV Header, columns like tag::VARCHAR(200)::name can be configured multiple times, corresponding to multiple Tags in TDengine, but the names of the Tags cannot be duplicated.
(4) In the CSV Header, the order of columns does not affect the CSV file validation rules;
(5) In the CSV Header, columns that are not listed in the table above, such as: serial number, will be automatically ignored.
- Row Configuration Rules
Each Row in the CSV file configures an OPC data point. The rules for Rows are as follows:
(1) Correspondence with columns in the Header
| Number | Column in Header | Type of Value | Range of Values | Mandatory | Default Value |
|---|---|---|---|---|---|
| 1 | tag_name | String | Strings like root.parent.temperature, must meet the OPC DA ID specification | Yes | |
| 2 | enable | int | 0: Do not collect this point, and delete the corresponding subtable in TDengine before the OPC DataIn task starts; 1: Collect this point, do not delete the subtable before the OPC DataIn task starts. | No | 1 |
| 3 | stable | String | Any string that meets the TDengine supertable naming convention; if there are special characters ., replace with underscore. If {type} exists: if type in CSV file is not empty, replace with the value of type; if empty, replace with the original type of the collected value | Yes | |
| 4 | tbname | String | Any string that meets the TDengine subtable naming convention; for OPC UA: if {ns} exists, replace with ns from point_id; if {id} exists, replace with id from point_id; for OPC DA: if {tag_name} exists, replace with tag_name | Yes | |
| 5 | value_col | String | Column name that meets TDengine naming convention | No | val |
| 6 | value_transform | String | Computation expressions supported by Rhai engine, such as: (val + 10) / 1000 * 2.0, log(val) + 10, etc.; | No | None |
| 7 | type | String | Supported types include: b/bool/i8/tinyint/i16/smallint/i32/int/i64/bigint/u8/tinyint unsigned/u16/smallint unsigned/u32/int unsigned/u64/bigint unsigned/f32/floatf64/double/timestamp/timestamp(ms)/timestamp(us)/timestamp(ns)/json | No | Original type of data point value |
| 8 | quality_col | String | Column name that meets TDengine naming convention | No | None |
| 9 | ts_col | String | Column name that meets TDengine naming convention | No | ts |
| 10 | request_ts_col | String | Column name that meets TDengine naming convention | No | rts |
| 11 | received_ts_col | String | Column name that meets TDengine naming convention | No | rts |
| 12 | ts_transform | String | Supports +, -, , /, % operators, for example: ts / 1000 1000, sets the last 3 digits of a ms unit timestamp to 0; ts + 8 3600 1000, adds 8 hours to a ms precision timestamp; ts - 8 3600 1000, subtracts 8 hours from a ms precision timestamp; | No | None |
| 13 | request_ts_transform | String | No | None | |
| 14 | received_ts_transform | String | No | None | |
| 15 | tag::VARCHAR(200)::name | String | The value in tag, when the tag type is VARCHAR, it can be in Chinese | No | NULL |
(2) tag_name is unique throughout the DataIn task, that is: in an OPC DataIn task, a data point can only be written to one subtable in TDengine. If you need to write a data point to multiple subtables, you need to create multiple OPC DataIn tasks;
(3) When tag_name is different but tbname is the same, value_col must be different. This configuration allows data from multiple data points of different types to be written to different columns in the same subtable. This corresponds to the "OPC data into TDengine wide table" scenario.
- Other Rules
(1) If the number of columns in Header and Row are not consistent, validation fails, and the user is prompted with the line number that does not meet the requirements;
(2) Header is on the first line and cannot be empty;
(3) Row must have more than 1 line;
4.2. Selecting Data Points
Data points can be filtered by configuring the Root Node ID and Regular Expression.
Configure Supertable Name and Table Name to specify the supertable and subtable where the data will be written.
Configure Primary Key Column, choosing origin_ts to use the original timestamp of the OPC data point as the primary key in TDengine; choosing request_ts to use the timestamp when the data is request as the primary key; choosing received_ts to use the timestamp when the data is received as the primary key. Configure Primary Key Alias to specify the name of the TDengine timestamp column.

5. Collection Configuration
In the collection configuration, set the current task's collection interval, connection timeout, and collection timeout.

As shown in the image:
- Connection Timeout: Configures the timeout for connecting to the OPC server, default is 10 seconds.
- Collection Timeout: If data is not returned from the OPC server within the set time during data point reading, the read fails, default is 10 seconds.
- Collection Interval: Default is 10 seconds, the interval for data point collection, starting from the end of the last data collection, polling to read the latest value of the data point and write it into TDengine.
When using Select Data Points in the Data Point Set, the collection configuration can configure Data Point Update Mode and Data Point Update Interval to enable dynamic data point updates. Dynamic Data Point Update means that during the task operation, if OPC Server adds or deletes data points, the matching data points will automatically be added to the current task without needing to restart the OPC task.
- Data Point Update Mode: Can choose
None,Append,Update.- None: Do not enable dynamic data point updates;
- Append: Enable dynamic data point updates, but only append;
- Update: Enable dynamic data point updates, append or delete;
- Data Point Update Interval: Effective when "Data Point Update Mode" is
AppendandUpdate. Unit: seconds, default value is 600, minimum value: 60, maximum value: 2147483647.
6. Advanced Options

As shown above, configure advanced options for more detailed optimization of performance, logs, etc.
Log Level defaults to info, with options error, warn, info, debug, trace.
In Maximum Write Concurrency, set the limit for the maximum number of concurrent writes to taosX. Default value: 0, meaning auto, automatically configures concurrency.
In Batch Size, set the batch size for each write, that is, the maximum number of messages sent at once.
In Batch Delay, set the maximum delay for a single send (in seconds). When the timeout ends, as long as there is data, it is sent immediately even if it does not meet the Batch Size.
In Save Raw Data, choose whether to save raw data. Default value: no.
When saving raw data, the following 2 parameters are effective.
In Maximum Retention Days, set the maximum retention days for raw data.
In Raw Data Storage Directory, set the path for saving raw data. If using Agent, the storage path refers to the path on the server where Agent is located, otherwise it is on the taosX server. The path can include placeholders $DATA_DIR and :id as part of the path.
- On Linux platform,
$DATA_DIRis /var/lib/taos/taosx, by default the storage path is/var/lib/taos/taosx/tasks/<task_id>/rawdata. - On Windows platform,
$DATA_DIRis C:\TDengine\data\taosx, by default the storage path isC:\TDengine\data\taosx\tasks\<task_id>\rawdata.
7. Completion
Click the Submit button to complete the creation of the OPC DA to TDengine data synchronization task, return to the Data Source List page to view the task execution status.
Add Data Points
During the task execution, click Edit, then click the Add Data Points button to append data points to the CSV file.
In the pop-up form, fill in the information for the data points.
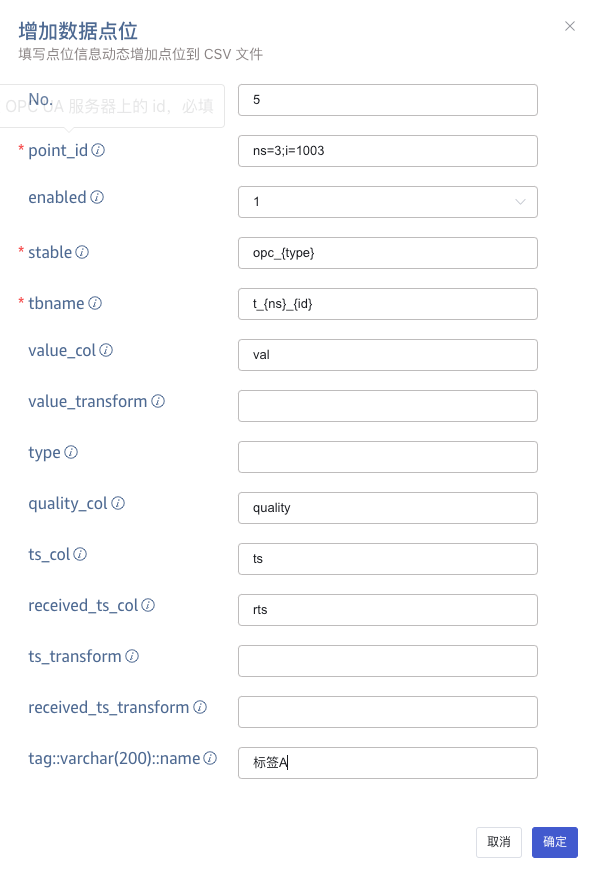
Click the Confirm button to complete the addition of data points.


