

Stream Processing
In the processing of time-series data, it is often necessary to clean and preprocess the raw data before using a time-series database for long-term storage. Moreover, it is common to use the original time-series data to generate new time-series data through calculations. In traditional time-series data solutions, it is often necessary to deploy systems like Kafka, Flink, etc., for stream processing. However, the complexity of stream processing systems brings high development and operational costs.
TDengine's stream computing engine provides the capability to process data streams in real-time as they are written. It uses SQL to define real-time stream transformations. Once data is written into the stream's source table, it is automatically processed in the defined manner and pushed to the destination table according to the defined trigger mode. It offers a lightweight solution that replaces complex stream processing systems and can provide millisecond-level computational result latency under high-throughput data writing scenarios.
Stream computing can include data filtering, scalar function computations (including UDFs), and window aggregation (supporting sliding windows, session windows, and state windows). It can use supertables, subtables, and basic tables as source tables, writing into destination supertables. When creating a stream, the destination supertable is automatically created, and newly inserted data is processed and written into it as defined by the stream. Using the partition by clause, partitions can be divided by table name or tags, and different partitions will be written into different subtables of the destination supertable.
TDengine's stream computing can support aggregation of supertables distributed across multiple nodes and can handle out-of-order data writing. It provides a watermark mechanism to measure the degree of tolerance for data disorder and offers an ignore expired configuration option to decide the handling strategy for out-of-order data — either discard or recalculate.
Tips: Stream computing does not supported in windows platform.
Below is a detailed introduction to the specific methods used in stream computing.
Creating Stream Computing
The syntax is as follows:
CREATE STREAM [IF NOT EXISTS] stream_name [stream_options] INTO stb_name
[(field1_name, ...)] [TAGS (column_definition [, column_definition] ...)]
SUBTABLE(expression) AS subquery
stream_options: {
TRIGGER [AT_ONCE | WINDOW_CLOSE | MAX_DELAY time | FORCE_WINDOW_CLOSE | CONTINUOUS_WINDOW_CLOSE [recalculate rec_time_val] ]
WATERMARK time
IGNORE EXPIRED [0|1]
DELETE_MARK time
FILL_HISTORY [0|1] [ASYNC]
IGNORE UPDATE [0|1]
}
column_definition:
col_name col_type [COMMENT 'string_value']
The subquery is a subset of the regular query syntax.
subquery: SELECT select_list
from_clause
[WHERE condition]
[PARTITION BY tag_list]
[window_clause]
window_clause: {
SESSION(ts_col, tol_val)
| STATE_WINDOW(col)
| INTERVAL(interval_val [, interval_offset]) [SLIDING (sliding_val)]
| EVENT_WINDOW START WITH start_trigger_condition END WITH end_trigger_condition
| COUNT_WINDOW(count_val[, sliding_val])
}
The subquery supports session windows, state windows, time windows, event windows, and count windows. When used with supertables, state windows, event windows, and count windows must be used together with partition by tbname.
-
SESSION is a session window, where tol_val is the maximum range of the time interval. All data within the tol_val time interval belong to the same window. If the time interval between two consecutive data points exceeds tol_val, the next window automatically starts.
-
STATE_WINDOW is a state window. The col is used to identify the state value. Values with the same state value belong to the same state window. When the value of col changes, the current window ends and the next window is automatically opened.
-
INTERVAL is a time window, which can be further divided into sliding time windows and tumbling time windows.The INTERVAL clause is used to specify the equal time period of the window, and the SLIDING clause is used to specify the time by which the window slides forward. When the value of interval_val is equal to the value of sliding_val, the time window is a tumbling time window; otherwise, it is a sliding time window. Note: The value of sliding_val must be less than or equal to the value of interval_val.
-
EVENT_WINDOW is an event window, defined by start and end conditions. The window starts when the start_trigger_condition is met and closes when the end_trigger_condition is met. start_trigger_condition and end_trigger_condition can be any condition expressions supported by TDengine and can include different columns.
-
COUNT_WINDOW is a counting window, divided by a fixed number of data rows. count_val is a constant, a positive integer, and must be at least 2 and less than 2147483648. count_val represents the maximum number of data rows in each COUNT_WINDOW. If the total number of data rows cannot be evenly divided by count_val, the last window will have fewer rows than count_val. sliding_val is a constant, representing the number of rows the window slides, similar to the SLIDING in INTERVAL.
The definition of a window is exactly the same as in the time-series data window query, for details refer to the TDengine window functions section.
The following SQL will create a stream computation. After execution, TDengine will automatically create a supertable named avg_vol. This stream computation uses a 1min time window and a 30s forward increment to calculate the average voltage of these smart meters, and writes the results from the meters data into avg_vol. Data from different partitions will be written into separate subtables.
CREATE STREAM avg_vol_s INTO avg_vol AS
SELECT _wstart, count(*), avg(voltage) FROM power.meters PARTITION BY tbname INTERVAL(1m) SLIDING(30s);
The explanations of the relevant parameters involved in this section are as follows.
- stb_name is the table name of the supertable where the computation results are saved. If this supertable does not exist, it will be automatically created; if it already exists, the column schema information will be checked. See section 6.3.8.
- The tags clause defines the rules for creating tags in the stream computation. Through the tags field, custom tag values can be generated for each partition's corresponding subtable.
Rules and Strategies for Stream Computation
Partitioning in Stream Computation
In TDengine, we can use the partition by clause combined with tbname, tag columns, ordinary columns, or expressions to perform multi-partition computations on a stream. Each partition has its own timeline and time window, and they will aggregate data separately and write the results into different subtables of the destination table. If the partition by clause is not used, all data will be written into the same subtable by default.
Specifically, partition by + tbname is a very practical operation, which means performing stream computation for each subtable. The advantage of this is that it allows for customized processing based on the characteristics of each subtable, thereby improving computational efficiency.
When creating a stream, if the substable clause is not used, the supertable created by the stream computation will contain a unique tag column groupId. Each partition will be assigned a unique groupId, and the corresponding subtable name will be calculated using the MD5 algorithm. TDengine will automatically create these subtables to store the computation results of each partition. This mechanism makes data management more flexible and efficient, and also facilitates subsequent data querying and analysis.
If the statement for creating the stream contains a substable clause, users can generate custom table names for each partition's corresponding subtable. Example as follows.
CREATE STREAM avg_vol_s INTO avg_vol SUBTABLE(CONCAT('new-', tname)) AS SELECT _wstart, count(*), avg(voltage) FROM meters PARTITION BY tbname tname INTERVAL(1m);
In the PARTITION clause, an alias tname is defined for tbname, and the alias in the PARTITION clause can be used for expression calculation in the SUBTABLE clause. In the example above, the rule for newly created subtables is new- + subtable name + _supertable name +_groupId.
Note: If the length of the subtable name exceeds the limit of TDengine, it will be truncated. If the subtable name to be generated already exists in another supertable, since TDengine's subtable names are unique, the creation of the corresponding new subtable and the writing of data will fail.
Stream Computation Processing Historical Data
Under normal circumstances, stream computation tasks will not process data that was written to the source table before the stream was created. This is because the trigger for stream computation is based on newly written data, not existing data. However, if we need to process these existing historical data, we can set the fill_history option to 1 when creating the stream.
By enabling the fill_history option, the created stream computation task will be capable of processing data written before, during, and after the creation of the stream. This means that data written either before or after the creation of the stream will be included in the scope of stream computation, thus ensuring data integrity and consistency. This setting provides users with greater flexibility, allowing them to flexibly handle historical and new data according to actual needs.
Tips:
-
When enabling fill_history, creating a stream requires finding the boundary point of historical data. If there is a lot of historical data, it may cause the task of creating a stream to take a long time. In this case, you can use fill_history 1 async (supported since version 3.3.6.0) , then the task of creating a stream can be processed in the background. The statement of creating a stream can be returned immediately without blocking subsequent operations. async only takes effect when fill_history 1 is used, and creating a stream with fill_history 0 is very fast and does not require asynchronous processing.
-
Show streams can be used to view the progress of background stream creation (ready status indicates success, init status indicates stream creation in progress, failed status indicates that the stream creation has failed, and the message column can be used to view the reason for the failure. In the case of failed stream creation, the stream can be deleted and rebuilt).
-
Besides, do not create multiple streams asynchronously at the same time, as transaction conflicts may cause subsequent streams to fail.
For example, create a stream to count the number of data entries generated by all smart meters every 10s, and also calculate historical data. SQL as follows:
create stream if not exists count_history_s fill_history 1 into count_history as select count(*) from power.meters interval(10s)
Combined with the fill_history 1 option, it is possible to process data only within a specific historical time range, such as data after a historical moment (January 30, 2020).
create stream if not exists count_history_s fill_history 1 into count_history as select count(*) from power.meters where ts > '2020-01-30' interval(10s)
For instance, to process data within a specific time period, the end time can be a future date.
create stream if not exists count_history_s fill_history 1 into count_history as select count(*) from power.meters where ts > '2020-01-30' and ts < '2023-01-01' interval(10s)
If the stream task has completely expired and you no longer want it to monitor or process data, you can manually delete it, and the computed data will still be retained.
Trigger Modes for Stream Computing
When creating a stream, you can specify the trigger mode of stream computing through the TRIGGER command. For non-window computations, the trigger is real-time; for window computations, there are currently 4 trigger modes, with WINDOW_CLOSE as the default.
-
AT_ONCE: Triggered immediately upon writing.
-
WINDOW_CLOSE: Triggered when the window closes (the closing of the window is determined by the event time, can be used in conjunction with watermark).
-
MAX_DELAY time: If the window closes, computation is triggered. If the window has not closed, and the duration since it has not closed exceeds the time specified by max delay, computation is triggered.
-
FORCE_WINDOW_CLOSE: Based on the current time of the operating system, only the results of the currently closed window are calculated and pushed out. The window is only calculated once at the moment of closure, and will not be recalculated subsequently. This mode currently only supports INTERVAL windows (does support sliding); In this mode, FILL_HISTORY is automatically set to 0, IGNORE EXPIRED is automatically set to 1 and IGNORE UPDATE is automatically set to 1; FILL only supports PREV, NULL, NONE, VALUE.
- This mode can be used to implement continuous queries, such as creating a stream that queries the number of data entries in the past 10 seconds window every 1 second. SQL as follows:
create stream if not exists continuous_query_s trigger force_window_close into continuous_query as select count(*) from power.meters interval(10s) sliding(1s) -
CONTINUOUS_WINDOW_CLOSE: Results are output when the window is closed. Modifying or deleting data does not immediately trigger a recalculation. Instead, periodic recalculations are performed every rec_time_val duration. If rec_time_val is not specified, the recalculation period is 60 minutes. If the recalculation time exceeds rec_time_val, the next recalculation will be automatically initiated after the current one is completed. Currently, this mode only supports INTERVAL windows. If the FILL clause is used, relevant information of the adapter needs to be configured, including adapterFqdn, adapterPort, and adapterToken. The adapterToken is a string obtained by Base64-encoding
{username}:{password}. For example, after encodingroot:taosdata, the result iscm9vdDp0YW9zZGF0YQ==. The closing of the window is determined by the event time, such as when the event stream is interrupted or continuously delayed, at which point the event time cannot be updated, possibly leading to outdated computation results.
Therefore, stream computing provides the MAX_DELAY trigger mode that combines event time with processing time: MAX_DELAY mode triggers computation immediately when the window closes, and its unit can be specified, specific units: a (milliseconds), s (seconds), m (minutes), h (hours), d (days), w (weeks). Additionally, when data is written, if the time that triggers computation exceeds the time specified by MAX_DELAY, computation is triggered immediately.
Window Closure in Stream Computing
The core of stream computing lies in using the event time (i.e., the timestamp primary key in the written record) as the basis for calculating the window closure time, rather than relying on the TDengine server's time. Using event time as the basis effectively avoids issues caused by discrepancies between client and server times and can properly address challenges such as out-of-order data writing.
To further control the tolerance level for out-of-order data, stream computing introduces the watermark mechanism. When creating a stream, users can specify the value of watermark through the stream_option parameter, which defines the upper bound of tolerance for out-of-order data, defaulting to 0.
Assuming T = Latest event time - watermark, each time new data is written, the system updates the window closure time based on this formula. Specifically, the system closes all open windows whose end time is less than T. If the trigger mode is set to window_close or max_delay, the aggregated results of the window are pushed. The diagram below illustrates the window closure process in stream computing.
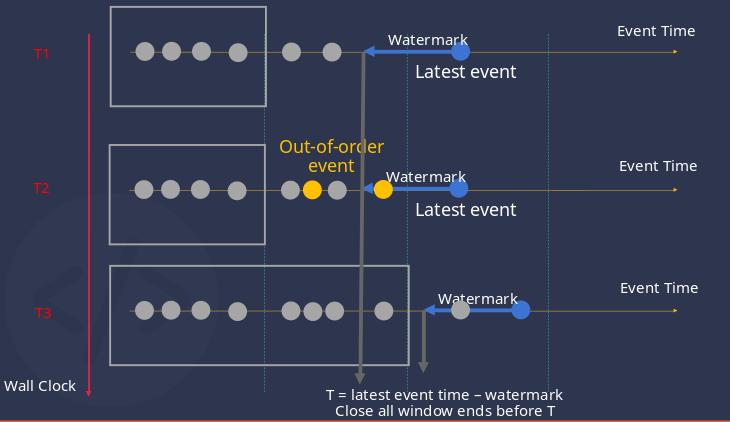
In the diagram above, the vertical axis represents moments, and the dots on the horizontal axis represent the data received. The related process is described as follows.
- At moment T1, the 7th data point arrives, and based on T = Latest event - watermark, the calculated time falls within the second window, so the second window does not close.
- At moment T2, the 6th and 8th data points arrive late to TDengine, and since the Latest event has not changed, T also remains unchanged, and the out-of-order data entering the second window has not yet been closed, thus it can be correctly processed.
- At moment T3, the 10th data point arrives, T moves forward beyond the closure time of the second window, which is then closed, and the out-of-order data is correctly processed.
In window_close or max_delay modes, window closure directly affects the push results. In at_once mode, window closure only relates to memory usage.
Expired Data Handling Strategy
For windows that have closed, data that falls into such windows again is marked as expired data. TDengine offers two ways to handle expired data, specified by the IGNORE EXPIRED option.
- Recalculate, i.e., IGNORE EXPIRED 0: Re-find all data corresponding to the window from the TSDB and recalculate to get the latest result.
- Directly discard, i.e., IGNORE EXPIRED 1: Default configuration, ignore expired data.
Regardless of the mode, the watermark should be properly set to obtain correct results (direct discard mode) or avoid frequent re-triggering of recalculations that lead to performance overhead (recalculation mode).
Data Update Handling Strategy
TDengine offers two ways to handle modified data, specified by the IGNORE UPDATE option.
- Check whether the data has been modified, i.e., IGNORE UPDATE 0: Default configuration, if modified, recalculate the corresponding window.
- Do not check whether the data has been modified, calculate all as incremental data, i.e., IGNORE UPDATE 1.
Other Strategies for Stream Computing
Writing to an Existing Supertable
When the result of stream computing needs to be written into an existing supertable, ensure that the stb_name column corresponds correctly with the subquery output results. If the position and number of the stb_name column match exactly with the subquery output results, there is no need to explicitly specify the correspondence; if the data types do not match, the system will automatically convert the subquery output results to the corresponding stb_name column type.
For already existing supertables, the system will check the schema information of the columns to ensure they match the subquery output results. Here are some key points:
- Check if the schema information of the columns matches; if not, automatically perform type conversion. Currently, an error is reported only if the data length exceeds 4096 bytes; otherwise, type conversion can be performed.
- Check if the number of columns is the same; if different, explicitly specify the correspondence between the supertable and the subquery columns, otherwise, an error is reported. If the same, you can specify the correspondence or not; if not specified, they correspond by position order.
Note Although stream computing can write results to an existing supertable, it cannot allow two existing stream computations to write result data to the same (super) table. This is to avoid data conflicts and inconsistencies, ensuring data integrity and accuracy. In practice, set the column correspondence according to actual needs and data structure to achieve efficient and accurate data processing.
Customizing Tags for Target Tables
Users can generate custom tag values for each partition's subtable, as shown in the stream creation statement below:
CREATE STREAM output_tag trigger at_once INTO output_tag_s TAGS(alias_tag varchar(100)) as select _wstart, count(*) from power.meters partition by concat("tag-", tbname) as alias_tag interval(10s));
In the PARTITION clause, an alias alias_tag is defined for concat("tag-", tbname), corresponding to the custom tag name of the supertable output_tag_s. In the example above, the tag of the newly created subtable by the stream will use the prefix 'tag-' connected to the original table name as the tag value. The following checks will be performed on the tag information:
- Check if the schema information of the tag matches; if not, automatically perform data type conversion. Currently, an error is reported only if the data length exceeds 4096 bytes; otherwise, type conversion can be performed.
- Check if the number of tags is the same; if different, explicitly specify the correspondence between the supertable and the subquery tags, otherwise, an error is reported. If the same, you can specify the correspondence or not; if not specified, they correspond by position order.
Cleaning Up Intermediate States of Stream Computing
DELETE_MARK time
DELETE_MARK is used to delete cached window states, i.e., deleting the intermediate results of stream computing. Cached window states are mainly used for window result updates caused by expired data. If not set, the default value is 10 years.
Specific Operations of Stream Computing
Deleting Stream Computing
Only deletes the stream computing task; data written by stream computing will not be deleted, SQL as follows:
DROP STREAM [IF EXISTS] stream_name;
Displaying Stream Computing
View the SQL of stream computing tasks as follows:
SHOW STREAMS;
To display more detailed information, you can use:
SELECT * from information_schema.`ins_streams`;
Pausing Stream Computing Tasks
The SQL to pause stream computing tasks is as follows:
PAUSE STREAM [IF EXISTS] stream_name;
If IF EXISTS is not specified, an error is reported if the stream does not exist. If it exists, the stream computing is paused. If IF EXISTS is specified, it returns success if the stream does not exist. If it exists, the stream computing is paused.
Resuming Stream Computing Tasks
The SQL to resume stream computing tasks is as follows. If IGNORE UNTREATED is specified, it ignores the data written during the pause period of the stream computing task when resuming.
RESUME STREAM [IF EXISTS] [IGNORE UNTREATED] stream_name;
If IF EXISTS is not specified, an error is reported if the stream does not exist. If it exists, the stream computing is resumed. If IF EXISTS is specified, it returns success if the stream does not exist. If it exists, the stream computing is resumed. If IGNORE UNTREATED is specified, it ignores the data written during the pause period of the stream computing task when resuming.
Stream Computing Upgrade Fault Recovery
After upgrading TDengine, if the stream computing is not compatible, you need to delete the stream computing and then recreate it. The steps are as follows:
-
Modify taos.cfg, add
disableStream 1 -
Restart taosd. If the startup fails, change the name of the stream directory to avoid taosd trying to load the stream computing data information during startup. Avoid using the delete operation to prevent risks caused by misoperations. The folders that need to be modified:
$dataDir/vnode/vnode*/tq/stream, where$dataDirrefers to the directory where TDengine stores data. In the$dataDir/vnode/directory, there will be multiple directories like vnode1, vnode2...vnode*, all need to change the name of the tq/stream directory to tq/stream.bk -
Start taos
drop stream xxxx; ---- xxx refers to the stream name
flush database stream_source_db; ---- The database where the supertable for stream computing data reading is located
flush database stream_dest_db; ---- The database where the supertable for stream computing data writing is located
Example:
create stream streams1 into test1.streamst as select _wstart, count(a) c1 from test.st interval(1s) ;
drop stream streams1;
flush database test;
flush database test1;
-
Close taosd
-
Modify taos.cfg, remove
disableStream 1, or changedisableStreamto 0 -
Start taosd


