Data Connectors
The features or components discussed in this document are available in TDengine TSDB-Enterprise only. TDengine TSDB-OSS does not include these features or components.
Overview
TDengine Enterprise is equipped with a powerful visual data management tool—taosExplorer. With taosExplorer, users can easily submit tasks to TDengine through simple configurations in the browser, achieving seamless data import from various data sources into TDengine with zero coding. During the import process, TDengine automatically extracts, filters, and transforms the data to ensure the quality of the imported data. Through this zero-code data source integration method, TDengine has successfully transformed into an outstanding platform for aggregating time-series big data. Users do not need to deploy additional ETL tools, thereby greatly simplifying the overall architecture design and improving data processing efficiency.
The diagram below shows the system architecture of the zero-code integration platform.
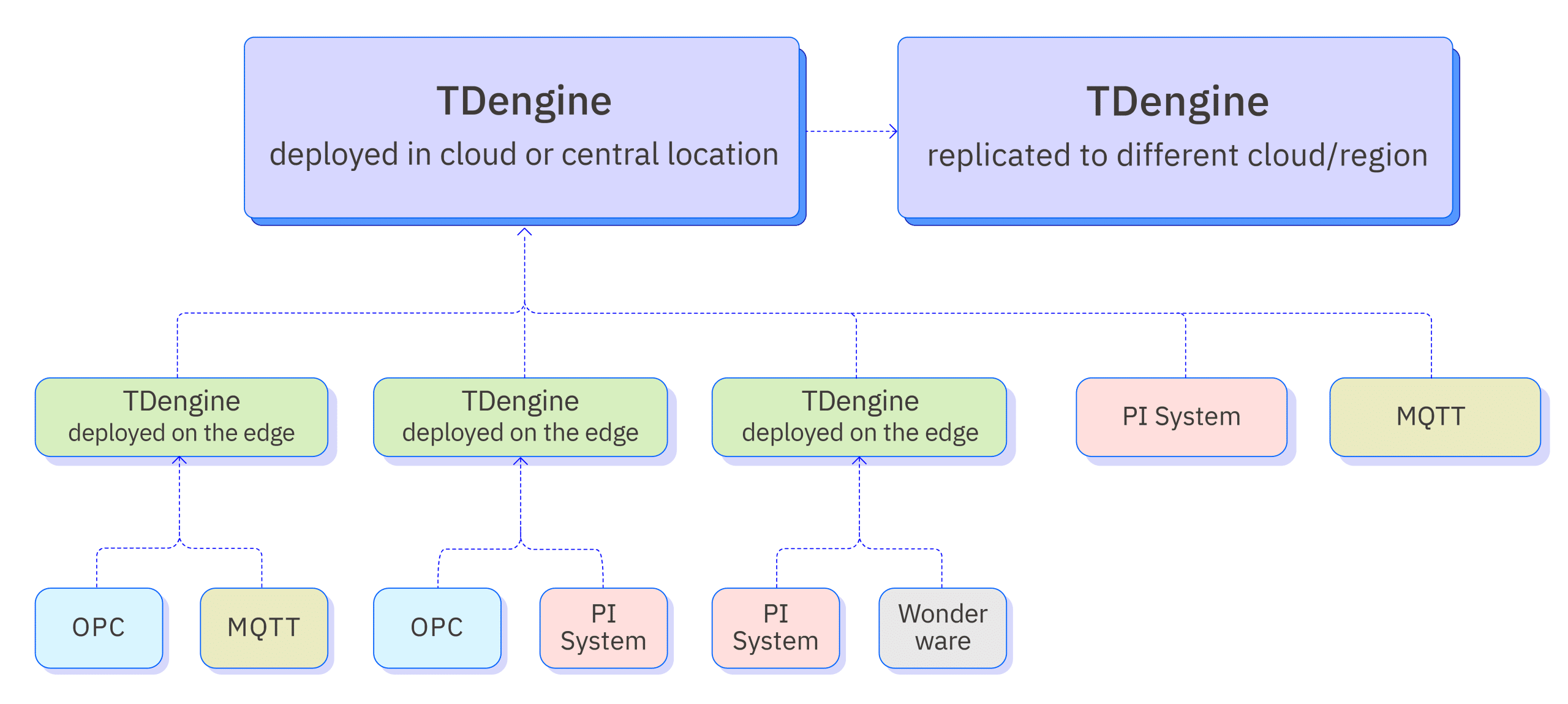
Supported Data Sources
The data sources currently supported by TDengine are as follows:
| Data Source | Supported Version | Description |
|---|---|---|
| Aveva PI System | PI AF Server Version 2.10.9.593 or above | An industrial data management and analytics platform, formerly known as OSIsoft PI System, capable of real-time collection, integration, analysis, and visualization of industrial data, helping enterprises achieve intelligent decision-making and refined management |
| Aveva Historian | AVEVA Historian 2020 RS SP1 | Industrial big data analytics software, formerly known as Wonderware Historian, designed for industrial environments to store, manage, and analyze real-time and historical data from various industrial devices and sensors |
| OPC DA | Matrikon OPC version: 1.7.2.7433 | Abbreviation for Open Platform Communications, an open, standardized communication protocol for data exchange between automation devices from different manufacturers. Initially developed by Microsoft, it was aimed at addressing interoperability issues in the industrial control field; the OPC protocol was first released in 1996, then known as OPC DA (Data Access), mainly for real-time data collection and control. |
| OPC UA | KeepWare KEPServerEx 6.5 | In 2006, the OPC Foundation released the OPC UA (Unified Architecture) standard, a service-oriented, object-oriented protocol with higher flexibility and scalability, which has become the mainstream version of the OPC protocol |
| MQTT | emqx: 3.0.0 to 5.7.1 hivemq: 4.0.0 to 4.31.0 mosquitto: 1.4.4 to 2.0.18 | Abbreviation for Message Queuing Telemetry Transport, a lightweight communication protocol based on the publish/subscribe pattern, designed for low overhead, low bandwidth usage instant messaging, widely applicable in IoT, small devices, mobile applications, and other fields. |
| Kafka | 2.11 ~ 3.8.0 | An open-source stream processing platform developed by the Apache Software Foundation, primarily used for processing real-time data and providing a unified, high-throughput, low-latency messaging system. It features high speed, scalability, persistence, and a distributed design, enabling it to handle hundreds of thousands of read/write operations per second, support thousands of clients, while maintaining data reliability and availability. |
| InfluxDB | 1.7, 1.8, 2.0-2.7 | A popular open-source time-series database optimized for handling large volumes of time-series data. |
| OpenTSDB | 2.4.1 | A distributed, scalable time-series database based on HBase. It is primarily used for storing, indexing, and providing access to metric data collected from large-scale clusters (including network devices, operating systems, applications, etc.), making this data more accessible and graphically presentable. |
| MySQL | 5.6,5.7,8.0+ | One of the most popular relational database management systems, known for its small size, fast speed, low overall ownership cost, and particularly its open-source nature, making it the choice for website database development for both medium-sized and large websites. |
| Oracle | 11G/12c/19c | Oracle Database System is one of the world's popular relational database management systems, known for its good portability, ease of use, powerful features, suitable for various large, medium, and small computer environments. It is an efficient, reliable, and high-throughput database solution. |
| PostgreSQL | v15.0+ | PostgreSQL is a very powerful open-source client/server relational database management system, with many features found in large commercial RDBMS, including transactions, sub-selects, triggers, views, foreign key referential integrity, and complex locking capabilities. |
| SQL Server | 2012/2022 | Microsoft SQL Server is a relational database management system developed by Microsoft, known for its ease of use, good scalability, and high integration with related software. |
| MongoDB | 3.6+ | MongoDB is a product between relational and non-relational databases, widely used in content management systems, mobile applications, and the Internet of Things, among many other fields. |
| CSV | - | Abbreviation for Comma Separated Values, a plain text file format separated by commas, commonly used in spreadsheet or database software. |
| TDengine Query | 2.4+, 3.0+ | Query from older version of TDengine and write into new cluster. |
| TDengine Data Subscription | 3.0+ | Use TMQ for subscribing to specified databases or supertables from TDengine. |
Data Extraction, Filtering, and Transformation
Since there can be multiple data sources, each data source may have different physical units, naming conventions, and time zones. To address this issue, TDengine has built-in ETL capabilities that can parse and extract the required data from the data packets of data sources, and perform filtering and transformation to ensure the quality of the data written and provide a unified namespace. The specific functions are as follows:
- Parsing: Use JSON Path or regular expressions to parse fields from the original message.
- Extracting or splitting from columns: Use split or regular expressions to extract multiple fields from an original field.
- Filtering: Messages are only written to TDengine if the expression's value is true.
- Transformation: Establish conversion and mapping relationships between parsed fields and TDengine supertable fields.
Below is a detailed explanation of the data transformation rules.
Parsing
Only unstructured data sources need this step. Currently, MQTT and Kafka data sources use the rules provided in this step to parse unstructured data to preliminarily obtain structured data, i.e., row and column data that can be described by fields. In the explorer, you need to provide sample data and parsing rules to preview the parsed structured data presented in a table.
Sample Data
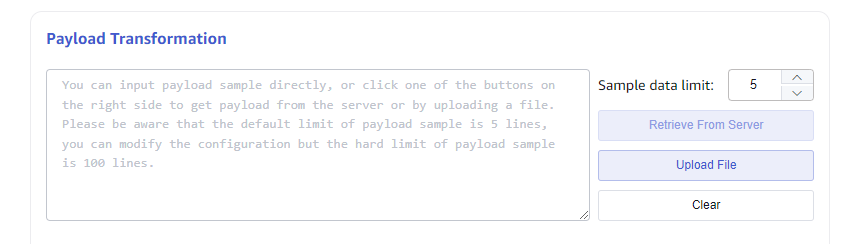
As shown in the image, the textarea input box contains the sample data, which can be obtained in three ways:
- Directly enter the sample data in the textarea;
- Click the button on the right "Retrieve from Server" to get the sample data from the configured server and append it to the sample data textarea;
- Upload a file, appending the file content to the sample data textarea.
Each piece of sample data ends with a carriage return.
Parsing
Parsing is the process of parsing unstructured strings into structured data. The message body's parsing rules currently support JSON, Regex, and UDT.
JSON Parsing
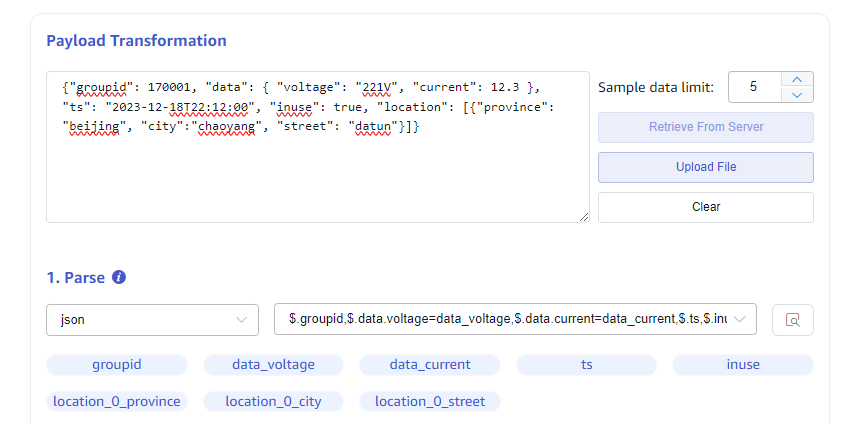
JSON parsing supports JSONObject or JSONArray. The following JSON sample data can automatically parse fields: groupid, voltage, current, ts, inuse, location.
{"groupid": 170001, "voltage": "221V", "current": 12.3, "ts": "2023-12-18T22:12:00", "inuse": true, "location": "beijing.chaoyang.datun"}
{"groupid": 170001, "voltage": "220V", "current": 12.2, "ts": "2023-12-18T22:12:02", "inuse": true, "location": "beijing.chaoyang.datun"}
{"groupid": 170001, "voltage": "216V", "current": 12.5, "ts": "2023-12-18T22:12:04", "inuse": false, "location": "beijing.chaoyang.datun"}
Or
[{"groupid": 170001, "voltage": "221V", "current": 12.3, "ts": "2023-12-18T22:12:00", "inuse": true, "location": "beijing.chaoyang.datun"},
{"groupid": 170001, "voltage": "220V", "current": 12.2, "ts": "2023-12-18T22:12:02", "inuse": true, "location": "beijing.chaoyang.datun"},
{"groupid": 170001, "voltage": "216V", "current": 12.5, "ts": "2023-12-18T22:12:04", "inuse": false, "location": "beijing.chaoyang.datun"}]
Subsequent examples will only explain using JSONObject.
The following nested JSON data can automatically parse fields groupid, data_voltage, data_current, ts, inuse, location_0_province, location_0_city, location_0_datun, and you can also choose which fields to parse and set aliases for the parsed fields.
{"groupid": 170001, "data": { "voltage": "221V", "current": 12.3 }, "ts": "2023-12-18T22:12:00", "inuse": true, "location": [{"province": "beijing", "city":"chaoyang", "street": "datun"}]}
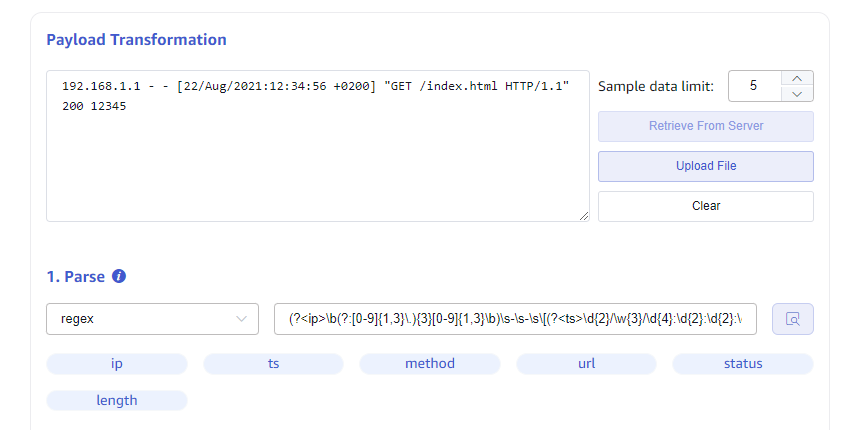
Regex Regular Expressions
You can use named capture groups in regular expressions to extract multiple fields from any string (text) field. As shown in the figure, extract fields such as access IP, timestamp, and accessed URL from nginx logs.
(?<ip>\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b)\s-\s-\s\[(?<ts>\d{2}/\w{3}/\d{4}:\d{2}:\d{2}:\d{2}\s\+\d{4})\]\s"(?<method>[A-Z]+)\s(?<url>[^\s"]+).*(?<status>\d{3})\s(?<length>\d+)
UDT Custom Parsing Scripts
Custom rhai syntax scripts for parsing input data (refer to https://rhai.rs/book/), the script currently only supports json format raw data.
Input: In the script, you can use the parameter data, which is the Object Map after the raw data is parsed from json;
Output: The output data must be an array.
For example, for data reporting three-phase voltage values, which are entered into three subtables respectively, such data needs to be parsed
{
"ts": "2024-06-27 18:00:00",
"voltage": "220.1,220.3,221.1",
"dev_id": "8208891"
}
Then you can use the following script to extract the three voltage data.
let v3 = data["voltage"].split(",");
[
#{"ts": data["ts"], "val": v3[0], "dev_id": data["dev_id"]},
#{"ts": data["ts"], "val": v3[1], "dev_id": data["dev_id"]},
#{"ts": data["ts"], "val": v3[2], "dev_id": data["dev_id"]}
]
The final parsing result is shown below:
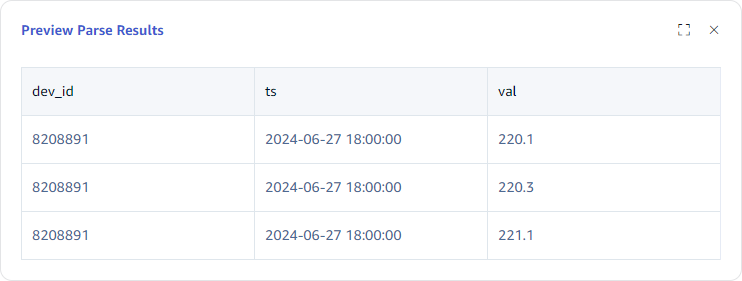
Extraction or Splitting
The parsed data may still not meet the data requirements of the target table. For example, the original data collected by a smart meter is as follows (in json format):
{"groupid": 170001, "voltage": "221V", "current": 12.3, "ts": "2023-12-18T22:12:00", "inuse": true, "location": "beijing.chaoyang.datun"}
{"groupid": 170001, "voltage": "220V", "current": 12.2, "ts": "2023-12-18T22:12:02", "inuse": true, "location": "beijing.chaoyang.datun"}
{"groupid": 170001, "voltage": "216V", "current": 12.5, "ts": "2023-12-18T22:12:04", "inuse": false, "location": "beijing.chaoyang.datun"}
Using json rules, the voltage is parsed as a string with units, and it is desired to use int type to record voltage and current values for statistical analysis, so further splitting of the voltage is needed; additionally, the date is expected to be split into date and time for storage.
As shown in the figure below, you can use the split rule on the source field ts to split it into date and time, and use regex to extract the voltage value and unit from the field voltage. The split rule needs to set delimiter and number of splits, and the naming rule for the split fields is {original field name}_{sequence number}. The Regex rule is the same as in the parsing process, using named capture groups to name the extracted fields.
Filtering
The filtering feature can set filtering conditions, and only data rows that meet the conditions will be written to the target table. The result of the filter condition expression must be of boolean type. Before writing filter conditions, it is necessary to determine the type of parsed fields, and based on the type of parsed fields, judgment functions and comparison operators (>, >=, <=, <, ==, !=) can be used to judge.
Field Types and Conversion
Only by clearly parsing the type of each field can you use the correct syntax for data filtering.
Fields parsed using the json rule are automatically set to types based on their attribute values:
- bool type:
"inuse": true - int type:
"voltage": 220 - float type:
"current" : 12.2 - String type:
"location": "MX001"
Data parsed using regex rules are all string types. Data extracted or split using split and regex are string types.
If the extracted data type is not the expected type, data type conversion can be performed. A common data type conversion is converting a string to a numeric type. Supported conversion functions are as follows:
| Function | From type | To type | e.g. |
|---|---|---|---|
| parse_int | string | int | parse_int("56") // Results in integer 56 |
| parse_float | string | float | parse_float("12.3") // Results in float 12.3 |
Conditional Expressions
Different data types have their own ways of writing conditional expressions.
BOOL type
You can use variables or the ! operator, for example for the field "inuse": true, you can write the following expressions:
- inuse
- !inuse
Numeric types (int/float)
Numeric types support comparison operators ==, !=, >, >=, <, <=.
String type
Use comparison operators to compare strings.
String functions
| Function | Description | e.g. |
|---|---|---|
| is_empty | returns true if the string is empty | s.is_empty() |
| contains | checks if a certain character or sub-string occurs in the string | s.contains("substring") |
| starts_with | returns true if the string starts with a certain string | s.starts_with("prefix") |
| ends_with | returns true if the string ends with a certain string | s.ends_with("suffix") |
| len | returns the number of characters (not number of bytes) in the string, must be used with comparison operator | s.len == 5 to check if the string length is 5; len as a property returns int, different from the first four functions which directly return bool. |
Compound Expressions
Multiple conditional expressions can be combined using logical operators (&&, ||, !). For example, the following expression represents fetching data from smart meters installed in Beijing with a voltage value greater than 200.
location.starts_with("beijing") && voltage > 200
Mapping
Mapping is mapping the source field parsed, extracted, or split to the target table field. It can be directly mapped, or it can be mapped to the target table after some rule calculations.
Selecting the target supertable
After selecting the target supertable, all tags and columns of the supertable will be loaded. The source field is automatically mapped to the tag and column of the target supertable using the mapping rule based on the name. For example, the following parsed, extracted, or split preview data:
Mapping Rules
The supported mapping rules are shown in the following table:
| rule | description |
|---|---|
| mapping | Direct mapping, need to select the mapping source field. |
| value | Constant, can enter string constants or numeric constants, the entered constant value is directly stored. |
| generator | Generator, currently only supports the timestamp generator now, which stores the current time when storing. |
| join | String connector, can specify connecting characters to concatenate selected multiple source fields. |
| format | String formatting tool, fill in the formatting string, for example, if there are three source fields year, month, day representing year, month, and day, and you wish to store them in the yyyy-MM-dd date format, you can provide a formatting string as ${year}-${month}-${day}. Where ${} acts as a placeholder, the placeholder can be a source field or a string type field function handling |
| sum | Select multiple numeric fields for addition calculation. |
| expr | Numeric operation expression, can perform more complex function processing and mathematical operations on numeric fields. |
Supported string processing functions in format
| Function | description | e.g. |
|---|---|---|
| pad(len, pad_chars) | pads the string with a character or a string to at least a specified length | "1.2".pad(5, '0') // Result is "1.200" |
| trim | trims the string of whitespace at the beginning and end | " abc ee ".trim() // Result is "abc ee" |
| sub_string(start_pos, len) | extracts a sub-string, two parameters: 1. start position, counting from end if < 0 2. (optional) number of characters to extract, none if ≤ 0, to end if omitted | "012345678".sub_string(5) // "5678" "012345678".sub_string(5, 2) // "56" "012345678".sub_string(-2) // "78" |
| replace(substring, replacement) | replaces a sub-string with another | "012345678".replace("012", "abc") // "abc345678" |
Mathematical expressions in expr
Basic mathematical operations support addition +, subtraction -, multiplication *, and division /.
For example, if the data source collects temperature values in Celsius and the target database stores values in Fahrenheit, then the collected temperature data needs to be converted.
If the source field is temperature, then use the expression temperature * 1.8 + 32.
Mathematical expressions also support the use of mathematical functions, as shown in the table below:
| Function | description | e.g. |
|---|---|---|
| sin, cos, tan, sinh, cosh | Trigonometry | a.sin() |
| asin, acos, atan, asinh, acosh | arc-trigonometry | a.asin() |
| sqrt | Square root | a.sqrt() // 4.sqrt() == 2 |
| exp | Exponential | a.exp() |
| ln, log | Logarithmic | a.ln() // e.ln() == 1 a.log() // 10.log() == 1 |
| floor, ceiling, round, int, fraction | rounding | a.floor() // (4.2).floor() == 4 a.ceiling() // (4.2).ceiling() == 5 a.round() // (4.2).round() == 4 a.int() // (4.2).int() == 4 a.fraction() // (4.2).fraction() == 0.2 |
Subtable name mapping
Subtable names are strings and can be defined using the string formatting format expression in the mapping rules.
Creating a Task
Below, using MQTT data source as an example, we explain how to create a task of MQTT type, consume data from MQTT Broker, and write into TDengine.
- After logging into taosExplorer, click on "Data Writing" on the left navigation bar to enter the task list page.
- On the task list page, click "+ Add Data Source" to enter the task creation page.
- After entering the task name, select the type as MQTT, then you can create a new proxy or select an already created proxy.
- Enter the IP address and port number of the MQTT broker, for example: 192.168.1.100:1883
- Configure authentication and SSL encryption:
- If the MQTT broker has enabled user authentication, enter the username and password of the MQTT broker in the authentication section;
- If the MQTT broker has enabled SSL encryption, you can turn on the SSL certificate switch on the page and upload the CA's certificate, as well as the client's certificate and private key files;
- In the "Collection Configuration" section, you can select the version of the MQTT protocol, currently supporting 3.1, 3.1.1, 5.0; when configuring the Client ID, be aware that if multiple tasks are created for the same MQTT broker, the Client IDs should be different to avoid conflicts, which could cause the tasks to not run properly; when configuring the topic and QoS, use the format
<topic name>::<QoS>, where the QoS values range from 0, 1, 2, representing at most once, at least once, exactly once; after configuring the above information, you can click the "Check Connectivity" button to check the configurations, if the connectivity check fails, please modify according to the specific error tips returned on the page; - During the process of syncing data from the MQTT broker, taosX also supports extracting, filtering, and mapping operations on the fields in the message body. In the text box under "Payload Transformation", you can directly input a sample of the message body, or import it by uploading a file, and in the future, it will also support retrieving sample messages directly from the configured server;
- For extracting fields from the message body, currently, two methods are supported: JSON and regular expressions. For simple key/value formatted JSON data, you can directly click the extract button to display the parsed field names; for complex JSON data, you can use JSON Path to extract the fields of interest; when using regular expressions to extract fields, ensure the correctness of the regular expressions;
- After the fields in the message body are parsed, you can set filtering rules based on the parsed field names, and only data that meets the filtering rules will be written into TDengine, otherwise, the message will be ignored; for example, you can configure a filtering rule as voltage > 200, meaning only data with a voltage greater than 200V will be synced to TDengine;
- Finally, after configuring the mapping rules between the fields in the message body and the fields in the supertable, you can submit the task; in addition to basic mapping, here you can also convert the values of the fields in the message, for example, you can use the expression (expr) to calculate the power from the original message body's voltage and current before writing it into TDengine;
- After submitting the task, it will automatically return to the task list page, if the submission is successful, the status of the task will switch to "Running", if the submission fails, you can check the activity log of the task to find the error reason;
- For tasks that are running, clicking the view button of the metrics allows you to view the detailed running metrics of the task, the popup window is divided into 2 tabs, displaying the cumulative metrics of the task's multiple runs and the metrics of this run, these metrics are automatically refreshed every 2 seconds.
Task Management
On the task list page, you can also start, stop, view, delete, copy, and other operations on tasks. You can also view the running status of each task, including the number of records written, traffic, etc.
📄️ TDengine Query
This section describes how to create a data migration task through the Explorer interface to migrate data from the old version of TDengine(2.4+, 3.0+) to the current cluster.
📄️ TDengine Subscription
This document describes how to use Explorer to subscribe to data from another cluster to this cluster.
📄️ PI System
This section describes how to create data migration tasks through the Explorer interface, migrating data from the PI system to the current TDengine cluster.
📄️ OPC UA
This section describes how to create data migration tasks through the Explorer interface to synchronize data from an OPC-UA server to the current TDengine cluster.
📄️ OPC DA
This section describes how to create data migration tasks through the Explorer interface, synchronizing data from an OPC-DA server to the current TDengine cluster.
📄️ MQTT
This section describes how to create data migration tasks through the Explorer interface, migrating data from MQTT to the current TDengine cluster.
📄️ Kafka
This section describes how to create data migration tasks through the Explorer interface, migrating data from Kafka to the current TDengine cluster.
📄️ InfluxDB
This section describes how to create a data migration task through the Explorer interface to migrate data from InfluxDB to the current TDengine cluster.
📄️ OpenTSDB
This section describes how to create a data migration task through the Explorer interface to migrate data from OpenTSDB to the current TDengine cluster.
📄️ CSV File
This section describes how to create data migration tasks through the Explorer interface, migrating data from CSV to the current TDengine cluster.
📄️ AVEVA Historian
This section describes how to create data migration/data synchronization tasks through the Explorer interface, migrating/synchronizing data from AVEVA Historian to the current TDengine cluster.
📄️ MySQL
This section describes how to create data migration tasks through the Explorer interface, migrating data from MySQL to the current TDengine cluster.
📄️ PostgreSQL
This section describes how to create a data migration task through the Explorer interface to migrate data from PostgreSql to the current TDengine cluster.
📄️ Oracle Database
This section describes how to create data migration tasks through the Explorer interface, migrating data from Oracle to the current TDengine cluster.
📄️ SQL Server
This section describes how to create data migration tasks through the Explorer interface, migrating data from Microsoft SQL Server(2016+ or with TLS1.2+ support) to the current TDengine cluster.
📄️ MongoDB
This section describes how to create data migration tasks through the Explorer interface, migrating data from MongoDB to the current TDengine cluster.
📄️ KingHistorian
This section describes how to create data migration/data synchronization tasks through the Explorer interface to migrate/synchronize data from KingHistorian to the current TDengine TSDB cluster.
📄️ Pulsar
This section describes how to create a data migration task through the Explorer interface to migrate data from Pulsar to the current TDengine TSDB cluster.
📄️ Pulsar-Tuya
This section describes how to create a data migration task through the Explorer interface to migrate data from Pulsar-Tuya cluster to the current TDengine TSDB cluster.
📄️ pSpace
This section describes how to create data migration/data synchronization tasks through the Explorer UI to migrate/synchronize data from pSpace to the current TDengine TSDB cluster.