Concepts
In order to explain the basic concepts and provide some sample code, the TDengine documentation smart meters as a typical time series use case. We assume the following: 1. Each smart meter collects three metrics i.e. current, voltage, and phase; 2. There are multiple smart meters; 3. Each meter has static attributes like location and group ID. Based on this, collected data will look similar to the following table:
| Device ID | Time Stamp | Collected Metrics | Tags | |||
|---|---|---|---|---|---|---|
| Device ID | Time Stamp | current | voltage | phase | location | groupId |
| d1001 | 1538548685000 | 10.3 | 219 | 0.31 | California.SanFrancisco | 2 |
| d1002 | 1538548684000 | 10.2 | 220 | 0.23 | California.SanFrancisco | 3 |
| d1003 | 1538548686500 | 11.5 | 221 | 0.35 | California.LosAngeles | 3 |
| d1004 | 1538548685500 | 13.4 | 223 | 0.29 | California.LosAngeles | 2 |
| d1001 | 1538548695000 | 12.6 | 218 | 0.33 | California.SanFrancisco | 2 |
| d1004 | 1538548696600 | 11.8 | 221 | 0.28 | California.LosAngeles | 2 |
| d1002 | 1538548696650 | 10.3 | 218 | 0.25 | California.SanFrancisco | 3 |
| d1001 | 1538548696800 | 12.3 | 221 | 0.31 | California.SanFrancisco | 2 |
Each row contains the device ID, time stamp, collected metrics (current, voltage, phase as above), and static tags (location and groupId in Table 1) associated with the devices. Each smart meter generates a row (measurement) in a pre-defined time interval or triggered by an external event. The device produces a sequence of measurements with associated time stamps.
Metric
Metric refers to the physical quantity collected by sensors, equipment or other types of data collection devices, such as current, voltage, temperature, pressure, GPS position, etc., which change with time, and the data type can be integer, float, Boolean, or strings. As time goes by, the amount of collected metric data stored increases. In the smart meters example, current, voltage and phase are the metrics.
Label/Tag
Label/Tag refers to the static properties of sensors, equipment or other types of data collection devices, which do not change with time, such as device model, color, fixed location of the device, etc. The data type can be any type. Although static, TDengine allows users to add, delete or update tag values at any time. Unlike the collected metric data, the amount of tag data stored does not change over time. In the meters example, location and groupid are the tags.
Data Collection Point
Data Collection Point (DCP) refers to hardware or software that collects metrics based on preset time periods or triggered by events. A data collection point can collect one or multiple metrics, but these metrics are collected at the same time and have the same time stamp. For some complex equipment, there are often multiple data collection points, and the sampling rate of each collection point may be different, and fully independent. For example, for a car, there could be a data collection point to collect GPS position metrics, a data collection point to collect engine status metrics, and a data collection point to collect the environment metrics inside the car. So in this example the car would have three data collection points. In the smart meters example, d1001, d1002, d1003, and d1004 are the data collection points.
Table
Since time-series data is most likely to be structured data, TDengine adopts the traditional relational database model to process them with a short learning curve. You need to create a database, create tables, then insert data points and execute queries to explore the data.
To make full use of time-series data characteristics, TDengine adopts a strategy of "One Table for One Data Collection Point". TDengine requires the user to create a table for each data collection point (DCP) to store collected time-series data. For example, if there are over 10 million smart meters, it means 10 million tables should be created. For the table above, 4 tables should be created for devices D1001, D1002, D1003, and D1004 to store the data collected. This design has several benefits:
- Since the metric data from different DCP are fully independent, the data source of each DCP is unique, and a table has only one writer. In this way, data points can be written in a lock-free manner, and the writing speed can be greatly improved.
- For a DCP, the metric data generated by DCP is ordered by timestamp, so the write operation can be implemented by simple appending, which further greatly improves the data writing speed.
- The metric data from a DCP is continuously stored, block by block. If you read data for a period of time, it can greatly reduce random read operations and improve read and query performance by orders of magnitude.
- Inside a data block for a DCP, columnar storage is used, and different compression algorithms are used for different data types. Metrics generally don't vary as significantly between themselves over a time range as compared to other metrics, which allows for a higher compression rate.
If the metric data of multiple DCPs are traditionally written into a single table, due to uncontrollable network delays, the timing of the data from different DCPs arriving at the server cannot be guaranteed, write operations must be protected by locks, and metric data from one DCP cannot be guaranteed to be continuously stored together. One table for one data collection point can ensure the best performance of insert and query of a single data collection point to the greatest possible extent.
TDengine suggests using DCP ID as the table name (like D1001 in the above table). Each DCP may collect one or multiple metrics (like the current, voltage, phase as above). Each metric has a corresponding column in the table. The data type for a column can be int, float, string and others. In addition, the first column in the table must be a timestamp. TDengine uses the time stamp as the index, and won’t build the index on any metrics stored. Column wise storage is used.
Complex devices, such as connected cars, may have multiple DCPs. In this case, multiple tables are created for a single device, one table per DCP.
Super Table (STable)
The design of one table for one data collection point will require a huge number of tables, which is difficult to manage. Furthermore, applications often need to take aggregation operations among DCPs, thus aggregation operations will become complicated. To support aggregation over multiple tables efficiently, the STable(Super Table) concept is introduced by TDengine.
STable is a template for a type of data collection point. A STable contains a set of data collection points (tables) that have the same schema or data structure, but with different static attributes (tags). To describe a STable, in addition to defining the table structure of the metrics, it is also necessary to define the schema of its tags. The data type of tags can be int, float, string, and there can be multiple tags, which can be added, deleted, or modified afterward. If the whole system has N different types of data collection points, N STables need to be established.
In the design of TDengine, a table is used to represent a specific data collection point, and STable is used to represent a set of data collection points of the same type. In the smart meters example, we can create a super table named meters.
Subtable
When creating a table for a specific data collection point, the user can use a STable as a template and specify the tag values of this specific DCP to create it. The table created by using a STable as the template is called subtable in TDengine. The difference between regular table and subtable is:
- Subtable is a table, all SQL commands applied on a regular table can be applied on subtable.
- Subtable is a table with extensions, it has static tags (labels), and these tags can be added, deleted, and updated after it is created. But a regular table does not have tags.
- A subtable belongs to only one STable, but a STable may have many subtables. Regular tables do not belong to a STable.
- A regular table can not be converted into a subtable, and vice versa.
The relationship between a STable and the subtables created based on this STable is as follows:
- A STable contains multiple subtables with the same metric schema but with different tag values.
- The schema of metrics or labels cannot be adjusted through subtables, and it can only be changed via STable. Changes to the schema of a STable takes effect immediately for all associated subtables.
- STable defines only one template and does not store any data or label information by itself. Therefore, data cannot be written to a STable, only to subtables.
Queries can be executed on both a table (subtable) and a STable. For a query on a STable, TDengine will treat the data in all its subtables as a whole data set for processing. TDengine will first find the subtables that meet the tag filter conditions, then scan the time-series data of these subtables to perform aggregation operation, which reduces the number of data sets to be scanned which in turn greatly improves the performance of data aggregation across multiple DCPs. In essence, querying a supertable is a very efficient aggregate query on multiple DCPs of the same type.
In TDengine, it is recommended to use a subtable instead of a regular table for a DCP. In the smart meters example, we can create subtables like d1001, d1002, d1003, and d1004 under super table meters.
To better understand the data model using metric, tags, super table and subtable, please refer to the diagram below which demonstrates the data model of the smart meters example. 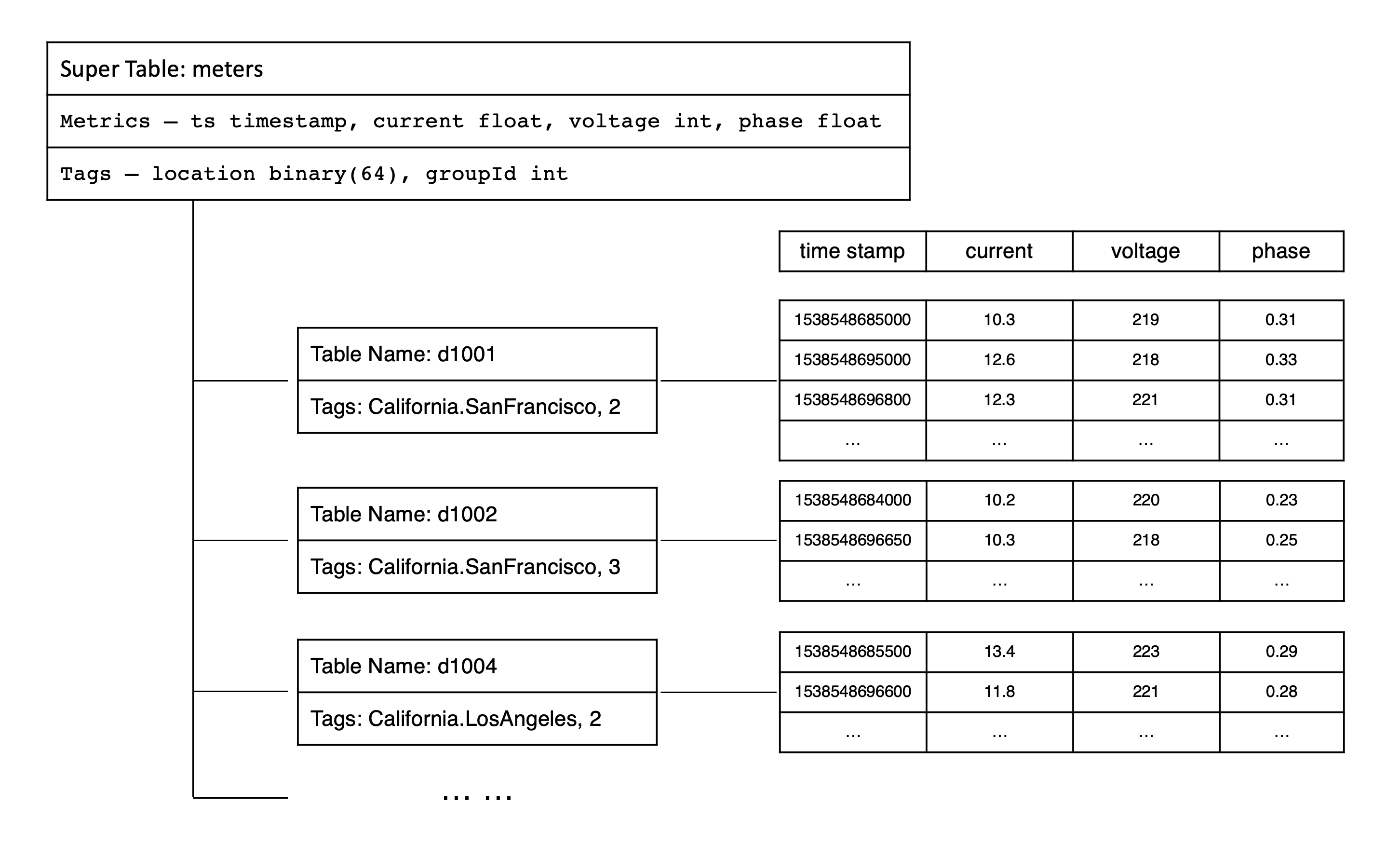
Database
A database is a collection of tables. TDengine allows a running instance to have multiple databases, and each database can be configured with different storage policies. The characteristics of time-series data from different data collection points may be different. Characteristics include collection frequency, retention policy and others which determine how you create and configure the database. For e.g. days to keep, number of replicas, data block size, whether data updates are allowed and other configurable parameters would be determined by the characteristics of your data and your business requirements. In order for TDengine to work with maximum efficiency in various scenarios, TDengine recommends that STables with different data characteristics be created in different databases.
In a database, there can be one or more STables, but a STable belongs to only one database. All tables owned by a STable are stored in only one database.
Instance, URL, Token
An instance is a running cluster of nodes of TDengine with one or more databases. An instance cannot span across multiple regions or multiple clouds. TDengine cloud provides a unique URL for each instance and uses tokens to authenticate the access. The token is generated by TDengine cloud for each user and for each instance. The token has an expiration date and can be reset by the user for each instance at any time for security purpose.
User, Organization
When a user register TDengine cloud service, an organization with one instance is created automatically, and he/she becomes the system administrator for this organization automatically. The system administrator can add more instances in an organization later. In addition, the system administrator can invite others to share data within his/her organization with specified privileges. He/she can share the whole organization, instance, a database or topics with fine tuned privileges to make sure data is securely shared.
A user is uniquely identified by email address. He/she may belongs to multiple organizations. In different organization, he/she may have different roles and different access privileges.
The billing is based on the usage for all the instances owned by an organization.