

Time-Series Extensions
TDengine, in addition to supporting standard SQL, also offers a series of specialized query syntaxes tailored for time-series business scenarios, which greatly facilitate the development of applications in time-series contexts.
TDengine's featured queries include data partitioning queries and time window partitioning queries.
Data Partitioning Queries
Data partitioning clauses are used when it is necessary to partition data according to certain dimensions and then perform a series of calculations within the partitioned data space. The syntax for data partitioning statements is as follows:
PARTITION BY part_list
part_list can be any scalar expression, including columns, constants, scalar functions, and their combinations. For example, grouping data by the location tag and calculating the average voltage for each group:
select location, avg(voltage) from meters partition by location
TDengine processes the data partitioning clause as follows:
- The data partitioning clause is located after the WHERE clause.
- The data partitioning clause divides the table data according to the specified dimensions, and each partitioned slice undergoes the specified calculations. These calculations are defined by subsequent clauses (window clause, GROUP BY clause, or SELECT clause).
- The data partitioning clause can be used together with a window partitioning clause (or GROUP BY clause), where the subsequent clauses apply to each partitioned slice. For example, grouping data by the
locationtag and downsampling each group every 10 minutes to get the maximum value.
select _wstart, location, max(current) from meters partition by location interval(10m)
The most common use of the data partitioning clause is in supertable queries, where subtable data is partitioned by tags and then calculated separately. Especially the PARTITION BY TBNAME usage, which isolates the data of each subtable, forming independent time-series, greatly facilitating statistical analysis in various time-series scenarios. For example, calculating the average voltage of each electric meter every 10 minutes:
select _wstart, tbname, avg(voltage) from meters partition by tbname interval(10m)
Window Partitioning Queries
TDengine supports aggregation result queries using time window partitioning, such as when a temperature sensor collects data every second, but the average temperature every 10 minutes is needed. In such scenarios, a window clause can be used to obtain the desired query results. The window clause is used to divide the data set being queried into subsets for aggregation based on the window, including time window, status window, session window, event window, and count window. Time windows can further be divided into sliding time windows and tumbling time windows.
The syntax for the window clause is as follows:
window_clause: {
SESSION(ts_col, tol_val)
| STATE_WINDOW(col) [TRUE_FOR(true_for_duration)]
| INTERVAL(interval_val [, interval_offset]) [SLIDING (sliding_val)] [FILL(fill_mod_and_val)]
| EVENT_WINDOW START WITH start_trigger_condition END WITH end_trigger_condition [TRUE_FOR(true_for_duration)]
| COUNT_WINDOW(count_val[, sliding_val])
}
Here, interval_val and sliding_val both represent time periods, and interval_offset represents the window offset, which must be less than interval_val. The syntax supports three forms, explained as follows:
- INTERVAL(1s, 500a) SLIDING(1s), with time units in single character form, where: a (milliseconds), b (nanoseconds), d (days), h (hours), m (minutes), n (months), s (seconds), u (microseconds), w (weeks), y (years).
- INTERVAL(1000, 500) SLIDING(1000), without time units, using the time precision of the query library as the default time unit, and when multiple libraries are present, the one with higher precision is used by default.
- INTERVAL('1s', '500a') SLIDING('1s'), with time units in string form, where the string must not contain any spaces or other characters.
Rules for Window Clause
- The window clause is placed after the data segmentation clause and cannot be used together with the GROUP BY clause.
- The window clause divides the data by windows and calculates the expressions in the SELECT list for each window. The expressions in the SELECT list can only include:
- Constants.
- Pseudocolumns _wstart,_wend, and _wduration.
- Aggregate functions (including selection functions and time-series specific functions that can determine the number of output rows by parameters).
- Expressions containing the above expressions.
- And must include at least one aggregate function.
- The window clause cannot be used together with the GROUP BY clause.
- WHERE statements can specify the start and end time of the query and other filtering conditions.
FILL Clause
The FILL statement specifies the filling mode when data is missing in a window interval. The filling modes include:
- No filling: NONE (default filling mode).
- VALUE filling: Fixed value filling, where the fill value must be specified. For example: FILL(VALUE, 1.23). Note that the final fill value is determined by the type of the corresponding column, such as FILL(VALUE, 1.23), if the corresponding column is of INT type, then the fill value is 1. If multiple columns in the query list need FILL, then each FILL column must specify a VALUE, such as
SELECT _wstart, min(c1), max(c1) FROM ... FILL(VALUE, 0, 0). Note, only ordinary columns in the SELECT expression need to specify FILL VALUE, such as_wstart,_wstart+1a,now,1+1and the partition key (like tbname) used with partition by do not need to specify VALUE, liketimediff(last(ts), _wstart)needs to specify VALUE. - PREV filling: Fill data using the previous value. For example: FILL(PREV).
- NULL filling: Fill data with NULL. For example: FILL(NULL).
- LINEAR filling: Perform linear interpolation filling based on the nearest values before and after. For example: FILL(LINEAR).
- NEXT filling: Fill data using the next value. For example: FILL(NEXT).
Among these filling modes, except for the NONE mode which does not fill by default, other modes will be ignored if there is no data in the entire query time range, resulting in no fill data and an empty query result. This behavior is reasonable under some modes (PREV, NEXT, LINEAR) because no data means no fill value can be generated. For other modes (NULL, VALUE), theoretically, fill values can be generated, and whether to output fill values depends on the application's needs. To meet the needs of applications that require forced filling of data or NULL, without breaking the compatibility of existing filling modes, two new filling modes have been added starting from version 3.0.3.0:
- NULL_F: Force fill with NULL values
- VALUE_F: Force fill with VALUE values
The differences between NULL, NULL_F, VALUE, VALUE_F filling modes for different scenarios are as follows:
- INTERVAL clause: NULL_F, VALUE_F are forced filling modes; NULL, VALUE are non-forced modes. In this mode, their semantics match their names.
- Stream computing's INTERVAL clause: NULL_F behaves the same as NULL, both are non-forced modes; VALUE_F behaves the same as VALUE, both are non-forced modes. Thus, there are no forced modes in the INTERVAL of stream computing.
- INTERP clause: NULL and NULL_F behave the same, both are forced modes; VALUE and VALUE_F behave the same, both are forced modes. Thus, there are no non-forced modes in INTERP.
- When using the FILL statement, a large amount of fill output may be generated, so be sure to specify the query time range. For each query, the system can return up to 10 million results with interpolation.
- In time dimension aggregation, the returned results have a strictly monotonically increasing time-series.
- If the query object is a supertable, the aggregate functions will apply to all tables under the supertable that meet the value filtering conditions. If the query does not use a PARTITION BY statement, the returned results will have a strictly monotonically increasing time-series; if the query uses a PARTITION BY statement for grouping, the results within each PARTITION will have a strictly monotonically increasing time series.
Time Windows
Time windows can be divided into sliding time windows and tumbling time windows.
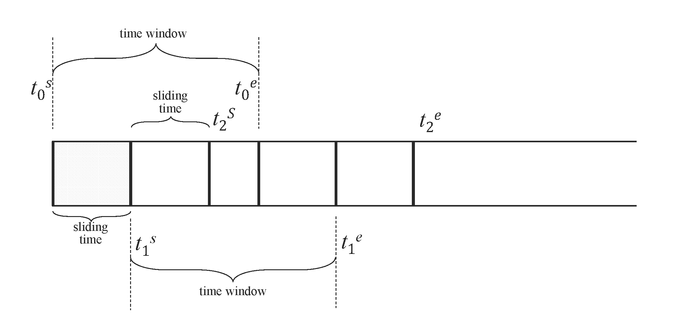
The INTERVAL clause is used to generate windows of equal time periods, and SLIDING is used to specify the time the window slides forward. Each executed query is a time window, and the time window slides forward as time flows. When defining continuous queries, it is necessary to specify the size of the time window (time window) and the forward sliding times for each execution. As shown, [t0s, t0e], [t1s, t1e], [t2s, t2e] are the time window ranges for three continuous queries, and the sliding time range is indicated by sliding time. Query filtering, aggregation, and other operations are performed independently for each time window. When SLIDING is equal to INTERVAL, the sliding window becomes a tumbling window. By default, windows begin at Unix time 0 (1970-01-01 00:00:00 UTC). If interval_offset is specified, the windows start from "Unix time 0 + interval_offset".
The INTERVAL and SLIDING clauses need to be used in conjunction with aggregation and selection functions. The following SQL statement is illegal:
SELECT * FROM temp_tb_1 INTERVAL(1m);
The forward sliding time of SLIDING cannot exceed the time range of one window. The following statement is illegal:
SELECT COUNT(*) FROM temp_tb_1 INTERVAL(1m) SLIDING(2m);
The INTERVAL clause allows the use of the AUTO keyword to specify the window offset (Supported in version 3.3.5.0 and later). If the WHERE condition provides a clear applicable start time limit, the required offset will be automatically calculated, dividing the time window from that point; otherwise, it defaults to an offset of 0. Here are some simple examples:
-- With a start time limit, divide the time window from '2018-10-03 14:38:05'
SELECT COUNT(*) FROM meters WHERE _rowts >= '2018-10-03 14:38:05' INTERVAL (1m, AUTO);
-- Without a start time limit, defaults to an offset of 0
SELECT COUNT(*) FROM meters WHERE _rowts < '2018-10-03 15:00:00' INTERVAL (1m, AUTO);
-- Unclear start time limit, defaults to an offset of 0
SELECT COUNT(*) FROM meters WHERE _rowts - voltage > 1000000;
When using time windows, note:
- The window width of the aggregation period is specified by the keyword INTERVAL, with the shortest interval being 10 milliseconds (10a); it also supports an offset (the offset must be less than the interval), which is the offset of the time window division compared to "UTC moment 0". The SLIDING statement is used to specify the forward increment of the aggregation period, i.e., the duration of each window slide forward.
- When using the INTERVAL statement, unless in very special cases, it is required to configure the timezone parameter in the taos.cfg configuration files of both the client and server to the same value to avoid frequent cross-time zone conversions by time processing functions, which can cause severe performance impacts.
- The returned results have a strictly monotonically increasing time-series.
- When using AUTO as the window offset, if the WHERE time condition is complex, such as multiple AND/OR/IN combinations, AUTO may not take effect. In such cases, you can manually specify the window offset to resolve the issue.
- When using AUTO as the window offset, if the window width unit is d (day), n (month), w (week), y (year), such as: INTERVAL(1d, AUTO), INTERVAL(3w, AUTO), the TSMA optimization cannot take effect. If TSMA is manually created on the target table, the statement will report an error and exit; in this case, you can explicitly specify the Hint SKIP_TSMA or not use AUTO as the window offset.
State Window
Use integers (boolean values) or strings to identify the state of the device when the record is generated. Records with the same state value belong to the same state window, and the window closes after the value changes. As shown in the diagram below, the state windows determined by the state value are [2019-04-28 14:22:07, 2019-04-28 14:22:10] and [2019-04-28 14:22:11, 2019-04-28 14:22:12].

Use STATE_WINDOW to determine the column that divides the state window. For example:
SELECT COUNT(*), FIRST(ts), status FROM temp_tb_1 STATE_WINDOW(status);
Only interested in the state window information when status is 2. For example:
SELECT * FROM (SELECT COUNT(*) AS cnt, FIRST(ts) AS fst, status FROM temp_tb_1 STATE_WINDOW(status)) t WHERE status = 2;
TDengine also supports using CASE expressions in state quantities, which can express that the start of a certain state is triggered by meeting a certain condition, and the end of this state is triggered by meeting another condition. For example, the normal voltage range for a smart meter is 205V to 235V, so you can monitor the voltage to determine if the circuit is normal.
SELECT tbname, _wstart, CASE WHEN voltage >= 205 and voltage <= 235 THEN 1 ELSE 0 END status FROM meters PARTITION BY tbname STATE_WINDOW(CASE WHEN voltage >= 205 and voltage <= 235 THEN 1 ELSE 0 END);
The state window supports using the TRUE_FOR parameter to set its minimum duration. If the window's duration is less than the specified value, it will be discarded automatically and no result will be returned. For example, setting the minimum duration to 3 seconds:
SELECT COUNT(*), FIRST(ts), status FROM temp_tb_1 STATE_WINDOW(status) TRUE_FOR (3s);
Session Window
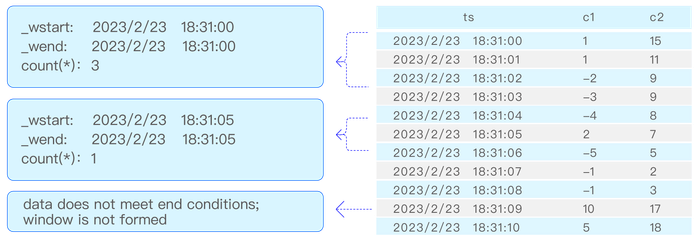
The session window is determined based on the timestamp primary key values of the records. As shown in the diagram below, if the continuous interval of the timestamps is set to be less than or equal to 12 seconds, the following 6 records form 2 session windows, which are: [2019-04-28 14:22:10, 2019-04-28 14:22:30] and [2019-04-28 14:23:10, 2019-04-28 14:23:30]. This is because the interval between 2019-04-28 14:22:30 and 2019-04-28 14:23:10 is 40 seconds, exceeding the continuous interval (12 seconds).
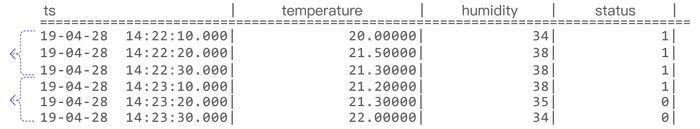
Results within the tol_value time interval are considered to belong to the same window; if the time between two consecutive records exceeds tol_val, the next window automatically starts.
SELECT COUNT(*), FIRST(ts) FROM temp_tb_1 SESSION(ts, tol_val);
Event Window
The event window is defined by start and end conditions. The window starts when the start_trigger_condition is met and closes when the end_trigger_condition is met. start_trigger_condition and end_trigger_condition can be any condition expressions supported by TDengine and can include different columns.
Event windows can contain only one data point. That is, when a data point simultaneously meets both the start_trigger_condition and end_trigger_condition, and is not currently within a window, it alone constitutes a window.
Event windows that cannot be closed do not form a window and will not be output. That is, if data meets the start_trigger_condition and the window opens, but subsequent data does not meet the end_trigger_condition, the window cannot be closed, and this data does not form a window and will not be output.
If event window queries are performed directly on a supertable, TDengine will aggregate the data of the supertable into a single timeline and then perform the event window calculation. If you need to perform event window queries on the result set of a subquery, then the result set of the subquery needs to meet the requirements of outputting by timeline and can output a valid timestamp column.
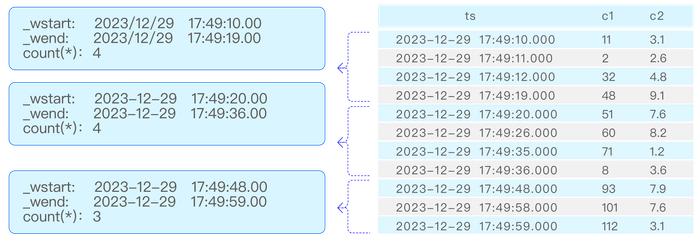
Take the following SQL statement as an example, the event window segmentation is shown in the diagram:
select _wstart, _wend, count(*) from t event_window start with c1 > 0 end with c2 < 10
The event window supports using the TRUE_FOR parameter to set its minimum duration. If the window's duration is less than the specified value, it will be discarded automatically and no result will be returned. For example, setting the minimum duration to 3 seconds:
select _wstart, _wend, count(*) from t event_window start with c1 > 0 end with c2 < 10 true_for (3s);
Count Window
Count windows divide data into windows based on a fixed number of data rows. By default, data is sorted by timestamp, then divided into multiple windows based on the value of count_val, and aggregate calculations are performed. count_val represents the maximum number of data rows in each count window; if the total number of data rows is not divisible by count_val, the last window will have fewer rows than count_val. sliding_val is a constant that represents the number of rows the window slides, similar to the SLIDING in interval.
Take the following SQL statement as an example, the count window segmentation is shown in the diagram:
select _wstart, _wend, count(*) from t count_window(4);
Timestamp Pseudo Columns
In window aggregate query results, if the SQL statement does not specify the output of the timestamp column in the query results, the final results will not automatically include the window's time column information. If you need to output the time window information corresponding to the aggregate results in the results, you need to use timestamp-related pseudocolumns in the SELECT clause: window start time (_WSTART), window end time (_WEND), window duration (_WDURATION), and overall query window related pseudo columns: query window start time (_QSTART) and query window end time (_QEND). Note that both the start and end times of the time window are closed intervals, and the window duration is the numerical value under the current time resolution of the data. For example, if the current database's time resolution is milliseconds, then 500 in the results represents the duration of the current time window is 500 milliseconds (500 ms).
Example
The table creation statement for smart meters is as follows:
CREATE TABLE meters (ts TIMESTAMP, current FLOAT, voltage INT, phase FLOAT) TAGS (location BINARY(64), groupId INT);
For data collected from smart meters, calculate the average, maximum, and median current over the past 24 hours in 10-minute intervals. If there is no calculated value, fill with the previous non-NULL value. The query statement used is as follows:
SELECT _WSTART, _WEND, AVG(current), MAX(current), APERCENTILE(current, 50) FROM meters
WHERE ts>=NOW-1d and ts<=now
INTERVAL(10m)
FILL(PREV);


