

Stream Processing
Creating Stream Computing
CREATE STREAM [IF NOT EXISTS] stream_name [stream_options] INTO stb_name[(field1_name, field2_name [COMPOSITE KEY], ...)] [TAGS (create_definition [, create_definition] ...)] SUBTABLE(expression) AS subquery [notification_definition]
stream_options: {
TRIGGER [AT_ONCE | WINDOW_CLOSE | MAX_DELAY time | FORCE_WINDOW_CLOSE | CONTINUOUS_WINDOW_CLOSE [recalculate rec_time_val] ]
WATERMARK time
IGNORE EXPIRED [0|1]
DELETE_MARK time
FILL_HISTORY [0|1] [ASYNC]
IGNORE UPDATE [0|1]
}
Where subquery is a subset of the normal query syntax for select:
subquery: SELECT select_list
from_clause
[WHERE condition]
[PARTITION BY tag_list]
window_clause
Supports session windows, state windows, sliding windows, event windows, and count windows. State windows, event windows, and count windows must be used with partition by tbname when paired with supertables. For streams whose data source tables have composite primary keys, state windows, event windows, and count windows are not supported.
stb_name is the table name of the supertable where the computation results are saved. If this supertable does not exist, it will be automatically created; if it already exists, then the column schema information is checked. See Writing to an Existing Supertable.
TAGS clause defines the rules for creating TAGs in stream computing, allowing custom tag values to be generated for each partition's subtable. See Custom tag
create_definition:
col_name column_definition
column_definition:
type_name [COMMENT 'string_value']
The subtable clause defines the naming rules for the subtables created in stream computing. See the partition section of stream computing.
window_clause: {
SESSION(ts_col, tol_val)
| STATE_WINDOW(col)
| INTERVAL(interval_val [, interval_offset]) [SLIDING (sliding_val)]
| EVENT_WINDOW START WITH start_trigger_condition END WITH end_trigger_condition
| COUNT_WINDOW(count_val[, sliding_val])
}
Where SESSION is a session window, tol_val is the maximum range of the time interval. All data within the tol_val time interval belong to the same window. If the time between two consecutive data points exceeds tol_val, the next window automatically starts. The window's_wend equals the last data point's time plus tol_val.
STATE_WINDOW is a state window. The col is used to identify the state value. Values with the same state value belong to the same state window. When the value of col changes, the current window ends and the next window is automatically opened.
INTERVAL is a time window, which can be further divided into sliding time windows and tumbling time windows.The INTERVAL clause is used to specify the equal time period of the window, and the SLIDING clause is used to specify the time by which the window slides forward. When the value of interval_val is equal to the value of sliding_val, the time window is a tumbling time window; otherwise, it is a sliding time window. Note: The value of sliding_val must be less than or equal to the value of interval_val.
EVENT_WINDOW is an event window, defined by start and end conditions. The window starts when the start_trigger_condition is met and closes when the end_trigger_condition is met. start_trigger_condition and end_trigger_condition can be any condition expression supported by TDengine and can include different columns.
COUNT_WINDOW is a count window, dividing the window by a fixed number of data rows. count_val is a constant, a positive integer, must be at least 2 and less than 2147483648. count_val represents the maximum number of data rows each COUNT_WINDOW contains. If the total number of data rows is not divisible by count_val, the last window will have fewer rows than count_val. sliding_val is a constant, representing the number of rows the window slides, similar to the SLIDING in INTERVAL.
The definition of the window is exactly the same as in the time-series data characteristic query, see TDengine Characteristic Query
For example, the following statement creates stream computing. The first stream computing automatically creates a supertable named avg_vol, with a one-minute time window and a 30-second forward increment to calculate the average voltage of these meters and writes the results from the meters table into the avg_vol table. Data from different partitions will create separate subtables and write into different subtables.
The second stream computation automatically creates a supertable named streamt0. It segments the data in chronological order based on the timestamp, using voltage < 0 as the start condition and voltage > 9 as the end condition for the window. It performs aggregation operations within these windows and writes the results from the meters table into the streamt0 table. Data from different partitions will create subtables and write into these respective subtables.
The third stream computation automatically creates a supertable named streamt1. It segments the data in chronological order based on the timestamp, grouping every 10 data points together to form a window for aggregation operations. It then writes the results from the meters table into the streamt1 table. Data from different partitions will create subtables and write into these respective subtables.
CREATE STREAM avg_vol_s INTO avg_vol AS
SELECT _wstart, count(*), avg(voltage) FROM meters PARTITION BY tbname INTERVAL(1m) SLIDING(30s);
CREATE STREAM streams0 INTO streamt0 AS
SELECT _wstart, count(*), avg(voltage) from meters PARTITION BY tbname EVENT_WINDOW START WITH voltage < 0 END WITH voltage > 9;
CREATE STREAM streams1 IGNORE EXPIRED 1 WATERMARK 100s INTO streamt1 AS
SELECT _wstart, count(*), avg(voltage) from meters PARTITION BY tbname COUNT_WINDOW(10);
notification_definition clause specifies the addresses to which notifications should be sent when designated events occur during window computations, such as window opening or closing. For more details, see Stream Computing Event Notifications.
Stream Computation Partitioning
You can use PARTITION BY TBNAME, tags, regular columns, or expressions to partition a stream for multi-partition computation. Each partition's timeline and window are independent, aggregating separately, and writing into different subtables of the target table.
Without the PARTITION BY clause, all data will be written into a single subtable.
When creating a stream without using the SUBTABLE clause, the supertable created by stream computation has a unique tag column groupId, and each partition is assigned a unique groupId. Consistent with schemaless writing, we calculate the subtable name using MD5 and automatically create it.
If the statement for creating a stream includes the SUBTABLE clause, users can generate custom table names for each partition's corresponding subtable, for example:
CREATE STREAM avg_vol_s INTO avg_vol SUBTABLE(CONCAT('new-', tname)) AS SELECT _wstart, count(*), avg(voltage) FROM meters PARTITION BY tbname tname INTERVAL(1m);
In the PARTITION clause, an alias tname is defined for tbname. The alias in the PARTITION clause can be used in the expression calculation in the SUBTABLE clause. In the example above, the newly created subtables will have names prefixed with 'new-' connected to the original table name (from version 3.2.3.0, to avoid confusion in SUBTABLE expressions that could mistakenly write multiple timelines into one subtable, the specified subtable name is appended with _stableName_groupId).
Note, if the subtable name exceeds the length limit of TDengine, it will be truncated. If the generated subtable name already exists in another supertable, since TDengine's subtable names are unique, the creation of the new subtable and data writing will fail.
Stream Computation Reading Historical Data
Normally, stream computations do not process data that was written into the source table before the creation of the stream. If you want to process data that has already been written, you can set the fill_history 1 option when creating the stream. This setting allows the stream computation to automatically process data written before, during, and after its creation. The maximum number of windows for processing historical data is 20 million, exceeding this limit will result in an error. For example:
create stream if not exists s1 fill_history 1 into st1 as select count(*) from t1 interval(10s)
Combining the fill_history 1 option, you can process data only within a specific historical time range, for example, only data after a certain historical moment (January 30, 2020):
create stream if not exists s1 fill_history 1 into st1 as select count(*) from t1 where ts > '2020-01-30' interval(10s)
For instance, to process data only within a certain time period, the end time can be a future date:
create stream if not exists s1 fill_history 1 into st1 as select count(*) from t1 where ts > '2020-01-30' and ts < '2023-01-01' interval(10s)
If the stream task is completely outdated and you no longer want it to monitor or process data, you can manually delete it. The computed data will still be retained.
Tips:
-
When enabling fill_history, creating a stream requires finding the boundary point of historical data. If there is a lot of historical data, it may cause the task of creating a stream to take a long time. In this case, you can use fill_history 1 async (supported since version 3.3.6.0) , then the task of creating a stream can be processed in the background. The statement of creating a stream can be returned immediately without blocking subsequent operations. async only takes effect when fill_history 1 is used, and creating a stream with fill_history 0 is very fast and does not require asynchronous processing.
-
Show streams can be used to view the progress of background stream creation (ready status indicates success, init status indicates stream creation in progress, failed status indicates that the stream creation has failed, and the message column can be used to view the reason for the failure. In the case of failed stream creation, the stream can be deleted and rebuilt).
-
Besides, do not create multiple streams asynchronously at the same time, as transaction conflicts may cause subsequent streams to fail.
Deleting Stream Computing
DROP STREAM [IF EXISTS] stream_name;
This only deletes the stream computing task; data written by the stream computation is not deleted.
Displaying Stream Computing
SHOW STREAMS;
To display more detailed information, you can use:
SELECT * from information_schema.`ins_streams`;
Trigger Modes of Stream Computing
When creating a stream, you can specify the trigger mode of stream computing through the TRIGGER command.
For non-window computations, the trigger of stream computing is real-time; for window computations, currently, there are 4 trigger modes, with WINDOW_CLOSE as the default:
- AT_ONCE: Triggered immediately upon writing
- WINDOW_CLOSE: Triggered when the window closes (window closure is determined by event time, can be used in conjunction with watermark)
- MAX_DELAY time: Trigger computation if the window closes. If the window does not close, and the time since it has not closed exceeds the time specified by max delay, then trigger computation.
- FORCE_WINDOW_CLOSE: Based on the current time of the operating system, only compute and push the results of the currently closed window. The window is only computed once at the moment of closure and will not be recalculated subsequently. This mode currently only supports INTERVAL windows (does not support sliding); FILL_HISTORY must be 0, IGNORE EXPIRED must be 1, IGNORE UPDATE must be 1; FILL only supports PREV, NULL, NONE, VALUE.
- CONTINUOUS_WINDOW_CLOSE: Results are output when the window is closed. Modifying or deleting data does not immediately trigger a recalculation. Instead, periodic recalculations are performed every rec_time_val duration. If rec_time_val is not specified, the recalculation period is 60 minutes. If the recalculation time exceeds rec_time_val, the next recalculation will be automatically initiated after the current one is completed. Currently, this mode only supports INTERVAL windows. If the FILL clause is used, relevant information of the adapter needs to be configured, including adapterFqdn, adapterPort, and adapterToken. The adapterToken is a string obtained by Base64-encoding
{username}:{password}. For example, after encodingroot:taosdata, the result iscm9vdDp0YW9zZGF0YQ==.
Since the closure of the window is determined by event time, if the event stream is interrupted or continuously delayed, the event time cannot be updated, which may result in not obtaining the latest computation results.
Therefore, stream computing provides the MAX_DELAY trigger mode, which calculates based on event time combined with processing time. The minimum time for MAX_DELAY is 5s; if it is less than 5s, an error will occur when creating the stream computation.
In MAX_DELAY mode, computation is immediately triggered when the window closes. Additionally, when data is written and the time since the last computation trigger exceeds the time specified by max delay, computation is immediately triggered.
Window Closure in Stream Computing
Stream computing calculates window closure based on event time (the timestamp primary key in the inserted records), not based on TDengine server time. By using event time as the basis, it avoids issues caused by discrepancies between client and server times and can address problems like out-of-order data writes. Stream computing also provides a watermark to define the tolerance level for out-of-order data.
When creating a stream, you can specify a watermark in the stream_option, which defines the upper bound of tolerance for data disorder.
Stream computing measures the tolerance for out-of-order data through watermark, which is set to 0 by default.
T = Latest event time - watermark
Each data write updates the window closure time using the above formula, and all open windows with an end time < T are closed. If the trigger mode is WINDOW_CLOSE or MAX_DELAY, the aggregated results of the window are pushed.
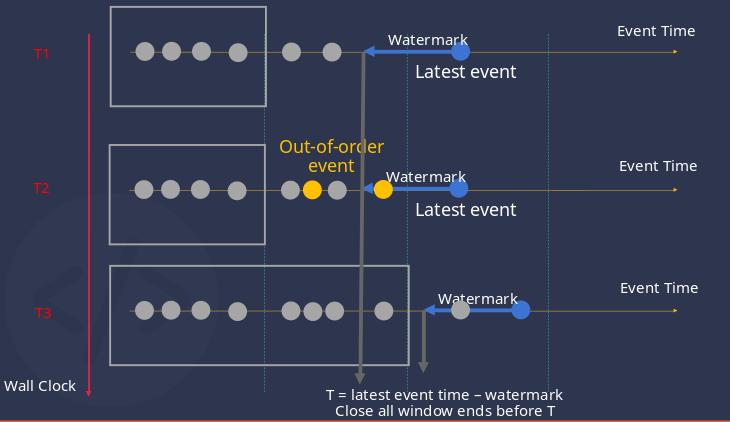
In the diagram, the vertical axis represents different moments in time. For each moment, we plot the data received by TDengine on the horizontal axis.
The data points on the horizontal axis represent the data received, where the blue points indicate the latest event time (i.e., the timestamp primary key in the data). Subtracting the defined watermark time from this data point gives the upper bound T for tolerance of disorder.
All windows with an end time less than T will be closed (marked with gray boxes in the diagram).
At moment T2, out-of-order data (yellow points) arrives at TDengine. Due to the presence of watermark, the windows these data enter are not closed, thus they can be correctly processed.
At moment T3, the latest event arrives, and T moves forward beyond the closure time of the second window, which is then closed, and the out-of-order data is correctly processed.
In window_close or max_delay modes, window closure directly affects the push results. In at_once mode, window closure is only related to memory usage.
Stream Computing's Strategy for Handling Expired Data
For windows that have closed, data that falls into these windows again is marked as expired data.
TDengine provides two ways to handle expired data, specified by the IGNORE EXPIRED option:
-
Incremental computation, i.e., IGNORE EXPIRED 0.
-
Direct discard, i.e., IGNORE EXPIRED 1: Default configuration, ignore expired data
In either mode, the watermark should be properly set to obtain correct results (direct discard mode) or to avoid the performance overhead caused by frequent re-triggering of recalculations (recalculation mode).
Stream computing strategies for handling modified data
TDengine offers two ways to handle modified data, specified by the IGNORE UPDATE option:
-
Check if the data has been modified, i.e., IGNORE UPDATE 0. If the data is modified, recalculate the corresponding window.
-
Do not check if the data has been modified, calculate all as incremental data, i.e., IGNORE UPDATE 1, default configuration.
Writing to an existing supertable
[field1_name,...]
At the top of this page, [field1_name,...] is used to specify the correspondence between the columns of stb_name and the output results of the subquery. If the columns of stb_name and the position and quantity of the subquery output results match completely, there is no need to explicitly specify the correspondence. If the data types of the columns of stb_name do not match the subquery output results, the type of the subquery output results will be converted to the corresponding type of the columns of stb_name.
For an existing supertable, check the schema information of the columns:
- Check if the schema information of the columns matches; if not, automatically perform type conversion. Currently, an error is reported only when the data length exceeds 4096 bytes; in other scenarios, type conversion can be performed.
- Check if the number of columns is the same; if different, explicitly specify the correspondence between the supertable and the subquery columns, otherwise an error is reported; if the same, you can specify the correspondence or not. If not specified, it corresponds in the order of position.
Custom tag
Users can generate custom tag values for each subtable corresponding to a partition.
CREATE STREAM streams2 trigger at_once INTO st1 TAGS(cc varchar(100)) as select _wstart, count(*) c1 from st partition by concat("tag-", tbname) as cc interval(10s));
In the PARTITION clause, an alias cc is defined for concat("tag-", tbname), corresponding to the custom tag name of the supertable st1. In the example above, the tag of the newly created subtable in the stream will have the value prefixed with 'new-' connected to the original table name.
tag information will be checked as follows:
- Check if the schema information of the tag matches; if not, automatically perform data type conversion. Currently, an error is reported only when the data length exceeds 4096 bytes; in other scenarios, type conversion can be performed.
- Check if the number of tags is the same; if different, explicitly specify the correspondence between the supertable and the subquery tags, otherwise an error is reported; if the same, you can specify the correspondence or not. If not specified, it corresponds in the order of position.
Cleaning up intermediate states
DELETE_MARK time
DELETE_MARK is used to delete cached window states, i.e., to delete intermediate results of stream computing. If not set, the default value is 10 years. T = Latest event time - DELETE_MARK
Functions supported by stream computing
- All single-row functions can be used in stream computing.
- The following 19 aggregate/selection functions cannot be applied in SQL statements creating stream computing. Other types of functions can be used in stream computing.
- leastsquares
- percentile
- top
- bottom
- elapsed
- interp
- derivative
- irate
- twa
- histogram
- diff
- statecount
- stateduration
- csum
- mavg
- sample
- tail
- unique
- mode
Pause and Resume Stream Computing
-
Pause stream computing task PAUSE STREAM [IF EXISTS] stream_name; If IF EXISTS is not specified and the stream does not exist, an error is reported; if it exists, the stream computing is paused. If IF EXISTS is specified, it returns success if the stream does not exist; if it exists, the stream computing is paused.
-
Resume stream computing task RESUME STREAM [IF EXISTS] [IGNORE UNTREATED] stream_name; If IF EXISTS is not specified, an error is reported if the stream does not exist; if it exists, the stream computing is resumed. If IF EXISTS is specified, it returns success if the stream does not exist; if it exists, the stream computing is resumed. If IGNORE UNTREATED is specified, it ignores the data written during the pause when resuming the stream computing.
State Data Backup and Synchronization
The intermediate results of stream computing become the state data of the computation, which needs to be persistently saved throughout the lifecycle of stream computing. To ensure that the intermediate state of stream computing can be reliably synchronized and migrated among different nodes in a cluster environment, starting from version 3.3.2.1, it is necessary to deploy rsync software in the operating environment and add the following steps:
- Configure the snode's address (IP + port) and state data backup directory (this directory is on the physical node where the snode is located) in the configuration file.
- Then create the snode. Only after completing these two steps can a stream be created. If the snode is not created and its address is not correctly configured, the stream computing process will not be able to generate checkpoints, and may lead to errors in subsequent computation results.
snodeAddress 127.0.0.1:873
checkpointBackupDir /home/user/stream/backup/checkpoint/
Method to Create snode
Use the following command to create an snode (stream node), which is a stateful computing node in stream computing, used for deploying aggregation tasks, and also responsible for backing up checkpoint data generated by different stream computing tasks.
CREATE SNODE ON DNODE [id]
The id is the serial number of the dnode in the cluster. Please be mindful of the selected dnode, as the intermediate state of stream computing will automatically be backed up on it. Starting from version 3.3.4.0, in a multi-replica environment, creating a stream will perform an existence check of snode, requiring the snode to be created first. If the snode does not exist, the stream cannot be created.
Stream Computing Event Notifications
User Guide
Stream computing supports sending event notifications to external systems when windows open or close. Users can specify the events to be notified and the target addresses for receiving notification messages using the notification_definition clause.
notification_definition:
NOTIFY (url [, url] ...) ON (event_type [, event_type] ...) [notification_options]
event_type:
'WINDOW_OPEN'
| 'WINDOW_CLOSE'
notification_options: {
NOTIFY_HISTORY [0|1]
ON_FAILURE [DROP|PAUSE]
}
The rules for the syntax above are as follows:
url: Specifies the target address for the notification. It must include the protocol, IP or domain name, port, and may include a path and parameters. Currently, only the websocket protocol is supported. For example: 'ws://localhost:8080', 'ws://localhost:8080/notify', 'wss://localhost:8080/notify?key=foo'.event_type: Defines the events that trigger notifications. Supported event types include:- 'WINDOW_OPEN': Window open event; triggered when any type of window opens.
- 'WINDOW_CLOSE': Window close event; triggered when any type of window closes.
NOTIFY_HISTORY: Controls whether to trigger notifications during the computation of historical data. The default value is 0, which means no notifications are sent.ON_FAILURE: Determines whether to allow dropping some events if sending notifications fails (e.g., in poor network conditions). The default value isPAUSE:- PAUSE means that the stream computing task is paused if sending a notification fails. taosd will retry until the notification is successfully delivered and the task resumes.
- DROP means that if sending a notification fails, the event information is discarded, and the stream computing task continues running unaffected.
For example, the following creates a stream that computes the per-minute average current from electric meters and sends notifications to two target addresses when the window opens and closes. It does not send notifications for historical data and does not allow dropping notifications on failure:
CREATE STREAM avg_current_stream FILL_HISTORY 1
AS SELECT _wstart, _wend, AVG(current) FROM meters
INTERVAL (1m)
NOTIFY ('ws://localhost:8080/notify', 'wss://192.168.1.1:8080/notify?key=foo')
ON ('WINDOW_OPEN', 'WINDOW_CLOSE');
NOTIFY_HISTORY 0
ON_FAILURE PAUSE;
When the specified events are triggered, taosd will send a POST request to the given URL(s) with a JSON message body. A single request may contain events from several streams, and the event types may differ.
The details of the event information depend on the type of window:
- Time Window: At the opening, the start time is sent; at the closing, the start time, end time, and computation result are sent.
- State Window: At the opening, the start time, previous window's state, and current window's state are sent; at closing, the start time, end time, computation result, current window state, and next window state are sent.
- Session Window: At the opening, the start time is sent; at the closing, the start time, end time, and computation result are sent.
- Event Window: At the opening, the start time along with the data values and corresponding condition index that triggered the window opening are sent; at the closing, the start time, end time, computation result, and the triggering data value and condition index for window closure are sent.
- Count Window: At the opening, the start time is sent; at the closing, the start time, end time, and computation result are sent.
An example structure for the notification message is shown below:
{
"messageId": "unique-message-id-12345",
"timestamp": 1733284887203,
"streams": [
{
"streamName": "avg_current_stream",
"events": [
{
"tableName": "t_a667a16127d3b5a18988e32f3e76cd30",
"eventType": "WINDOW_OPEN",
"eventTime": 1733284887097,
"windowId": "window-id-67890",
"windowType": "Time",
"groupId": "2650968222368530754",
"windowStart": 1733284800000
},
{
"tableName": "t_a667a16127d3b5a18988e32f3e76cd30",
"eventType": "WINDOW_CLOSE",
"eventTime": 1733284887197,
"windowId": "window-id-67890",
"windowType": "Time",
"groupId": "2650968222368530754",
"windowStart": 1733284800000,
"windowEnd": 1733284860000,
"result": {
"_wstart": 1733284800000,
"avg(current)": 1.3
}
}
]
},
{
"streamName": "max_voltage_stream",
"events": [
{
"tableName": "t_96f62b752f36e9b16dc969fe45363748",
"eventType": "WINDOW_OPEN",
"eventTime": 1733284887231,
"windowId": "window-id-13579",
"windowType": "Event",
"groupId": "7533998559487590581",
"windowStart": 1733284800000,
"triggerCondition": {
"conditionIndex": 0,
"fieldValue": {
"c1": 10,
"c2": 15
}
},
},
{
"tableName": "t_96f62b752f36e9b16dc969fe45363748",
"eventType": "WINDOW_CLOSE",
"eventTime": 1733284887231,
"windowId": "window-id-13579",
"windowType": "Event",
"groupId": "7533998559487590581",
"windowStart": 1733284800000,
"windowEnd": 1733284810000,
"triggerCondition": {
"conditionIndex": 1,
"fieldValue": {
"c1": 20,
"c2": 3
}
},
"result": {
"_wstart": 1733284800000,
"max(voltage)": 220
}
}
]
}
]
}
The following sections explain the fields in the notification message.
Root-Level Field Descriptions
- "messageId": A string that uniquely identifies the notification message. It ensures that the entire message can be tracked and de-duplicated.
- "timestamp": A long integer timestamp representing the time when the notification message was generated, accurate to the millisecond (i.e., the number of milliseconds since '00:00, Jan 1 1970 UTC').
- "streams": An array containing the event information for multiple stream tasks. (See the following sections for details.)
"stream" Object Field Descriptions
- "streamName": A string representing the name of the stream task, used to identify which stream the events belong to.
- "events": An array containing the list of event objects for the stream task. Each event object includes detailed information. (See the next sections for details.)
"event" Object Field Descriptions
Common Fields
These fields are common to all event objects.
- "tableName": A string indicating the name of the target subtable.
- "eventType": A string representing the event type ("WINDOW_OPEN", "WINDOW_CLOSE", or "WINDOW_INVALIDATION").
- "eventTime": A long integer timestamp that indicates when the event was generated, accurate to the millisecond (i.e., the number of milliseconds since '00:00, Jan 1 1970 UTC').
- "windowId": A string representing the unique identifier for the window. This ID ensures that the open and close events for the same window can be correlated. In the case that taosd restarts due to a fault, some events may be sent repeatedly, but the windowId remains constant for the same window.
- "windowType": A string that indicates the window type ("Time", "State", "Session", "Event", or "Count").
- "groupId": A string that uniquely identifies the corresponding group. If stream is partitioned by table, it matches the uid of that table.
Fields for Time Windows
These fields are present only when "windowType" is "Time".
- When "eventType" is "WINDOW_OPEN", the following field is included:
- "windowStart": A long integer timestamp representing the start time of the window, matching the time precision of the result table.
- When "eventType" is "WINDOW_CLOSE", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "windowEnd": A long integer timestamp representing the end time of the window.
- "result": An object containing key-value pairs of the computed result columns and their corresponding values.
Fields for State Windows
These fields are present only when "windowType" is "State".
- When "eventType" is "WINDOW_OPEN", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "prevState": A value of the same type as the state column, representing the state of the previous window. If there is no previous window (i.e., this is the first window), it will be NULL.
- "curState": A value of the same type as the state column, representing the current window's state.
- When "eventType" is "WINDOW_CLOSE", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "windowEnd": A long integer timestamp representing the end time of the window.
- "curState": The current window's state.
- "nextState": The state for the next window.
- "result": An object containing key-value pairs of the computed result columns and their corresponding values.
Fields for Session Windows
These fields are present only when "windowType" is "Session".
- When "eventType" is "WINDOW_OPEN", the following field is included:
- "windowStart": A long integer timestamp representing the start time of the window.
- When "eventType" is "WINDOW_CLOSE", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "windowEnd": A long integer timestamp representing the end time of the window.
- "result": An object containing key-value pairs of the computed result columns and their corresponding values.
Fields for Event Windows
These fields are present only when "windowType" is "Event".
- When "eventType" is "WINDOW_OPEN", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "triggerCondition": An object that provides information about the condition that triggered the window to open. It includes:
- "conditionIndex": An integer representing the index of the condition that triggered the window, starting from 0.
- "fieldValue": An object containing key-value pairs of the column names related to the condition and their respective values.
- When "eventType" is "WINDOW_CLOSE", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "windowEnd": A long integer timestamp representing the end time of the window.
- "triggerCondition": An object that provides information about the condition that triggered the window to close. It includes:
- "conditionIndex": An integer representing the index of the condition that triggered the closure, starting from 0.
- "fieldValue": An object containing key-value pairs of the related column names and their respective values.
- "result": An object containing key-value pairs of the computed result columns and their corresponding values.
Fields for Count Windows
These fields are present only when "windowType" is "Count".
- When "eventType" is "WINDOW_OPEN", the following field is included:
- "windowStart": A long integer timestamp representing the start time of the window.
- When "eventType" is "WINDOW_CLOSE", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "windowEnd": A long integer timestamp representing the end time of the window.
- "result": An object containing key-value pairs of the computed result columns and their corresponding values.
Fields for Window Invalidation
Due to scenarios such as data disorder, updates, or deletions during stream computing, windows that have already been generated might be removed or their results need to be recalculated. In such cases, a notification with the eventType "WINDOW_INVALIDATION" is sent to inform which windows have been invalidated.
For events with "eventType" as "WINDOW_INVALIDATION", the following fields are included:
- "windowStart": A long integer timestamp representing the start time of the window.
- "windowEnd": A long integer timestamp representing the end time of the window.
Support for Virtual Tables in Stream Computing
Starting with v3.3.6.0, stream computing can use virtual tables—including virtual regular tables, virtual sub-tables, and virtual super tables—as data sources for computation. The syntax is identical to that for non-virtual tables.
However, because the behavior of virtual tables differs from that of non-virtual tables, the following restrictions apply when using stream computing:
- The schema of virtual regular tables/virtual sub-tables involved in stream computing cannot be modified.
- During stream computing, if the data source corresponding to a column in a virtual table is changed, the stream computation will not pick up the change; it will still read from the old data source.
- During stream computing, if the original table corresponding to a column in a virtual table is deleted and later a new table with the same name and a column with the same name is created, the stream computation will not read data from the new table.
- The watermark for stream computing must be 0; otherwise, an error will occur during creation.
- If the data source for stream computing is a virtual super table, sub-tables that are added after the stream computing task starts will not participate in the computation.
- The timestamps of different underlying tables in a virtual table may not be completely consistent; merging the data might produce null values, and interpolation is currently not supported.
- Out-of-order data, updates, or deletions are not handled. In other words, when creating a stream, you cannot specify
ignore update 0orignore expired 0; otherwise, an error will be reported. - Historical data computation is not supported. That is, when creating a stream, you cannot specify
fill_history 1; otherwise, an error will be reported. - The trigger modes MAX_DELAY, CONTINUOUS_WINDOW_CLOSE and FORCE_WINDOW_CLOSE are not supported.
- The COUNT_WINDOW type is not supported.


