Introduction to TDengine TSDB
TDengine TSDB is a time-series database designed to help traditional industries overcome the challenges of Industry 4.0 and Industrial IoT. TDengine TSDB securely ingests, stores, analyzes, and distributes petabytes of data per day, generated by billions of sensors and devices. With a built-in AI agent for time-series forecasting and anomaly detection, TDengine TSDB delivers real-time business insights.
TDengine TSDB Offerings
- TDengine TSDB-OSS is an open-source, cloud-native time-series database. Its source code is licensed under the AGPL and publicly available on GitHub. TDengine TSDB-OSS serves as the code base for our paid offerings and provides the same core functionality. Unlike some open-core products, TDengine TSDB-OSS is a full-featured solution that includes the necessary components for production use, including clustering.
- TDengine TSDB-Enterprise is a high-performance, scalable time-series database designed for Industry 4.0 and the Industrial IoT. Built on the open-source TDengine TSDB-OSS, it delivers an enterprise-grade feature set tailored to the needs of traditional industries.
- TDengine Cloud delivers all features of TDengine TSDB-Enterprise as a fully managed service that can run on Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
What Makes TDengine TSDB Different
TDengine TSDB differentiates itself from typical time-series databases with the following four core competencies:
- High Performance at Any Scale: With its distributed scalable architecture that grows together with your business, TDengine TSDB can store and process massive datasets up to 10.6x faster than other TSDBs — all while providing the split-second latency that your real-time visualization and reporting apps demand.
- Efficient Data Storage: With its unique design and data model, TDengine TSDB provides the most cost-effective solution for storing your operations data, including tiered storage, S3, and 10:1 data compression, ensuring that you can get valuable business insights from your data without breaking the bank.
- Data Consolidation Across Sites: With built-in connectors for a wide variety of industrial sources — MQTT, Kafka, OPC, PI System, and more — TDengine TSDB delivers zero-code data ingestion and extract, transform, and load (ETL) in a centralized platform that acts as a single source of truth for your business.
- Comprehensive Solution for Industrial Data: With out-of-the-box data subscription, caching, and stream processing, TDengine TSDB is more than just a time-series database — it includes all key components needed for industrial data storage and processing built into a single product and accessible through familiar SQL statements.
What TDengine TSDB Delivers
With its innovative "one table per device" design, unique supertable concept, and highly optimized storage engine, TDengine TSDB is purpose-built to meet the unique needs of ingesting, querying, and storing massive time-series datasets. In its role at the core of the industrial data architecture, it provides the following functionality:
- Data Ingestion: You can write data into TDengine TSDB with standard SQL or in schemaless mode over the InfluxDB Line Protocol, OpenTSDN Telnet Protocol, and OpenTSDB JSON Protocol. TDengine TSDB also seamlessly integrates with data collectors like Telegraf and Prometheus.
- Data Querying: In addition to standard SQL query syntax, TDengine TSDB includes time-series extensions such as downsampling and windowing and functions such as cumulative sum and time-weighted average to better meet the needs of time-series data processing. TDengine TSDB also supports user-defined functions (UDF), which can be written in C or Python.
- Read Caching: TDengine TSDB uses a time-driven first-in, first-out (FIFO) cache management strategy, keeping the most recent data in the cache. This makes it easy and fast to access the real-time status of any metric without the need for other caching tools like Redis, simplifying system architecture and reducing operational costs.
- Stream Processing: TDengine TSDB's built-in stream processing engine provides the capability to process data streams in real-time as they are written, supporting not only continuous queries but also event-driven stream processing. This lightweight but optimized solution can return results in milliseconds even during high-throughput data ingestion.
- Data Subscription: TDengine TSDB includes data subscription out of the box, eliminating the need to deploy other complex products to provide this critical feature. You can define topics in SQL, subscribing to a query, supertable, or database, and use a Kafka-like API to consume these topics in your applications.
- Visualization and BI: Through its REST API and standard JDBC and ODBC interfaces, TDengine TSDB seamlessly integrates with leading platforms like Grafana, Power BI, and Seeq.
- Clustering: TDengine TSDB supports clustered deployment so that you can add nodes to scale your system and increase processing capacity. At the same time, it provides high availability through multi-replica technology and supports Kubernetes deployment. It also offers various operational tools to facilitate system administrators in managing and maintaining robust cluster operations.
- Data Migration: TDengine TSDB provides various convenient data import and export functions, including script file import/export, data file import/export, and the taosdump tool.
- Client Libraries: TDengine TSDB offers client libraries for a variety of different programming languages, including Java, Python, and C/C++, so that you can build custom applications in your favorite language. Sample code that you can copy and paste into your apps is also provided to make the development process even easier.
- O&M Tools: You can use the interactive command-line interface (CLI) for managing clusters, checking system status, and performing ad hoc queries. The stress-testing tool taosBenchmark is a quick way to generate sample data and test the performance of TDengine TSDB. And the TDengine Explorer GUI simplifies the operations and management process.
- Data Security: With TDengine TSDB-Enterprise, you can implement fine-grained access controls with rich user and permissions management features. IP whitelisting helps you control which accounts can access your cluster from which servers, and audit logs record sensitive operations. In TDengine TSDB-Enterprise, you can also configure encryption in transit on the server level and encryption at rest on the database level, which is transparent to operations and has minimal impact on performance.
- Zero-Code Data Connectors: TDengine TSDB-Enterprise includes zero-code connectors for industrial data protocols like MQTT and OPC, traditional data historians like AVEVA PI System and Wonderware Historian, relational databases like Oracle Database and SQL Server, and other time-series databases like InfluxDB and OpenTSDB. With these connectors, you can synchronize or migrate diverse time-series datasets to TDengine TSDB in the GUI without touching a line of code.
How TDengine TSDB Benefits You
With its high performance, standard SQL support, and component integration, TDengine TSDB can reduce your total cost of data operations:
- Industry-leading performance: TDengine TSDB significantly outperforms other time-series databases with up to 16 times faster ingestion and over 100 times higher query performance than InfluxDB or TimescaleDB while requiring fewer storage resources. Because TDengine TSDB ingests data faster, stores data more efficiently, and responds to queries more quickly, it uses fewer CPU and storage resources and adds less to your bills.
- Easy to use with no learning costs: TDengine TSDB is easier to use than other time-series database solutions and does not require specialized training. This is because TDengine TSDB supports standard SQL, is easy to integrate with third-party tools, and comes with client libraries for various programming languages, including sample code.
- Simplified, fully integrated solution: By including stream processing, caching, and data subscription as built-in components at no extra cost, TDengine TSDB eliminates the need to deploy third-party products just to process time-series data. Its components are simple, easy to use, and purpose-built to process time-series data.
TDengine TSDB Ecosystem
With its open ecosystem, TDengine TSDB allows you the freedom to construct the data stack that is best for your business. Its support for standard SQL, zero-code connectors for a wide range of industrial protocols and data solutions, and seamless integration with visualization, analytics, and business intelligence (BI) applications make it easy to fit TDengine TSDB into your infrastructure.
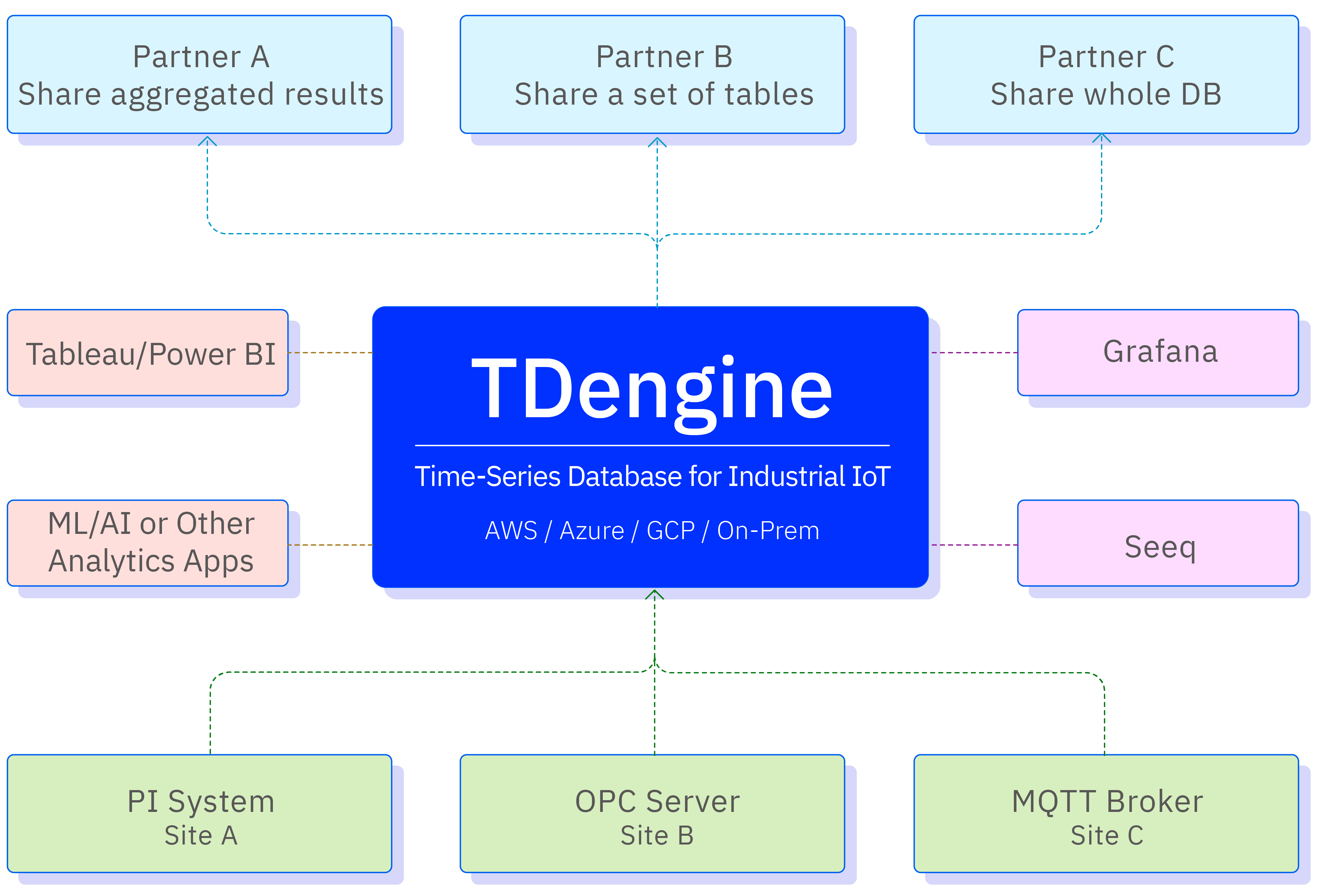
As shown in the figure, TDengine TSDB acts as the central source of truth in an industrial data ecosystem, ingesting data from a variety of sources and sharing that data with business applications and stakeholders.
Application Scenarios
TDengine TSDB is the only time-series database purpose-built for industrial scenarios and is fully capable of storing and processing the massive, high-frequency datasets generated by a range of industries, especially the following:
TDengine TSDB can also form the core component of a data stack to enable the following industrial applications: