Stream Processing Engine
Stream Processing Architecture
The architecture of TDengine's stream processing is illustrated in the following diagram. When a user inputs SQL to create a stream, first, the SQL is parsed on the client side, generating the logical execution plan and its related attribute information required for stream processing execution. Next, the client sends this information to the mnode. The mnode uses the vgroups information from the database where the data source (super) table is located, dynamically converts the logical execution plan into a physical execution plan, and further generates a Directed Acyclic Graph (DAG) for the stream task. Finally, the mnode initiates a distributed transaction, distributing the task to each vgroup, thereby starting the entire stream processing process.
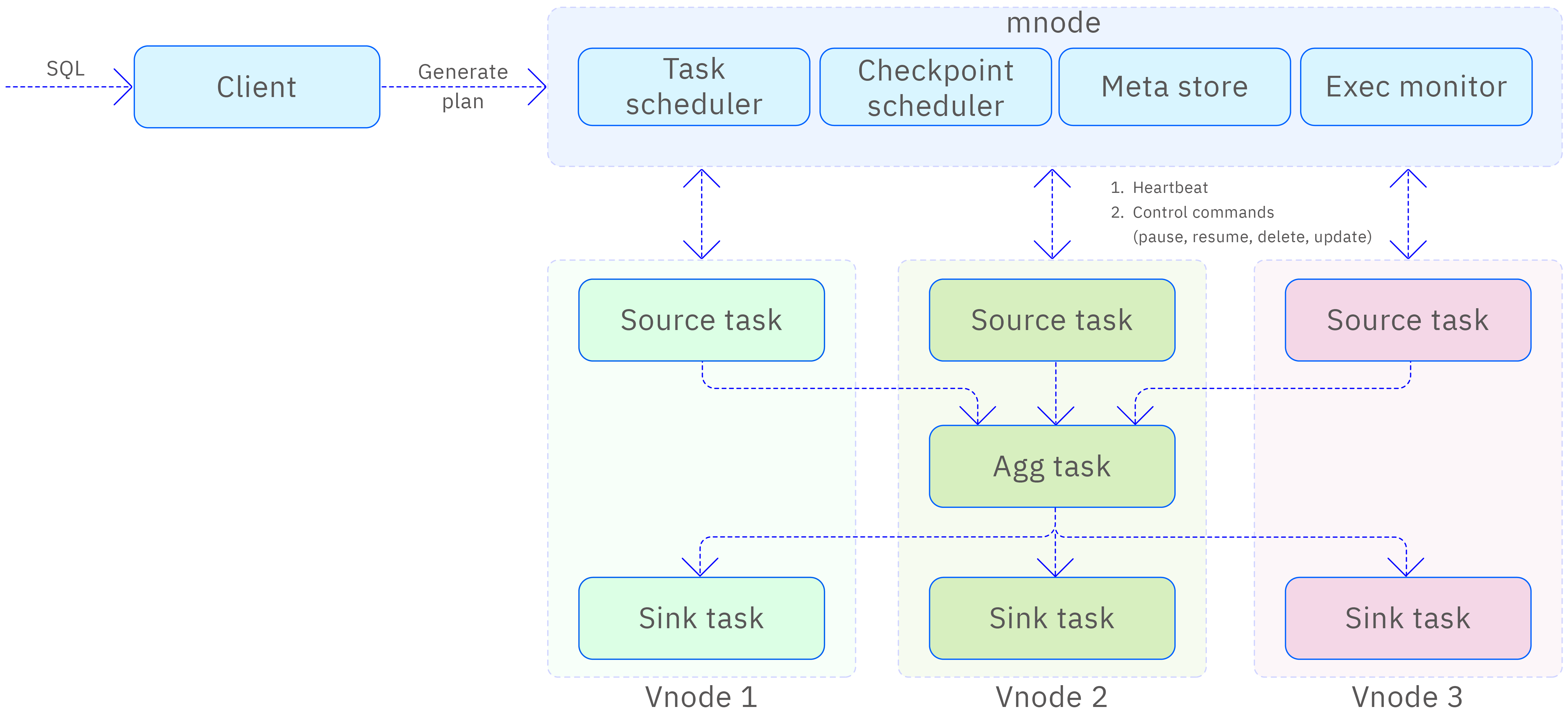
The mnode contains the following four logical modules related to stream processing.
- Task scheduling, responsible for converting the logical execution plan into a physical execution plan and distributing it to each vnode.
- Meta store, responsible for storing metadata information of stream processing tasks and the corresponding DAG information of stream tasks.
- Checkpoint scheduling, responsible for periodically generating checkpoint transactions and distributing them to each source task.
- Exec monitoring, responsible for receiving reported heartbeats, updating the execution status of each task in the mnode, and periodically monitoring the execution status of checkpoints and DAG change information.
Additionally, the mnode also plays a crucial role in issuing control commands to stream processing tasks, including but not limited to pausing, resuming execution, deleting stream tasks, and updating upstream and downstream information of stream tasks.
On each vnode, at least two stream tasks are deployed: one is the source task, which is responsible for reading data from the WAL (and from the TSDB when necessary) for subsequent task processing and distributing the processed results to downstream tasks; the other is the sink task, which is responsible for writing the received data into the vnode it resides in. To ensure the stability of the data flow and the scalability of the system, each sink task is equipped with flow control capabilities to adjust the data writing speed according to actual conditions.
Basic Concepts
Stateful Stream Processing
The stream processing engine has powerful scalar function computing capabilities, processing data that is independent in time-series without needing to retain intermediate states. This means that for all input data, the engine can perform fixed transformations, such as simple numerical addition, and directly output results.
At the same time, the stream processing engine also supports data aggregation calculations, which require maintaining intermediate states during execution. For example, to calculate the daily running time of equipment, since the statistical period may span multiple days, the application must continuously track and update the current running state until the end of the statistical period to obtain accurate results. This is a typical application scenario of stateful stream processing, which requires the engine to track and manage intermediate states during execution to ensure the accuracy of the final results.
Write-Ahead Logging
When data is written into TDengine, it is first stored in a WAL file. Each vnode has its own WAL file, which saves data in the order it arrives. Since the WAL file retains the order of data arrival, it becomes an important data source for stream processing. Additionally, the WAL file has its own data retention policy, controlled by database parameters, and data exceeding the retention duration will be cleared from the WAL file. This design ensures data integrity and system reliability while providing a stable data source for stream processing.
Event-Driven
In the system, an event refers to a change or transition in state. In the stream processing architecture, the event that triggers the stream processing process is the write message of the (super) table data. At this stage, the data may not have been fully written into the TSDB, but is negotiated among multiple replicas and finally reaches a consensus.
Stream processing operates in an event-driven mode, with its data source not coming directly from the TSDB, but from the WAL. Once data is written into the WAL file, it is extracted and added to the processing queue, waiting for further processing by the stream processing task. This method of triggering the stream processing engine immediately after data writing ensures that data is processed promptly upon arrival and that the processing results are stored in the target table in the shortest possible time.
Time
In the field of stream processing, time is a crucial concept. TDengine's stream processing involves three key time concepts: event time, write time, and processing time.
- Event Time: This is the primary timestamp (also known as Primary Timestamp) in time-series data, usually provided by the sensor generating the data or the gateway reporting the data, used to accurately mark the moment the record is generated. Event time is a decisive factor in updating and pushing stream processing results.
- Ingestion Time: Refers to the moment the record is written into the database. Ingestion time is generally independent of event time and is usually later than or equal to event time (unless, for specific purposes, the user has written data for a future moment).
- Processing Time: This is the time point when the stream processing engine starts processing data written into the WAL file. For scenarios that have set the max_delay option to control the return strategy of stream processing results, processing time directly determines the time of result return. It is worth noting that in the at_once and window_close computation trigger modes, data is immediately written into the source task's input queue and begins computation as soon as it arrives at the WAL file.
The distinction of these time concepts ensures that stream processing can accurately process time-series data and adopt corresponding processing strategies based on the characteristics of different time points.
Time Window Aggregation
TDengine's stream processing feature allows data to be divided into different time windows based on the event time of the records. By applying specified aggregation functions, the aggregate results within each time window are computed. When new records arrive in a window, the system triggers an update of the corresponding window's aggregate results and delivers the updated results to downstream stream processing tasks according to a pre-set push strategy.
When the aggregate results need to be written into a preset supertable, the system first generates the corresponding subtable names based on grouping rules, then writes the results into the corresponding subtables. It is worth mentioning that the time window division strategy in stream processing is consistent with the window generation and division strategy in batch queries, ensuring consistency and efficiency in data processing.
Out-of-Order Handling
Due to complex factors such as network transmission and data routing, the data written into the database may not maintain the monotonic increase of event time. This phenomenon, known as out-of-order writing, occurs when non-monotonically increasing data appears during the writing process.
Whether out-of-order writing affects the stream processing results of the corresponding time window depends on the watermark parameter set when creating the stream processing task and the configuration of the ignore expired parameter. These two parameters work together to determine whether to discard these out-of-order data or to include them and incrementally update the calculation results of the corresponding time window. Through this method, the system can flexibly handle out-of-order data while maintaining the accuracy of stream processing results, ensuring data integrity and consistency.
Stream Processing Tasks
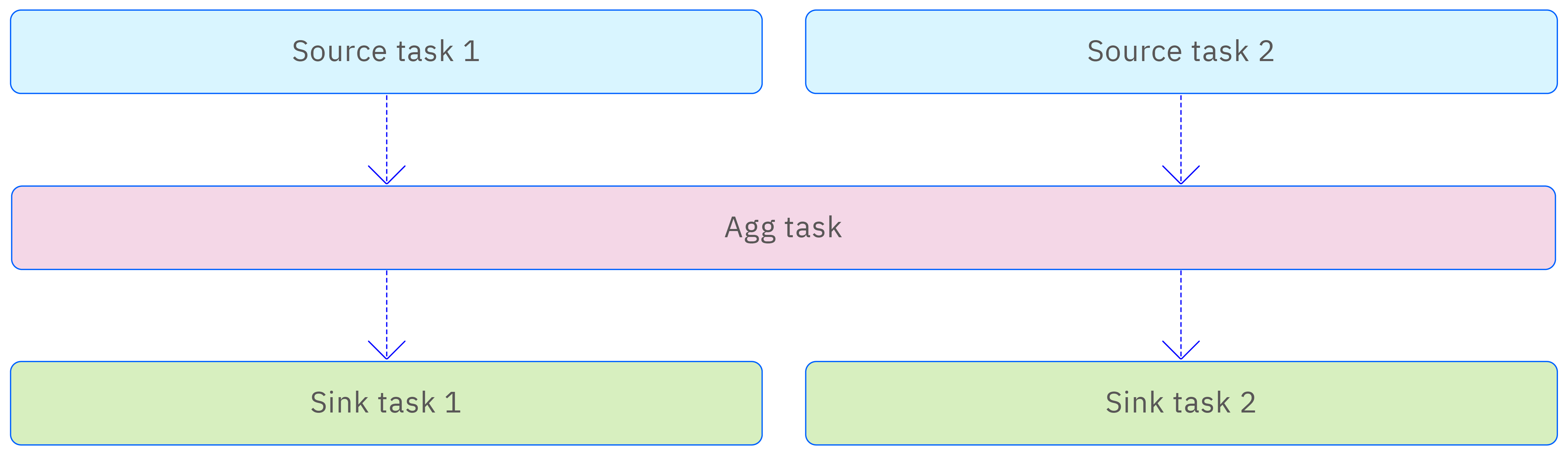
Each activated stream processing instance consists of multiple stream tasks distributed across different vnodes. These stream tasks show similarities in their overall architecture, each containing an all-memory resident input queue and output queue, a time-series data executor system, and a storage system for storing local state, as shown in the following diagram. This design ensures high performance and low latency of stream processing tasks, while also providing good scalability and fault tolerance.

Depending on the different roles of stream tasks, they can be divided into 3 categories—source task, agg task, and sink task.
source task
Stream processing data processing begins with reading data from local WAL files, which are then locally computed on the node. The source task follows the natural order of data arrival, sequentially scanning the WAL files and filtering out data that meets specific requirements. Subsequently, the source task processes these time-series data in order. Therefore, no matter how many vnodes the data source (super) table is distributed across, an equal number of source tasks will be deployed across the cluster. This distributed processing approach ensures parallel processing of data and efficient utilization of cluster resources.
agg task
The downstream task of the source task is to receive the aggregated results from the source task and further summarize these results to produce the final output. In clusters configured with snode, the agg task is prioritarily executed on the snode to utilize its storage and processing capabilities. If there is no snode in the cluster, mnode will randomly select a vnode to schedule the execution of the agg task. It is worth noting that the agg task is not always necessary. For stream processing scenarios that do not involve window aggregation (e.g., those only involving scalar operations, or aggregation stream processing in a database with only one vnode), the agg task will not appear. In this case, the topology of stream processing will be simplified to only include two levels of stream processing tasks, namely the source task and the downstream task that directly outputs results.
sink task
The sink task is responsible for receiving the output results from the agg task or source task and properly writing them back to the local vnode, thus completing the data write-back process. Similar to the source task, each result (super) table distributed across vnodes will be equipped with a dedicated sink task. Users can adjust the throughput of the sink task through configuration parameters to meet different performance needs.
The above three types of tasks each play their roles in the stream processing architecture, distributed at different levels. Clearly, the number of source tasks directly depends on the number of vnodes, with each source task independently handling the data in its vnode without interference from other source tasks, and there are no sequential constraints. However, it is worth noting that if the final stream processing results converge to one table, then only one sink task will be deployed on the vnode where that table is located. The collaborative relationship between these three types of tasks is shown in the following diagram, together forming the complete execution process of stream processing tasks.
Stream Processing Nodes
snode is a standalone taosd process specifically for stream processing services, dedicated to deploying agg tasks. Snode not only has local state management capabilities but also incorporates remote backup data functionality. This allows snode to collect and store checkpoint data scattered across various vgroups and remotely download this data to the node restarting stream processing when needed, thus ensuring the consistency of stream processing states and the integrity of data.
Status and Fault Tolerance
Checkpoints
During the stream processing process, the system uses a distributed checkpoint mechanism to periodically (default every 3 minutes) save the state of internal operators within each task. These snapshots of states are called checkpoints. The operation of generating checkpoints is only associated with processing time and is independent of event time.
Assuming all stream tasks are running normally, mnode periodically initiates transactions to generate checkpoints and distributes these transactions to the top-level tasks of each stream. The messages handling these transactions then enter the data processing queue.
The checkpoint generation method in TDengine is consistent with mainstream stream processing engines in the industry, with each generated checkpoint containing complete operator state information. For each task, checkpoint data is retained in only one copy on the node where the task is running, completely independent from the replica settings of the time-series data storage engine. Notably, the metadata information of stream tasks also adopts a multi-replica saving mechanism and is included in the management scope of the time-series data storage engine. Therefore, when executing stream processing tasks on a multi-replica cluster, their metadata information will also achieve multi-replica redundancy.
To ensure the reliability of checkpoint data, the TDengine stream processing engine provides the functionality to remotely backup checkpoint data, supporting asynchronous uploading of checkpoint data to remote storage systems. Thus, even if the locally retained checkpoint data is damaged, it is possible to download the corresponding data from the remote storage system and restart stream processing on a new node, continuing the computation tasks. This measure further enhances the fault tolerance and data security of the stream processing system.
State Storage Backend
The computational state information of operators in stream tasks is persistently stored locally on disk as files.
Memory Management
Each non-sink task is equipped with corresponding input and output queues, while sink tasks only have input queues and no output queues. The data capacity limit for both types of queues is set to 60MB, dynamically occupying storage space according to actual needs, and not occupying any storage space when the queue is empty. Additionally, agg tasks also consume a certain amount of memory space when saving computational states internally. This memory usage can be adjusted by setting the parameter streamBufferSize, which controls the size of the window state cache in memory, with a default value of 128MB. The parameter maxStreamBackendCache limits the maximum storage space occupied by backend storage in memory, also defaulting to 128MB, and users can adjust it to any value between 16MB and 1024MB as needed.
Flow Control
The stream processing engine implements a flow control mechanism in sink tasks to optimize data writing performance and prevent excessive resource consumption. This mechanism mainly controls the flow through the following two metrics:
- Number of write operation calls per second: sink tasks are responsible for writing processing results to their respective vnode. The upper limit of this metric is fixed at 50 times per second to ensure the stability of write operations and the reasonable allocation of system resources.
- Data throughput per second: By configuring the parameter
streamSinkDataRate, users can control the amount of data written per second, with an adjustable range from 0.1MB/s to 5MB/s, and a default value of 2MB/s. This means that for each vnode, each sink task can write up to 2MB of data per second.
The flow control mechanism in sink tasks not only prevents overflow of the synchronization negotiation buffer due to high-frequency writing in multi-replica scenarios but also avoids excessive accumulation of data in the writing queue, consuming a lot of memory space. This effectively reduces the memory usage of the input queue. Thanks to the backpressure mechanism applied in the overall computing framework, sink tasks can directly feedback the effects of flow control to the top-level tasks, thereby reducing the occupancy of computing resources by stream processing tasks, avoiding excessive resource consumption, and ensuring the overall stability and efficiency of the system.
Backpressure Mechanism
TDengine's stream processing framework is deployed on multiple computing nodes. To coordinate the execution progress of tasks on these nodes and prevent upstream tasks from continuously pouring in data causing downstream tasks to overload, the system implements a backpressure mechanism both within tasks and between upstream and downstream tasks.
Internally, the backpressure mechanism is implemented by monitoring the full load condition of the output queue. Once the output queue of a task reaches its storage limit, the current computing task will enter a waiting state, pausing the processing of new data until there is enough space in the output queue to accommodate new computational results, and then resuming the data processing flow.
Between upstream and downstream tasks, the backpressure mechanism is triggered through message passing. When the input queue of a downstream task reaches its storage limit (i.e., the inflow of data into the downstream task continuously exceeds its maximum processing capacity), the upstream task will receive a full load signal from the downstream task. At this point, the upstream task will appropriately pause its computation processing until the downstream task has processed the data and allows the distribution of data to continue, at which point the upstream task will resume computation. This mechanism effectively balances the data flow between tasks, ensuring the stability and efficiency of the entire stream processing system.