

Architecture
Cluster and Basic Logical Units
TDengine is designed based on the assumption that a single hardware or software system is unreliable, and that no single computer can provide sufficient computing power and storage capacity to handle massive amounts of data. Therefore, from the first day of its development, TDengine has been designed with a distributed and highly reliable architecture that supports horizontal scaling. This ensures that the system's availability and reliability are not affected by hardware failures or software errors in any single or multiple servers. Additionally, through node virtualization and load balancing technology, TDengine can efficiently utilize the computing and storage resources in a heterogeneous cluster to reduce hardware investment.
Main Logical Units
The logical structure diagram of the TDengine distributed architecture is as follows:
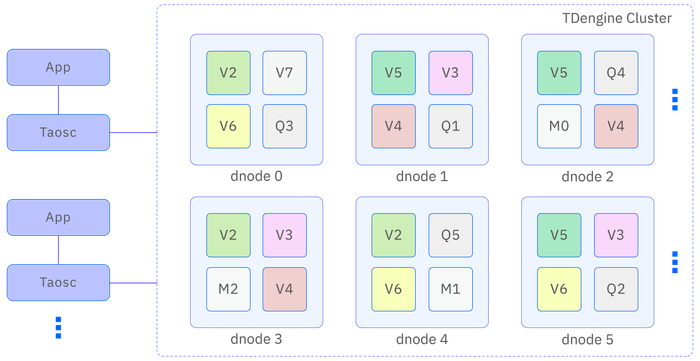
A complete TDengine system runs on one to several physical nodes. Logically, it includes data nodes (dnode), TDengine application drivers (taosc), and applications (app). There are one or more data nodes in the system, which form a cluster (cluster). Applications interact with the TDengine cluster through the API of taosc. Below is a brief introduction to each logical unit.
Physical Node (pnode)
A pnode is an independent computer with its own computing, storage, and networking capabilities, which can be a physical machine, virtual machine, or Docker container with an OS installed. Physical nodes are identified by their configured FQDN (Fully Qualified Domain Name). TDengine relies entirely on the FQDN for network communication.
Data Node (dnode)
A dnode is a running instance of the TDengine server-side execution code taosd on a physical node. At least one dnode is required to ensure the normal operation of a TDengine system. Each dnode contains zero to several logical virtual nodes (vnode), but management nodes, elastic computing nodes, and stream computing nodes each have 0 or 1 logical instance.
The unique identifier of a dnode in the TDengine cluster is determined by its instance's endpoint (EP). The endpoint is a combination of the FQDN and the configured network port of the physical node where the dnode is located. By configuring different ports, a pnode (whether it is a physical machine, virtual machine, or Docker container) can run multiple instances, i.e., have multiple dnodes.
Virtual Node (vnode)
To better support data sharding, load balancing, and prevent data overheating or skew, TDengine introduces the concept of vnode (virtual node). Virtual nodes are virtualized into multiple independent vnode instances (as shown in the architecture diagram above, such as V2, V3, V4, etc.), each vnode is a relatively independent working unit responsible for storing and managing a portion of time-series data.
Each vnode has its own running thread, memory space, and persistent storage path, ensuring data isolation and efficient access. A vnode can contain multiple tables (i.e., data collection points), which are physically distributed across different vnodes to achieve even data distribution and load balancing.
When a new database is created in the cluster, the system automatically creates the corresponding vnode for that database. The number of vnodes that can be created on a dnode depends on the hardware resources of the physical node where the dnode is located, such as CPU, memory, and storage capacity. Note that a vnode can only belong to one database, but a database can contain multiple vnodes.
In addition to storing time-series data, each vnode also stores the schema information and tag values of the tables it contains, which are crucial for data querying and management.
Internally within the cluster, a vnode is uniquely identified by the endpoint of its belonging dnode and its vgroup ID. Management nodes are responsible for creating and managing these vnodes, ensuring they operate normally and work collaboratively.
Management Node (mnode)
The mnode (management node) is the core logical unit in the TDengine cluster, responsible for monitoring and maintaining the operational status of all dnodes and implementing load balancing between nodes (as shown in Figure 15-1, M1, M2, M3). As the storage and management center for metadata (including users, databases, supertables, etc.), mnode is also known as MetaNode.
To enhance the cluster's high availability and reliability, the TDengine cluster allows for multiple (up to 3) mnodes. These mnodes automatically form a virtual mnode group, sharing management responsibilities. Mnodes support multiple replicas and use the Raft consistency protocol to ensure data consistency and operation reliability. In the mnode cluster, any data update operation must be performed on the leader node.
The first node of the mnode cluster is automatically created during cluster deployment, while the creation and deletion of other nodes are manually completed by users through SQL. Each dnode can have at most one mnode, uniquely identified by the endpoint of the dnode to which it belongs.
To achieve information sharing and communication within the cluster, each dnode automatically obtains the endpoint of the dnode where all mnodes in the entire cluster are located through an internal message exchange mechanism.
Compute Node (qnode)
qnode (compute node) is a virtual logical unit in the TDengine cluster responsible for executing query computation tasks and also handles show commands based on system tables. To improve query performance and parallel processing capabilities, multiple qnodes can be configured in the cluster, which are shared across the entire cluster (as shown in Q1, Q2, Q3 in Figure 15-1).
Unlike dnode, qnode is not bound to a specific database, meaning a qnode can handle query tasks from multiple databases simultaneously. Each dnode can have at most one qnode, uniquely identified by the endpoint of the dnode to which it belongs.
When a client initiates a query request, it first interacts with mnode to obtain the current list of available qnodes. If there are no available qnodes in the cluster, the computation task will be executed in vnode. When executing a query, the scheduler allocates one or more qnodes to complete the task according to the execution plan. qnode can obtain the required data from vnode and send the computation results to other qnodes for further processing.
By introducing independent qnodes, TDengine achieves separation of storage and computation.
Stream Compute Node (snode)
snode (stream compute node) is a virtual logical unit in the TDengine cluster specifically responsible for handling stream computing tasks (as shown in the architecture diagram S1, S2, S3). To meet the needs of real-time data processing, multiple snodes can be configured in the cluster, which are shared across the entire cluster.
Similar to dnode, snode is not bound to a specific stream, meaning an snode can handle computation tasks from multiple streams simultaneously. Each dnode can have at most one snode, uniquely identified by the endpoint of the dnode to which it belongs.
When a stream computing task needs to be executed, mnode schedules available snodes to complete these tasks. If there are no available snodes in the cluster, the stream computing task will be executed in vnode.
By centralizing stream computing tasks in snodes, TDengine achieves separation of stream computing and batch computing, thereby enhancing the system's capability to handle real-time data.
Virtual Node Group (VGroup)
vgroup (virtual node group) is a logical unit composed of vnodes from different dnodes. These vnodes use the Raft consistency protocol to ensure high availability and reliability of the cluster. In vgroup, write operations can only be performed on the leader vnode, while data is asynchronously replicated to other follower vnodes, thus retaining data replicas across multiple physical nodes.
The number of vnodes in a vgroup determines the number of data replicas. To create a database with N replicas, the cluster must contain at least N dnodes. The number of replicas can be specified during database creation through the replica parameter, with a default value of 1. By utilizing TDengine's multi-replica feature, enterprises can forego expensive traditional storage devices like disk arrays while still achieving high data reliability.
vgroup is created and managed by mnode, and is assigned a unique cluster ID, the vgroup ID. If two vnodes have the same vgroup ID, it means they belong to the same group, and their data are backups of each other. Notably, the number of vnodes in a vgroup can be dynamically adjusted, but the vgroup ID remains constant, even if the vgroup is deleted, its ID will not be recycled or reused.
Through this design, TDengine ensures data security while achieving flexible replica management and dynamic expansion capabilities.
taosc
taosc (application driver) is a driver provided by TDengine for application programs, responsible for handling the interface interaction between applications and the cluster. taosc provides native interfaces for C/C++ languages and is embedded in connection libraries for various programming languages such as JDBC, C#, Python, Go, Node.js, thus supporting these programming languages in interacting with the database.
Applications communicate with the entire cluster through taosc rather than directly connecting to dnodes in the cluster. taosc is responsible for obtaining and caching metadata, forwarding write and query requests to the correct dnode, and performing final aggregation, sorting, filtering, etc., before returning results to the application. For interfaces such as JDBC, C/C++, C#, Python, Go, Node.js, taosc runs on the physical node where the application is located.
Additionally, taosc can interact with taosAdapter to support a fully distributed RESTful interface. This design allows TDengine to support multiple programming languages and interfaces in a unified manner while maintaining high performance and scalability.
Communication Between Nodes
Communication Methods
Within a TDengine cluster, communication between various dnodes as well as between application drivers and dnodes is implemented through TCP. This method ensures the stability and reliability of data transmission.
To optimize network transmission performance and ensure data security, TDengine automatically compresses and decompresses data according to the configuration to reduce network bandwidth usage. Additionally, TDengine supports digital signatures and authentication mechanisms to ensure the integrity and confidentiality of data during transmission.
FQDN Configuration
In the TDengine cluster, each dnode can have one or more FQDNs. To specify the FQDN of a dnode, you can configure the fqdn parameter in the taos.cfg configuration file. If not explicitly specified, the dnode will automatically obtain the hostname of its computer as the default FQDN.
Although it is theoretically possible to set the FQDN parameter in taos.cfg to an IP address, this practice is not recommended by the official documentation. Because IP addresses may change with network environment changes, this could cause the cluster to malfunction. When using FQDNs, it is necessary to ensure that the DNS service is functioning properly, or that the hosts file is correctly configured on the nodes and application nodes to resolve the FQDN to the corresponding IP address. Additionally, to maintain good compatibility and portability, the length of the fqdn parameter value should be kept within 96 characters.
Port Configuration
In the TDengine cluster, the port used by each dnode to provide external services is determined by the serverPort configuration parameter. By default, this parameter is set to 6030. By adjusting the serverPort parameter, you can flexibly configure the external service port of the dnode to meet different deployment environments and security policies.
External Cluster Connections
The TDengine cluster can accommodate single, multiple, or even thousands of data nodes. Applications only need to connect to any data node in the cluster. This design simplifies the interaction process between applications and the cluster, enhancing the system's scalability and usability.
When using the TDengine CLI to start taos, you can specify the connection information for a dnode with the following options:
- -h: Used to specify the FQDN of the dnode. This is a required item, used to inform the application which dnode to connect to.
- -P: Used to specify the port of the dnode. This is an optional item; if not specified, the TDengine configuration parameter serverPort will be used as the default.
In this way, applications can flexibly connect to any dnode in the cluster without having to worry about the specific topology of the cluster.
Internal Cluster Communication
In the TDengine cluster, communication between various dnodes is carried out through TCP. When a dnode starts, it first obtains the endpoint information of the mnode located dnode. Subsequently, the newly started dnode establishes a connection with the mnode in the cluster and exchanges information.
This process ensures that the dnode can join the cluster in a timely manner and maintain synchronization with the mnode, thus being able to receive and execute cluster-level commands and tasks. Through TCP connections, dnodes and mnodes can reliably transfer data, ensuring the stable operation and efficient data processing capabilities of the cluster.
Steps to obtain the mnode endpoint information are as follows:
- Step 1: Check if the dnode.json file exists; if it does not exist or cannot be opened normally to obtain mnode endpoint information, proceed to Step 2.
- Step 2: Check the configuration file taos.cfg, obtain the node configuration parameters firstEp, secondEp (these two parameters can specify nodes without mnode; in such cases, when the node is connected, it will try to redirect to the mnode node); if firstEP, secondEp do not exist, or if these two parameters are not in taos.cfg, or if the parameters are invalid, proceed to Step 3.
- Step 3: Set your own endpoint as the mnode endpoint and operate independently.
After obtaining the mnode endpoint list, the dnode initiates a connection; if successful, it joins the working cluster; if not, it tries the next one in the mnode endpoint list. If all attempts fail, it sleeps for a few seconds before trying again.
Selection of Mnode
In the TDengine cluster, mnode is a logical concept and does not correspond to an entity that executes code independently. In fact, the functionality of the mnode is managed by the server-side taosd process.
During the cluster deployment phase, the first dnode automatically assumes the role of mnode. Subsequently, users can create or delete additional mnodes in the cluster through SQL to meet the needs of cluster management. This design makes the number and configuration of mnodes highly flexible, allowing adjustments based on actual application scenarios.
Joining of New Data Nodes
Once a dnode in the TDengine cluster is started and running, the cluster has basic operational capabilities. To expand the scale of the cluster, new nodes can be added by following these two steps:
- Step 1, first use the TDengine CLI to connect to an existing dnode. Next, execute the create dnode command to add a new dnode. This process will guide the user through the configuration and registration process of the new dnode.
- Step 2, set the firstEp and secondEp parameters in the configuration file taos.cfg of the newly added dnode. These two parameters should point to the endpoints of any two active dnodes in the existing cluster. This ensures that the new dnode can correctly join the cluster and communicate with the existing nodes.
Redirection
In the TDengine cluster, whether it is a newly started dnode or taosc, they first need to establish a connection with the mnode in the cluster. However, users usually do not know which dnode is running the mnode. To solve this problem, TDengine uses a clever mechanism to ensure the correct connection between them.
Specifically, TDengine does not require the dnode or taosc to directly connect to a specific mnode. Instead, they only need to initiate a connection to any working dnode in the cluster. Since each active dnode maintains a list of the current running mnode endpoints, this connection request will be forwarded to the appropriate mnode.
When a connection request from a newly started dnode or taosc is received, if the current dnode is not an mnode, it will immediately reply to the requester with the mnode endpoint list. After receiving this list, the taosc or the newly started dnode can try to establish a connection with the mnode based on this list.
Furthermore, to ensure that all nodes in the cluster can timely receive the latest mnode endpoint list, TDengine uses an inter-node message exchange mechanism. When the mnode endpoint list changes, the related updates are quickly propagated to each dnode through messages, thereby notifying the taosc.
A typical message flow
To explain the relationship between vnode, mnode, taosc, and applications, as well as the roles they play, the process of a typical operation of writing data is analyzed below.

- The application initiates a request to insert data through JDBC or other API interfaces.
- taosc checks the cache to see if it has the vgroup-info of the database where the table is located. If it does, go directly to step 4. If not, taosc sends a get vgroup-info request to mnode.
- mnode returns the vgroup-info of the database where the table is located to taosc. Vgroup-info includes the distribution information of the database's vgroup (vnode ID and the End Point of the dnode where it is located, if the number of replicas is N, there are N sets of End Points), and also includes the hash range of the data tables stored in each vgroup. If taosc does not receive a response from mnode and there are multiple mnodes, taosc will send a request to the next mnode.
- taosc continues to check the cache to see if it has the meta-data of the table. If it does, go directly to step 6. If not, taosc sends a get meta-data request to vnode.
- vnode returns the meta-data of the table to taosc. Meta-data contains the schema of the table.
- taosc sends an insertion request to the leader vnode.
- After inserting the data, vnode responds to taosc, indicating that the insertion was successful. If taosc does not receive a response from vnode, taosc will assume that the node has gone offline. In this case, if the database being inserted has multiple replicas, taosc will send an insertion request to the next vnode in the vgroup.
- taosc notifies the APP that the write was successful.
For step 2, when taosc starts, it does not know the End Point of mnode, so it will directly send a request to the cluster's external service End Point configured. If the dnode receiving this request does not have mnode configured, the dnode will inform the mnode EP list in the reply message, so taosc will resend the request to get meta-data to the new mnode's EP.
For steps 4 and 6, without cache, taosc does not know who the leader in the virtual node group is, so it assumes the first vnodeID is the leader and sends the request to it. If the vnode receiving the request is not the leader, it will inform who the leader is in the reply, so taosc will send the request to the suggested leader vnode. Once a successful insertion response is received, taosc will cache the leader node's information.
The above describes the process of inserting data, and the process for querying and computing is exactly the same. Taosc encapsulates and shields all these complex processes, making them imperceptible and requiring no special handling for applications.
Through the caching mechanism of taosc, it is only necessary to access mnode the first time a table is operated on, so mnode will not become a bottleneck in the system. However, since the schema may change and the vgroup may change (such as during load balancing), taosc will interact with mnode periodically and automatically update the cache.
Storage Model and Data Partitioning, Sharding
Storage Model
The data stored by TDengine includes collected time-series data as well as metadata related to databases and tables, label data, etc. These data are specifically divided into three parts:
- Time-Series data: Time series data is the core storage object of TDengine, stored in vnode. Time series data consists of data, head, sma, and stt files, which together form the complete storage structure of the time-series data. Due to the characteristics of time series data, which involve large volumes and query requirements depending on specific application scenarios, TDengine adopts a model of "one table per data collection point" to optimize storage and query performance. In this model, data within a time period is stored continuously, and writing to a single table is a simple append operation, allowing multiple records to be retrieved in one read. This design ensures optimal performance for both writing and querying operations at a single data collection point.
- Table metadata: Includes label information and Table Schema information, stored in the meta files within vnode, supporting four standard operations: create, read, update, delete. With a large amount of data, if there are N tables, there are N records, thus LRU storage is used, supporting indexing of label data. TDengine supports multi-core and multi-threaded concurrent queries. As long as there is enough memory, metadata is stored entirely in memory, and filtering results of millions of label data can be returned in milliseconds. In cases of insufficient memory resources, it can still support fast querying of tens of millions of tables.
- Database metadata: Stored in mnode, includes information about system nodes, users, DBs, STable Schema, etc., supporting four standard operations: create, read, update, delete. This part of the data is not large in volume and can be entirely stored in memory, and since the client has caching, the query volume is also not large. Therefore, although the current design is centralized storage management, it does not constitute a performance bottleneck.
Compared to traditional NoSQL storage models, TDengine completely separates label data from time-series data, which has two major advantages:
- Significantly reduces the redundancy of label data storage. In common NoSQL databases or time-series databases, a Key-Value storage model is usually adopted, where the Key includes a timestamp, device ID, and various labels. This causes each record to carry a large amount of repetitive label information, thus wasting valuable storage space. Moreover, if an application needs to add, modify, or delete labels on historical data, it must traverse the entire dataset and rewrite it, which is extremely costly. In contrast, by separating label data from time series data, TDengine effectively avoids these problems, greatly reducing storage space waste and lowering the cost of label data operations.
- Achieves extremely efficient aggregation queries across multiple tables. When performing aggregation queries across multiple tables, TDengine first identifies the tables that meet the label filtering criteria, then finds the corresponding data blocks for these tables. This method significantly reduces the size of the dataset that needs to be scanned, thereby greatly improving query efficiency. This optimization strategy allows TDengine to maintain efficient query performance when handling large-scale time-series data, meeting the data analysis needs of various complex scenarios.
Data Sharding
In managing massive data, to achieve horizontal scaling, data sharding and partitioning strategies are usually necessary. TDengine implements data sharding through vnode and partitions time-series data by dividing data files by time period.
Vnode is responsible not only for writing, querying, and computing time-series data but also plays important roles in load balancing, data recovery, and supporting heterogeneous environments. To achieve these goals, TDengine splits a dnode based on its computing and storage resources into multiple vnodes. The management of these vnodes is completely transparent to the application, automatically handled by TDengine.
For a single data collection point, regardless of the volume of data, a vnode has sufficient computing and storage resources to cope (for example, if a 16B record is generated every second, the raw data generated in a year is less than 0.5GB). Therefore, TDengine stores all data for a table (i.e., a data collection point) in one vnode, avoiding the dispersion of data from the same collection point across two or more dnodes. At the same time, a vnode can store data from multiple data collection points (tables), with a maximum capacity of up to 1 million tables. In design, all tables in a vnode belong to the same database.
TDengine 3.0 uses a consistent hashing algorithm to determine the vnode for each table. When creating a database, the cluster immediately allocates a specified number of vnodes and determines the range of tables each vnode is responsible for. When creating a table, the cluster calculates the vnode ID based on the table name and creates the table on that vnode. If the database has multiple replicas, TDengine cluster creates a vgroup, not just a vnode. The number of vnodes in the cluster is not limited, only constrained by the computing and storage resources of the physical node itself.
The metadata of each table (including schema, tags, etc.) is also stored in the vnode, rather than centrally in the mnode. This design effectively shards the metadata, facilitating efficient parallel tag filtering operations, further enhancing query performance.
Data Partitioning
In addition to data sharding through vnodes, TDengine also adopts a strategy of partitioning time-series data by time intervals. Each data file contains time series data for a specific period, the length of which is determined by the database parameter duration. This method of partitioning by time intervals not only simplifies data management but also facilitates the efficient implementation of data retention policies. Once a data file exceeds the specified number of days (determined by the database parameter keep), the system automatically deletes these expired data files.
Furthermore, TDengine supports storing data from different time periods in different paths and storage media. This flexibility makes the management of big data temperature simple and straightforward, allowing users to implement multi-tier storage according to actual needs, thereby optimizing storage costs and access performance.
Overall, TDengine finely segments big data through the dimensions of vnode and time, achieving efficient parallel management and horizontal scaling. This design not only speeds up data processing and enhances efficiency but also provides users with a flexible, scalable data storage and query solution, meeting the needs of scenarios of various scales and requirements.
Load Balancing and Scaling
Each dnode regularly reports its current status to the mnode, including key metrics such as disk space usage, memory size, CPU utilization, network conditions, and the number of vnodes. This information is crucial for cluster health monitoring and resource scheduling.
Regarding the timing of load balancing, TDengine currently allows users to specify manually. When a new dnode is added to the cluster, users need to manually initiate the load balancing process to ensure the cluster operates in optimal condition.
Over time, the distribution of data in the cluster may change, causing some vnodes to become data hotspots. To address this, TDengine uses a replica adjustment and data splitting algorithm based on the Raft protocol, achieving dynamic scaling and redistribution of data. This process can be seamlessly conducted while the cluster is running, without affecting data writing and query services, thus ensuring system stability and availability.
Data Writing and Replication Process
In a database with N replicas, the corresponding vgroup will contain N vnodes with the same number. Among these vnodes, only one is designated as the leader, while the others act as followers. This architecture ensures data consistency and reliability.
When an application attempts to write new records to the cluster, only the leader vnode can accept write requests. If a follower vnode accidentally receives a write request, the cluster will immediately notify taosc to redirect to the leader vnode. This measure ensures that all write operations occur on the correct leader vnode, thus maintaining data consistency and integrity.
Through this design, TDengine ensures data reliability and consistency in a distributed environment, while providing efficient read and write performance.
Leader Vnode Writing Process
The Leader Vnode follows the writing process below:
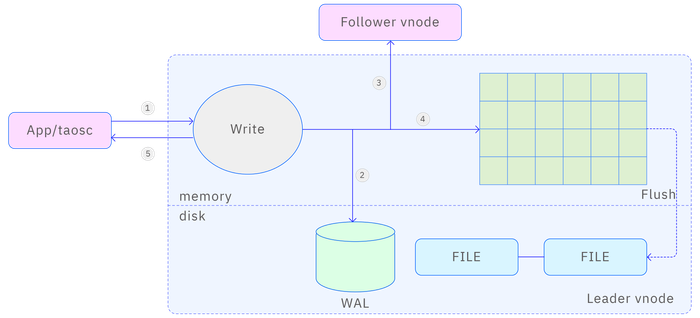
- Step 1: The leader vnode receives a write data request from the application, verifies OK, and proceeds to step 2 after verifying validity;
- Step 2: The vnode writes the original data packet of the request into the database log file WAL. If
wal_levelis set to 2 andwal_fsync_periodis set to 0, TDengine will also immediately persist the WAL data to disk to ensure that data can be recovered from the database log file in case of a crash, preventing data loss; - Step 3: If there are multiple replicas, the vnode will forward the data packet to the follower vnodes within the same virtual node group, including the data version number (version);
- Step 4: Write to memory and add the record to the skip list. However, if consensus is not reached, a rollback operation will be triggered;
- Step 5: The leader vnode returns a confirmation message to the application, indicating successful writing;
- Step 6: If any step among 2, 3, or 4 fails, an error will be directly returned to the application;
Follower Vnode Writing Process
For the follower vnode, the writing process is:
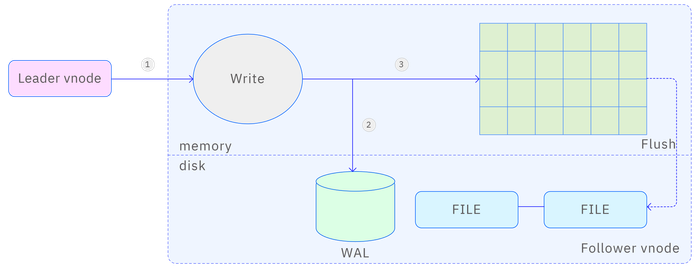
- Step 1: The follower vnode receives a data insertion request forwarded by the leader vnode.
- Step 2: The vnode writes the original data packet of the request into the database log file WAL. If
wal_levelis set to 2 andwal_fsync_periodis set to 0, TDengine will also immediately persist the WAL data to disk to ensure that data can be recovered from the database log file in case of a crash, preventing data loss. - Step 3: Write to memory, updating the skip list in memory.
Compared to the leader vnode, the follower vnode does not have a forwarding stage or a reply confirmation stage, reducing two steps. However, writing to memory and WAL is exactly the same.
Leader Selection
Each vnode maintains a version number for the data, which is also persisted when the vnode persists data in memory. Each data update, whether it's time-series data or metadata, increments the version number to ensure that every modification is accurately recorded.
When a vnode starts, its role (leader or follower) is uncertain, and the data is unsynchronized. To determine its role and synchronize data, the vnode needs to establish a TCP connection with other nodes in the same vgroup. After the connection is established, the vnodes exchange critical information such as version numbers and terms. Based on this information, the vnode will use the standard Raft consistency algorithm to complete the leader election process, thus determining who is the leader and who should act as a follower.
This mechanism ensures that vnodes can effectively coordinate and maintain data consistency and system stability in a distributed environment.
Synchronous Replication
In TDengine, when a leader vnode receives a data write request and forwards it to other replicas, it does not immediately notify the application that the write was successful. Instead, the leader vnode waits until more than half of the replicas (including itself) have agreed before confirming to the application that the write operation was successful. If the confirmation from more than half of the replicas is not obtained within the specified time, the leader vnode will return an error message to the application, indicating that the data write operation failed.
This synchronous replication mechanism ensures the consistency and security of data across multiple replicas but also presents challenges in terms of write performance. To balance data consistency and performance needs, TDengine introduces a pipeline replication algorithm during the synchronous replication process.
The pipeline replication algorithm allows the confirmation process for write requests from different database connections to proceed simultaneously, rather than sequentially waiting. Thus, even if the confirmation from one replica is delayed, it does not affect the write operations of other replicas. By this means, TDengine significantly enhances write performance while ensuring data consistency, meeting the needs for high throughput and low latency data processing.
Member Changes
In scenarios such as data scaling and node migration, it is necessary to adjust the number of replicas in a vgroup. In these cases, the amount of existing data directly affects the time required for data replication between replicas, and excessive data replication can severely block the data read and write process.
To address this issue, TDengine extends the Raft protocol by introducing a learner role. Learners play a crucial role in the replication process but do not participate in the voting process; they are only responsible for receiving data replication. Since learners do not participate in voting, the conditions for determining a successful write do not include learner confirmation.
When there is a significant difference in data between the learner and the leader, the learner will use a snapshot method for data synchronization. After the snapshot synchronization is complete, the learner will continue to catch up with the leader's logs until their data volumes are close. Once the learner's data volume is sufficiently close to that of the leader, the learner will transition to a follower role, beginning to participate in the voting process for data writes and elections.
Redirection
When taosc writes new records to the TDengine cluster, it first needs to locate the current leader vnode, as only the leader vnode handles write data requests. If taosc tries to send a write data request to a follower vnode, the cluster will immediately notify taosc to redirect to the correct leader vnode.
To ensure that write data requests are correctly routed to the leader vnode, taosc maintains a local cache of the node group topology. Upon receiving a notification from the cluster, taosc recalculates and determines the position of the leader vnode based on the latest node group topology information, then sends the write data request to it. At the same time, taosc also updates the leader distribution information in the local cache for future use.
This mechanism ensures that applications accessing TDengine through taosc do not need to worry about network retries. Regardless of how the nodes in the cluster change, taosc can automatically handle these changes, ensuring that write data requests are always correctly routed to the leader vnode.
Cache and Persistence
Time-Series Data Cache
TDengine adopts a unique time-driven cache management strategy, also known as write-driven cache management. This strategy differs from the traditional read-driven data cache mode, with its core priority being to store the most recently written data in the cluster's cache. When the cache capacity approaches the threshold, the system performs batch writing of the earliest data to the disk. Specifically, each vnode has its own independent memory space, divided into multiple fixed-size memory blocks, and the memory between different vnodes is completely isolated. During the data writing process, a log-like sequential append method is used, and each vnode also maintains its own SkipList structure for fast data retrieval. Once more than one-third of the memory blocks are filled, the system initiates the data flushing process and guides new write operations to new memory blocks. In this way, one-third of the memory blocks in the vnode are reserved for the latest data, achieving the purpose of caching while ensuring efficient querying. The memory size of the vnode can be configured through the database parameter buffer.
Additionally, considering the characteristics of IoT data, users are usually most concerned about the timeliness of data, i.e., the most recently generated data. TDengine makes good use of this feature by prioritizing the storage of the latest arriving (current state) data in the cache. Specifically, TDengine directly stores the newly arrived data into the cache to quickly respond to user queries and analysis needs for the latest data, thereby improving the overall database query response speed. From this perspective, by setting database parameters appropriately, TDengine can be used as a data cache, eliminating the need to deploy Redis or other additional caching systems. This approach not only effectively simplifies the system architecture but also helps reduce maintenance costs. It should be noted that once TDengine is restarted, the data in the cache will be cleared, and all previously cached data will be batch written to the disk, unlike professional Key-Value caching systems that automatically reload previously cached data back into the cache.
Persistent Storage
TDengine adopts a data-driven strategy to implement the persistent storage of cached data. When the cache data in a vnode accumulates to a certain amount, to avoid blocking subsequent data writing, TDengine will start a disk-writing thread to write these cached data to persistent storage devices. During this process, TDengine will create new database log files for data writing and delete old log files after successful disk writing to prevent unrestricted growth of log files.
To fully leverage the characteristics of time-series data, TDengine splits the data of a vnode into multiple files, each storing data for a fixed number of days set by the database parameter duration. This file-based storage method allows for rapid determination of which data files to open when querying specific time periods, greatly improving data reading efficiency.
For collected data, there is usually a certain retention period specified by the database parameter keep. Data files exceeding the set number of days will be automatically removed by the cluster and the corresponding storage space released.
After setting the duration and keep parameters, a vnode in typical working condition should have a total number of data files equal to the ceiling of (keep/duration)+1. The total number of data files should be kept within a reasonable range, typically between 10 and 100. Based on this principle, the duration parameter can be reasonably set. The keep parameter can be adjusted, but once duration is set, it cannot be changed.
In each data file, the data of a table is stored in blocks. A table may contain one to several data file blocks. Within a file block, data is stored in columns occupying continuous storage space, which helps significantly improve reading efficiency. The size of the file block is controlled by the database parameter maxRows (maximum number of records per block), with a default value of 4096. This value should be moderate; too large may lead to longer search times for locating specific time periods, affecting reading speed; too small may cause the data file block's index to be too large, reducing compression efficiency, also affecting reading speed.
Each data file block (ending with .data) is accompanied by an index file (ending with .head), which contains summary information of each data file block of each table, recording the offset of each data file block in the data file, the start and end times of the data, etc., to facilitate quick location of required data. Additionally, each data file block has an associated last file (ending with .last), which aims to prevent fragmentation during disk writing of data file blocks. If the number of records of a table written to disk does not meet the database parameter minRows (minimum number of records per block), these records will first be stored in the last file, and during the next disk writing, the newly written records will merge with the records in the last file before being written into the data file block.
Whether data is compressed during writing to disk depends on the setting of the database parameter comp. TDengine offers 3 compression options—no compression, first-level compression, and second-level compression, with corresponding comp values of 0, 1, and 2, respectively. First-level compression uses appropriate compression algorithms based on data type, such as delta-delta encoding, simple8B method, zig-zag encoding, LZ4, etc. Second-level compression further uses general compression algorithms on top of first-level compression to achieve higher compression rates.
Precomputation
To significantly improve the efficiency of query processing, TDengine stores statistical information of the data file block at the head of the data file block, including maximum, minimum, and total data values, known as precomputed units. When query processing involves these calculation results, these precomputed values can be directly utilized, eliminating the need to access the specific contents of the data file block. For scenarios where disk I/O becomes a bottleneck, using precomputed results can effectively reduce the pressure of reading disk I/O, thereby improving query speed.
In addition to precomputation, TDengine also supports various downsampling storage of raw data. One downsampling storage method is Rollup SMA, which automatically performs downsampling storage of raw data and supports 3 different data saving levels, allowing users to specify the aggregation period and duration for each level. This is particularly suitable for scenarios focused on data trends, with the core purpose of reducing storage overhead and improving query speed. Another downsampling storage method is Time-Range-Wise SMA, which performs downsampling storage based on aggregation results, very suitable for high-frequency interval query scenarios. This feature uses the same logic as ordinary stream computing and allows users to handle delayed data by setting a watermark, accordingly, the actual query results will also have some time delay.
Multi-Level Storage and Object Storage
By default, TDengine saves all data in /var/lib/taos directory, and the data files of each vnode are saved in a different directory under this directory. In order to expand the storage space, minimize the bottleneck of file reading and improve the data throughput rate, TDengine can configure the system parameter "dataDir" to allow multiple mounted hard disks to be used by system at the same time. In addition, TDengine also provides the function of tiered data storage, i.e. storage on different storage media according to the time stamps of data files. For example, the latest data is stored on SSD, the data older than a week is stored on local hard disk, and data older than four weeks is stored on network storage device. This reduces storage costs and ensures efficient data access. The movement of data on different storage media is automatically done by the system and is completely transparent to applications. Tiered storage of data is also configured through the system parameter "dataDir".
dataDir format is as follows:
dataDir data_path [tier_level] [primary] [disable_create_new_file]
Where data_path is the folder path of mount point, and tier_level is the media storage-tier. The higher the media storage-tier, means the older the data file. Multiple hard disks can be mounted at the same storage-tier, and data files on the same storage-tier are distributed on all hard disks within the tier. TDengine supports up to 3 tiers of storage, so tier_level values are 0, 1, and 2. When configuring dataDir, there must be only one mount path without specifying tier_level, which is called special mount disk (path). The mount path defaults to level 0 storage media and contains special file links, which cannot be removed, otherwise it will have a devastating impact on the written data. And primary means whether the data dir is the primary mount point. Enter 0 for false or 1 for true. The default value is 1. A TDengine cluster can have only one primary mount point, which must be on tier 0. And disable_create_new_file means whether to prohibit the creation of new file sets on the specified mount point. Enter 0 for false and 1 for true. The default value is 0. Tier 0 storage must have at least one mount point with disable_create_new_file set to 0. Tier 1 and tier 2 storage do not have this restriction.
Suppose there is a physical node with six mountable hard disks/mnt/disk1,/mnt/disk2, ..., /mnt/disk6, where disk1 and disk2 need to be designated as level 0 storage media, disk3 and disk4 are level 1 storage media, and disk5 and disk6 are level 2 storage media. Disk1 is a special mount disk, you can configure it in/etc/taos/taos.cfg as follows:
dataDir /mnt/disk1/taos 0 1 0
dataDir /mnt/disk2/taos 0 0 0
dataDir /mnt/disk3/taos 1 0 0
dataDir /mnt/disk4/taos 1 0 1
dataDir /mnt/disk5/taos 2 0 0
dataDir /mnt/disk6/taos 2 0 0
Mounted disks can also be a non-local network disk, as long as the system can access it.
You can use the following command to dynamically modify dataDir to control whether disable_create_new_file is enabled for the current directory.
alter dnode 1 "/mnt/disk2/taos 1";
Note: Tiered Storage is only supported in TSDB-Enterprise


