

Data Subscription Engine
Data subscription, as a core feature of TDengine, provides users with the ability to flexibly obtain the data they need. By deeply understanding its internal principles, users can more effectively utilize this feature to meet various real-time data processing and monitoring needs.
Basic Concepts
Topic
Similar to Kafka, using TDengine data subscription requires defining a topic. TDengine's topics can be databases, supertables, or a query statement. Database subscriptions and supertable subscriptions are mainly used for data migration, which can restore the entire database or supertable in another cluster. Query statement subscription is a highlight of TDengine data subscription, offering greater flexibility because data filtering and preprocessing are done by TDengine rather than the application, thus effectively reducing the amount of data transmitted and the complexity of the application.
As shown in the figure below, each topic involves data tables distributed across multiple vnodes (equivalent to Kafka's partition), with each vnode's data stored in WAL files, where data is written sequentially. Since the WAL files store not only data but also metadata, write messages, etc., the version numbers of the data are not consecutive.
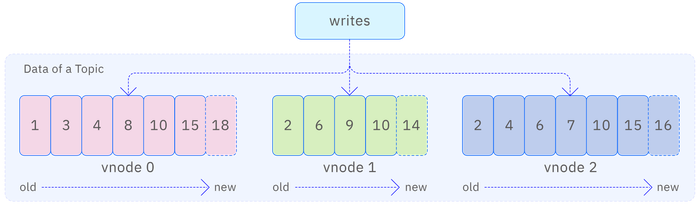
TDengine automatically creates indexes for WAL files to support fast random access. Through flexible and configurable file switching and retention mechanisms, users can specify the retention time and size of WAL files as needed. In this way, WAL is transformed into a persistent storage engine that retains the order of events.
For query statement subscriptions, during consumption, TDengine reads data directly from the WAL files based on the current consumption progress, performs filtering, transformation, and other operations using a unified query engine, and then pushes the data to the consumer.
Producer
The producer is the data writing application associated with the subscribed topic's data tables. Producers can generate data in various ways and write it into the WAL files of the vnode where the data tables are located. These methods include SQL, Stmt, Schemaless, CSV, stream computing, etc.
Consumer
The consumer is responsible for retrieving data from the topic. After subscribing to a topic, the consumer can consume all the data in the vnodes assigned to that consumer. To achieve efficient and orderly data retrieval, consumers use a combination of push and poll methods.
When there is a large amount of unconsumed data in a vnode, the consumer sends push requests to the vnode in sequence to pull a large amount of data at once. At the same time, the consumer records the consumption position of each vnode locally to ensure that all data is pushed in order.
When there is no data to be consumed in a vnode, the consumer will be in a waiting state. Once new data is written into the vnode, the system will immediately push the data to the consumer through the push method to ensure the timeliness of the data.
Consumer Group
When creating a consumer, it is necessary to specify a consumer group. Consumers within the same consumer group will share consumption progress, ensuring even data distribution among consumers. As mentioned earlier, the data of a topic is distributed across multiple vnodes. To increase consumption speed and achieve multi-threaded, distributed data consumption, multiple consumers can be added to the same consumer group. These consumers will first evenly divide the vnodes, and then consume the vnodes assigned to them. For example, if the data is distributed across 4 vnodes:
- With 2 consumers, each consumer will consume 2 vnodes;
- With 3 consumers, 2 consumers will each consume 1 vnode, while the remaining consumer will consume the remaining 2 vnodes;
- With 5 consumers, 4 consumers will each be assigned 1 vnode, while the remaining consumer will not participate in consumption.
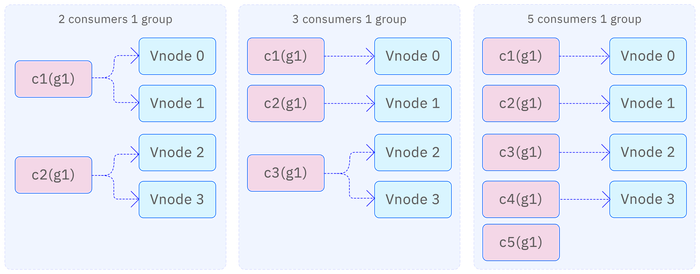
After adding a new consumer to a consumer group, the system will automatically redistribute the consumers through a rebalance mechanism. This process is transparent to users and does not require manual intervention. The rebalance mechanism ensures that data is redistributed among consumers to achieve load balancing.
Furthermore, a consumer can subscribe to multiple topics to meet different data processing needs in various scenarios. TDengine's data subscription feature can still guarantee at least once consumption in the face of complex environments such as crashes and restarts, ensuring data integrity and reliability.
Consumption Progress
The consumer group records consumption progress in the vnode to accurately restore the consumption position in case of consumer restarts or fault recovery. While consuming data, consumers can submit their consumption progress, i.e., the version number of the WAL on the vnode (corresponding to Kafka's offset). Consumption progress submission can be done manually or set to be automatically submitted periodically through parameter settings.
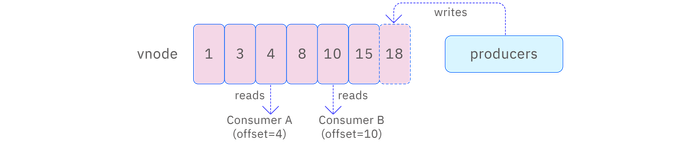
When a consumer consumes data for the first time, the consumption position can be determined through subscription parameters, i.e., whether to consume the newest or oldest data. For the same topic and any consumer group, each vnode's consumption progress is unique. Therefore, when a consumer in a vnode submits consumption progress and exits, other consumers in that consumer group will continue to consume this vnode, starting from the progress submitted by the previous consumer. If the previous consumer did not submit consumption progress, the new consumer will determine the starting consumption position based on the subscription parameter settings.
It is important to note that consumers in different consumer groups do not share consumption progress even if they consume the same topic. This design ensures the independence of each consumer group, allowing them to process data independently without interfering with each other. The following image clearly demonstrates this process.
Data Subscription Architecture
The data subscription system can logically be divided into two core modules: client and server. The client is responsible for creating consumers, acquiring a list of vnodes exclusive to these consumers, retrieving the required data from the server, and maintaining necessary state information. The server focuses on managing information related to topics and consumers, handling subscription requests from clients. It implements a rebalancing mechanism to dynamically allocate consumer nodes, ensuring continuity in the consumption process and consistency of data, while also tracking and managing consumption progress. The data subscription architecture is shown in the following diagram:
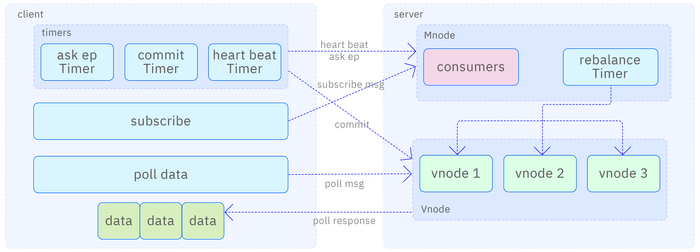
After the client successfully establishes a connection with the server, the user must first specify the consumer group and topic to create the corresponding consumer instances. Then, the client submits a subscription request to the server. At this moment, the consumer's status is marked as rebalancing, indicating that it is in the rebalance phase. The consumer will periodically send requests to the server to retrieve and obtain the list of vnodes to be consumed until the server assigns the corresponding vnodes. Once the assignment is complete, the consumer's status is updated to ready, signifying the successful completion of the subscription process. At this point, the client can officially start the process of sending data consumption requests to the vnode.
During the data consumption process, the consumer continuously sends requests to each assigned vnode to try to fetch new data. Once data is received, the consumer will continue to send requests to that vnode after consumption is complete, to maintain continuous consumption. If no data is received within a preset time, the consumer will register a consumption handle on the vnode. Thus, as soon as new data is generated on the vnode, it will be immediately pushed to the consumer, ensuring the immediacy of data consumption and effectively reducing the performance loss caused by frequent active data pulling by the consumer. Therefore, it is evident that the method of data retrieval by the consumer from the vnode is an efficient mode combining pull and push.
When consumers receive data, they also receive a version number of the data, which they record as the current consumption progress on each vnode. This progress is stored in memory within the consumer, ensuring it is only valid for that consumer. This design ensures that consumers can continue from where they left off in their last consumption session upon restart, avoiding duplicate data processing. However, if a consumer needs to exit and wishes to resume the last consumption progress later, they must commit the consumption progress to the server before exiting, performing what is called a commit operation. This operation allows the consumption progress to be persistently stored on the server, supporting both automatic and manual submission methods.
Additionally, to maintain the active status of consumers, the client also implements a heartbeat keep-alive mechanism. By regularly sending heartbeat signals to the server, consumers can prove they are still online. If the server does not receive a heartbeat from a consumer within a certain time, it will consider the consumer offline. For consumers that do not pull data for a certain time (which can be controlled by parameters), the server will also mark them as offline and remove them from the consumer group. The server relies on the heartbeat mechanism to monitor the status of all consumers, thereby effectively managing the entire consumer group.
The mnode mainly handles control messages during the subscription process, including creating and deleting topics, subscription messages, querying endpoint messages, and heartbeat messages, etc. The vnode focuses on handling consumption messages and commit messages. When the mnode receives a subscription message from a consumer, if the consumer has not subscribed before, its status will be set to rebalancing. If the consumer has already subscribed but the subscribed topic changes, the consumer's status will also be set to rebalancing. Then the mnode will perform a rebalance operation on consumers in the rebalancing state. Consumers whose heartbeat exceeds a fixed time or who actively close will be deleted.
Consumers regularly send query endpoint messages to the mnode to obtain the latest vnode allocation results after rebalancing. Additionally, consumers also regularly send heartbeat messages to notify the mnode of their active status. Furthermore, some information about the consumers is also reported to the mnode through heartbeat messages, allowing users to query this information on the mnode to monitor the status of various consumers. This design helps in the effective management and monitoring of consumers.
Rebalance Process
The data for each topic may be dispersed across multiple vnodes. By executing the rebalance process, the server reasonably allocates these vnodes to various consumers, ensuring even distribution of data and efficient consumption.
As shown in the diagram below, c1 represents consumer 1, c2 represents consumer 2, and g1 represents consumer group 1. Initially, only c1 in g1 consumes data, sending subscription information to the mnode, which then allocates all 4 vnodes containing the data to c1. When c2 is added to g1, c2 sends subscription information to the mnode, which detects that g1 needs to be reallocated and initiates the rebalance process, subsequently allocating two of the vnodes to c2 for consumption. The allocation information is also sent to the vnode by the mnode, and both c1 and c2 start consuming from their assigned vnodes.
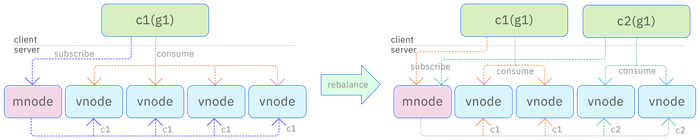
The rebalance timer checks every 2s to see if rebalancing is needed. During the rebalancing process, if the consumer's status is not ready, consumption cannot proceed. Only after the rebalancing ends normally and the consumer retrieves the offset of the assigned vnode can normal consumption occur; otherwise, the consumer will retry a specified number of times and then report an error.
Consumer State Handling
The state transition process for consumers is shown in the following diagram. Initially, a consumer who has just subscribed is in a rebalancing state, indicating that the consumer is not yet ready to consume data. Once an mnode detects a consumer in the rebalancing state, it will initiate the rebalance process. After a successful rebalance, the consumer's state will change to ready, indicating that the consumer is prepared. Subsequently, when the consumer periodically queries the endpoint message to get its ready status and the list of assigned vnodes, it can officially start consuming data.

If a consumer's heartbeat is lost for more than 12s, after the rebalance process, its status will be updated to clear, and then the consumer will be deleted by the system.
When a consumer actively exits, it will send an unsubscribe message. This message will clear all topics subscribed by the consumer and set the consumer's status to rebalancing. Subsequently, upon detecting a consumer in the rebalancing state, the rebalance process will be initiated. After a successful rebalance, the consumer's status will be updated to clear, and then the consumer will be deleted by the system. This series of measures ensures the orderly exit of consumers and the stability of the system.
Consuming Data
Time-series data is stored on vnodes, and the essence of consumption is reading data from the WAL files on vnodes. WAL files act like a message queue, and consumers record the version number of WAL data, which is essentially tracking the progress of consumption. The data in WAL files includes data data and meta data (such as table creation and modification operations). Subscriptions obtain relevant data based on the type and parameters of the topic. If the subscription involves queries with filtering conditions, the subscription logic will filter out data that does not meet the conditions through a general query engine.
As shown in the diagram below, vnodes can automatically commit consumption progress by setting parameters, or consumers can manually commit consumption progress after confirming data processing. If the consumption progress is stored in the vnode, then when different consumers in the same consumption group are switched, they will continue the previous progress. Otherwise, depending on the configuration parameters, consumers can choose to consume the oldest data or the newest data.
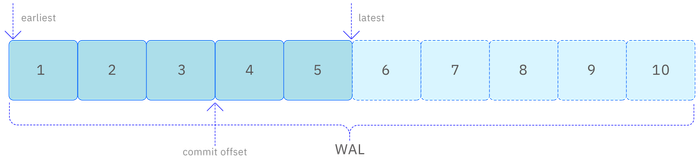
The earliest parameter means that the consumer starts consuming from the oldest data in the WAL file, while the latest parameter means starting from the newest data (i.e., newly written data) in the WAL file. These two parameters only take effect when the consumer consumes data for the first time or has not committed consumption progress. If consumption progress is committed during the consumption process, for example, committing once after consuming the third data in the WAL file (i.e., commit offset=3), then the next time on the same vnode, a new consumer in the same consumption group and topic will start consuming from the fourth data. This design ensures that consumers can flexibly choose the starting point for data consumption according to their needs while maintaining the persistence of consumption progress and synchronization among consumers.


