Storage Engine
The core competitiveness of TDengine lies in its outstanding write and query performance. Compared to traditional general-purpose databases, TDengine was focused from the beginning on deeply exploring the unique aspects of time-series data scenarios. It fully utilizes the time-ordered, continuous, and highly concurrent characteristics of time-series data, and has independently developed a set of writing and storage algorithms specifically tailored for time-series data.
This set of algorithms carefully preprocesses and compresses time-series data, not only significantly increasing the data writing speed but also substantially reducing the storage space required. This optimized design ensures that, even in scenarios where a large amount of real-time data continuously flows in, TDengine still maintains extremely high throughput and rapid response speeds.
Row and Column Format
The row and column format is one of the most important data structures used in TDengine to represent data. There are many open-source standardized row and column format libraries in the industry, such as Apache Arrow, etc. However, the scenarios TDengine faces are more focused, and the performance requirements are also higher. Therefore, designing and implementing its own row and column format library helps TDengine fully utilize the characteristics of the scenarios to achieve high performance and low space occupancy in row and column format data structures. The requirements for the row and column format include:
- Support for distinguishing unspecified values (NONE) and null values (NULL).
- Support for scenarios where NONE, NULL, and valued data coexist.
- Efficient handling of sparse and dense data.
Row Format
There are two encoding formats for row format in TDengine—Tuple encoding format and Key-Value encoding format. Which encoding format is used is determined by the characteristics of the data, aiming to process different data characteristics most efficiently.
-
Tuple Encoding Format
The Tuple encoding format is mainly used in non-sparse data scenarios, such as scenarios where all column data are non-None or have few None values. Tuple-encoded rows access column data directly based on the offset information provided by the table's schema, with a time complexity of O(1) and fast access speed. As shown in the following diagram:

-
Key-Value Encoding Format
The Key-Value encoding format is particularly suitable for sparse data scenarios, that is, scenarios where a large number of columns (such as thousands of columns) are defined in the table's schema, but very few columns actually have values. In this case, using the traditional Tuple encoding format would cause a great waste of space. In contrast, using the Key-Value encoding format can significantly reduce the storage space occupied by row data. As shown in the following diagram.
Key-Value encoded row data indexes the values of each column through an offset array. Although this method is slower in accessing column data directly, it significantly reduces the storage space occupied. In the actual encoding implementation, by introducing a flag option, the space occupancy is further optimized. Specifically, when all offset values are less than 256, the offset array of the Key-Value encoded row uses the uint8_t type; if all offset values are less than 65,536, then the uint16_t type is used; in other cases, the uint32_t type is used. This design further improves space utilization.

Column Format
In TDengine, fixed-length data in column format can be viewed as arrays, but due to the coexistence of NONE, NULL, and valued data, column format also needs a bitmap to indicate whether each index position is NONE, NULL, or has a value. For variable-length data types, the column format is different. In addition to the data array, the column format for variable-length data types also includes an offset array, used to index the starting position of variable-length data. The length of variable-length data can be obtained by the difference between two adjacent offset values. This design makes data storage and access more efficient, as shown in the following diagram:

vnode Storage
vnode Storage Architecture
A vnode is the basic unit of data storage, query, and backup in TDengine. Each vnode stores part of the table's metadata information and all the time-series data belonging to these tables. The distribution of tables on vnodes is determined by consistent hashing. Each vnode can be considered a standalone database. The storage of a vnode can be divided into the following 3 parts, as shown in the diagram below.
- Storage of WAL files.
- Storage of metadata.
- Storage of time-series data.
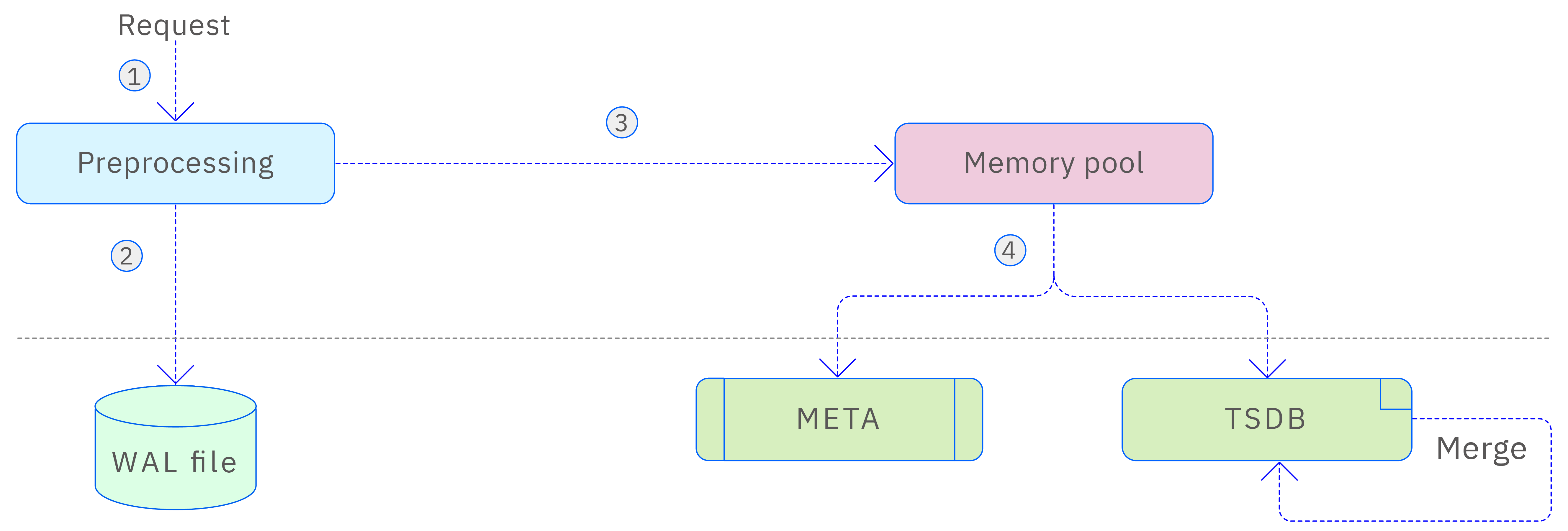
When a vnode receives a data write request, it first preprocesses the request to ensure the consistency of data across multiple replicas. The purpose of preprocessing is to ensure data security and consistency. After preprocessing, the data is written to the WAL file to ensure data persistence. Then, the data is written into the vnode's memory pool. When the space occupied by the memory pool reaches a certain threshold, a background thread flushes the written data to the disk (META and TSDB) for persistence. At the same time, the corresponding WAL number in memory is marked as written to disk. Additionally, TSDB uses an LSM (Log-Structured Merge-Tree) storage structure, which merges TSDB data files in the background when opening multiple tables with low-frequency parameters in the database, reducing the number of files and improving query performance. This design makes data storage and access more efficient.
Metadata Storage
The metadata stored in vnode mainly involves the metadata information of the table, including the name of the supertable, the schema definition of the supertable, the definition of the tag schema, the name of the subtable, the tag information of the subtable, and the index of the tags, etc. Since metadata query operations are far more frequent than write operations, TDengine uses B+Tree as the storage structure for metadata. B+Tree, with its efficient query performance and stable insert and delete operations, is very suitable for scenarios with more reads than writes, ensuring the efficiency and stability of metadata management. The metadata writing process is shown in the following figure:

When the META module receives a metadata write request, it generates multiple Key-Value pairs and stores these pairs in the underlying TDB storage engine. TDB is a B+Tree storage engine developed by TDengine according to its own needs, consisting of three main parts—built-in Cache, TDB storage main file, and TDB log file. When data is written to TDB, it is first written to the built-in Cache. If there is not enough memory in the Cache, the system will request additional memory allocation from the vnode's memory pool. If the write operation involves changes to existing data pages, the system will write the unchanged data pages to the TDB log file as a backup before modifying the data pages. This ensures data update atomicity and data integrity in case of power failure or other faults.
Since vnode stores various metadata information and metadata query needs are diverse, vnode internally creates multiple B+Trees to store different dimensional index information. These B+Trees are stored in a shared storage file and indexed by a root page number 1 index B+Tree, as shown in the following figure:
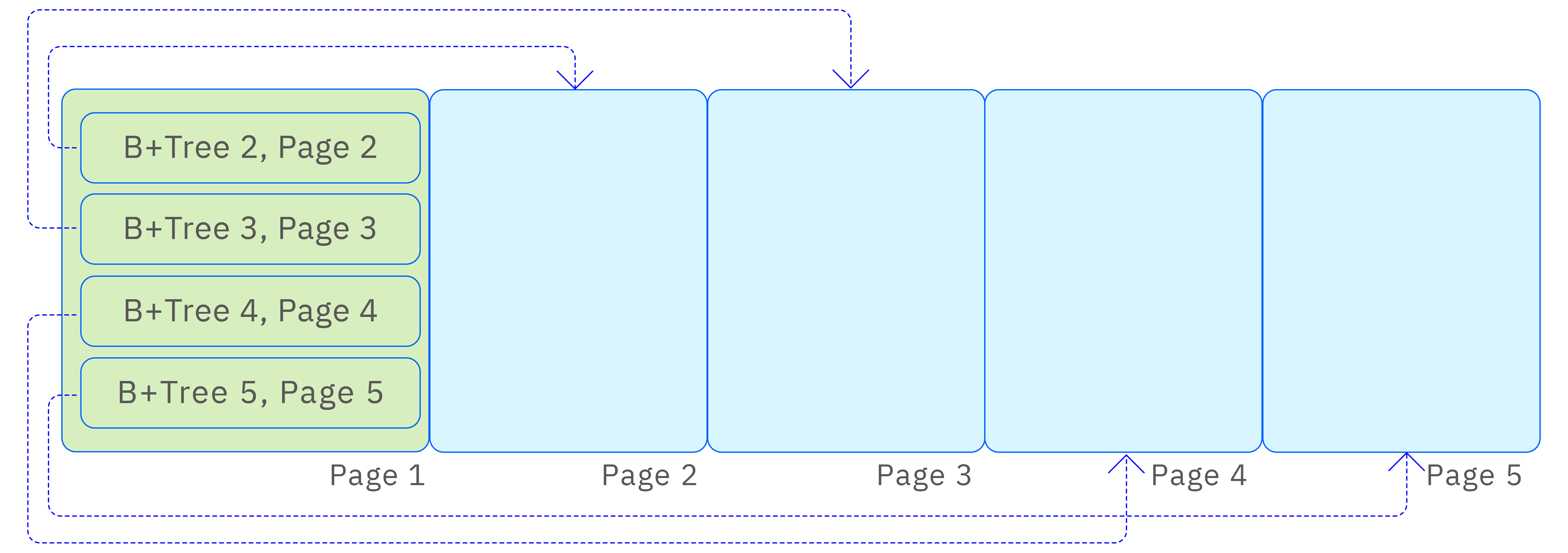
The page structure of the B+Tree is shown in the following figure:

In TDB, both Key and Value are variable-length. To handle cases where Key or Value exceeds the size of the file page, TDB uses an overflow page design to accommodate the excess data. Additionally, to effectively control the height of the B+Tree, TDB limits the maximum length of Key and Value in non-overflow pages, ensuring a fan-out of at least 4 for the B+Tree.
Time-Series Data Storage
Time-Series data in vnode is stored through the TSDB engine. Given the massive nature of time-series data and its continuous write traffic, using a traditional B+Tree structure for storage would rapidly increase the height of the tree as data volume grows, leading to a sharp decline in query and write performance, and eventually rendering the engine unusable. Therefore, TDengine has chosen the LSM storage structure to handle time series data. LSM optimizes data write performance through a log-structured storage method and reduces storage space usage and improves query efficiency through background merge operations, thus ensuring the storage and access performance of time series data. The TSDB engine's writing process is shown in the following figure:
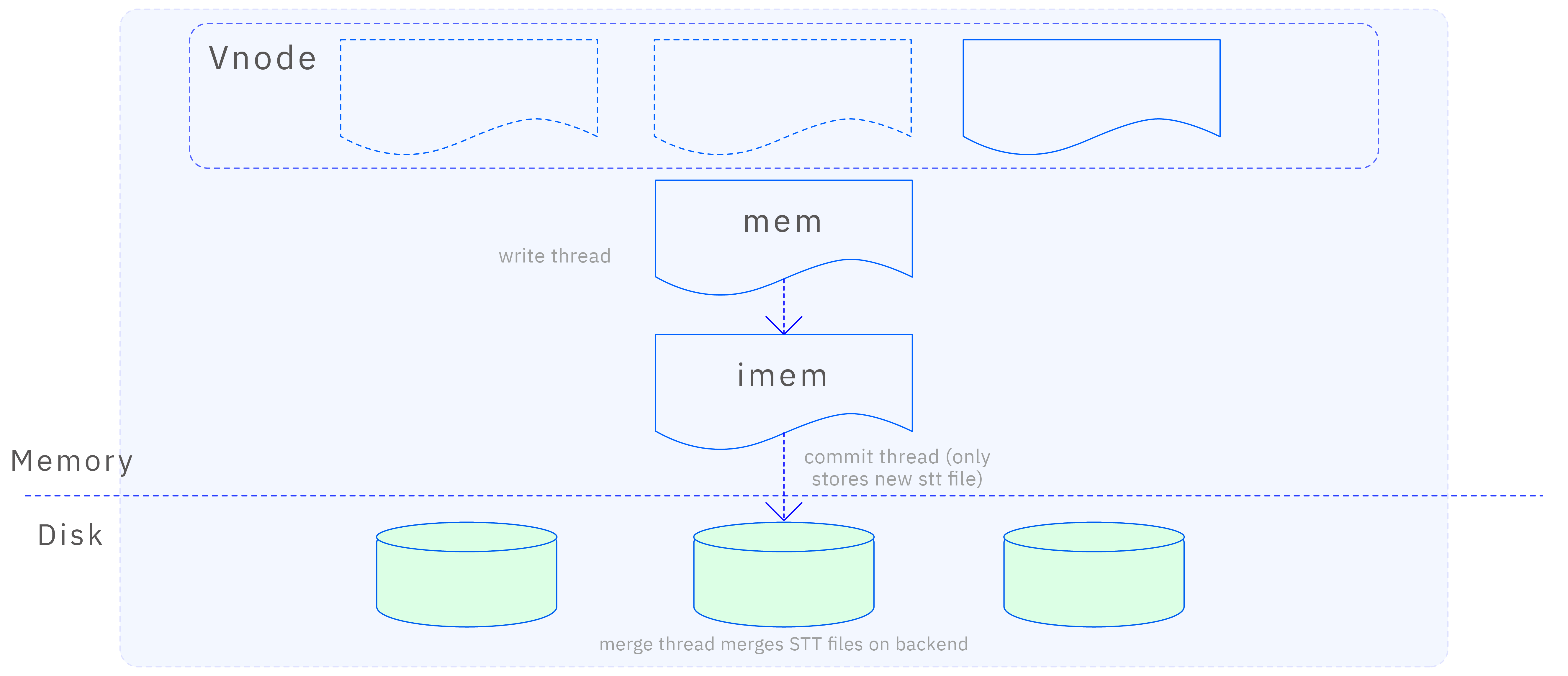
In the MemTable, data indexing adopts a combination of Red-Black Tree and SkipList. Data indexes of different tables are stored in the Red-Black Tree, while data indexes of the same table are stored in the SkipList. This design fully utilizes the characteristics of time-series data, enhancing data storage and access efficiency.
The Red-Black Tree is a self-balancing binary tree that maintains tree balance through node coloring and rotation operations, ensuring a time complexity of O(log n) for queries, insertions, and deletions. In the MemTable, the Red-Black Tree is used to store data indexes of different tables.
The SkipList is a data structure based on ordered linked lists, which achieves fast searches by adding multi-level indexes to the base of the linked list. The time complexity for queries, insertions, and deletions in the SkipList is O(log n), comparable to the Red-Black Tree. In the MemTable, the SkipList is used to store data indexes of the same table, allowing for quick location of data within a specific time range, providing efficient support for querying and writing time-series data.
By combining the Red-Black Tree and SkipList, TDengine implements an efficient data indexing method in the MemTable, enabling quick location of data from different tables and specific time ranges within the same table. The SkipList index is shown in the following figure:

In the TSDB engine, whether in memory or in data files, data is sorted by the (ts, version) tuple. To better manage and organize these time-ordered data, the TSDB engine divides data files into multiple data file groups based on time ranges. Each data file group covers a certain range of data, ensuring data continuity and completeness, and also facilitating data sharding and partitioning operations. By dividing data into multiple file groups based on time ranges, the TSDB engine can more effectively manage and access data stored on disk. The file groups are shown in the following figure:

When querying data, based on the time range of the data being queried, the file group number can be quickly calculated, thereby quickly locating the data file group to be queried. This design method can significantly improve query performance because it can reduce unnecessary file scanning and data loading, directly locating the file group containing the required data. Next, the files contained in the data file group are introduced separately:
head file
The head file is the BRIN (Block Range Index) file of the time-series data storage file (data file), which stores information such as the time range, offset, and length of each data block.
The query engine can efficiently filter the time range contained in the data blocks based on the information in the head file and obtain the location information of these data blocks.
The head file stores multiple BRIN record blocks and their indexes. BRIN record blocks use columnar compression, which can greatly reduce space occupancy while maintaining high query performance. The BRIN index structure is shown in the following figure:

data file
The data file is the file that actually stores the time-series data. In the data file, time-series data is stored in the form of data blocks, each data block contains columnar storage of a certain amount of data. Depending on the data type and compression configuration, different compression algorithms are used to compress the data blocks, reducing storage space occupancy and improving data transmission efficiency.
Unlike the stt file, each data block is stored independently in the data file, representing the data of a table within a specific time range. This design makes data management and querying more flexible and efficient. By storing data in blocks and combining columnar storage and compression technology, the TSDB engine can handle and access time-series data more effectively, meeting the needs of large data volumes and high-speed queries.
sma file
A precomputed file used to store the precomputed results of each column of data in the data blocks. These precomputed results include the sum, minimum (min), and maximum (max) of each column of data. By precomputing and storing this information, the query engine can directly utilize these precomputed results when executing certain queries, thereby avoiding the need to read the original data.
tomb file
A file used to store deletion records. The stored records are tuples of (suid, uid, start_timestamp, end_timestamp, version).
stt file
In scenarios with few tables and high frequency, the system only maintains one stt file. This file is specifically used to store the fragment data remaining after each data landing. In this way, during the next data landing, these fragment data can be merged with the new data in memory to form larger data blocks, which are then written into the data file together. This mechanism effectively avoids the fragmentation of data files, ensuring the continuity and efficiency of data storage.
For scenarios with multiple tables and low frequency, it is recommended to configure multiple stt files. The core idea in this scenario is that although the amount of data landed by a single table each time may not be large, the cumulative data volume of all subtables under the same supertable is quite considerable. By merging these data, larger data blocks can be generated, thereby reducing the fragmentation of data blocks. This not only improves the efficiency of data writing but also significantly enhances query performance, as continuous data storage is more conducive to rapid data retrieval and access.