Query Engine
TDengine, as a high-performance time-series big data platform, has its querying and computing capabilities as one of the core components. The platform offers a rich set of query processing features, including not only regular aggregation queries but also advanced functions such as time-series data window queries and statistical aggregations. These query and computation tasks require close cooperation between taosc, vnode, qnode, and mnode. In a complex supertable aggregation query scenario, multiple vnodes and qnodes may need to share the responsibilities of querying and computing. For definitions and introductions of vnode, qnode, mnode, please refer to System Architecture
Roles of Each Module in Query Computation
taosc
taosc is responsible for parsing and executing SQL. For insert-type SQL, taosc adopts a streaming read and parse strategy to improve processing efficiency. For other types of SQL, taosc first uses a syntax parser to break it down into an Abstract Syntax Tree (AST), performing preliminary syntax validation on the SQL during the parsing process. If syntax errors are found, taosc will directly return error information, along with the specific location of the error, to help users quickly locate and fix the issue.
The parsed AST is further transformed into a logical query plan, which after optimization, is converted into a physical query plan. Subsequently, taosc's scheduler converts the physical query plan into query execution tasks and sends these tasks to the selected vnode or qnode for execution. Once notified that the query results are ready, taosc retrieves the results from the respective vnode or qnode and finally returns them to the user.
The execution process of taosc can be briefly summarized as: parsing SQL into AST, generating and optimizing a logical query plan into a physical query plan, scheduling query tasks to vnode or qnode for execution, and retrieving the query results.
mnode
In the TDengine cluster, the information of supertables and the basic information of the meta-database are well managed. As the metadata server, mnode is responsible for responding to taosc's metadata query requests. When taosc needs to obtain metadata information such as vgroup, it sends a request to mnode. Upon receiving the request, mnode quickly returns the required information, ensuring that taosc can smoothly perform its operations.
Additionally, mnode is also responsible for receiving heartbeat messages sent by taosc. These heartbeat messages help maintain the connection status between taosc and mnode, ensuring unobstructed communication between the two.
vnode
In the TDengine cluster, vnode acts as a virtual node and plays a crucial role. It receives query requests distributed from physical nodes through a task queue and executes the corresponding query processing. Each vnode has its own independent task queue for managing and scheduling query requests.
When vnode receives a query request, it retrieves the request from the task queue and processes it. After processing, vnode returns the query results to the blocking query queue worker thread in the subordinate physical node, or directly back to taosc.
Executor
The executor module is responsible for implementing various query operators, which retrieve data content by calling the TSDB data reading API. The data content is returned to the executor module in the form of data blocks. TSDB is a time-series database responsible for reading the required information from memory or disk, including data blocks, data block metadata, data block statistics, and other types of information.
TSDB shields the implementation details and mechanisms of the underlying storage layer (disk and memory buffer), allowing the executor module to focus on querying and processing column-oriented data blocks. This design enables the executor module to efficiently handle various query requests while simplifying the complexity of data access and management.
UDF Daemon
In distributed database systems, the computing node executing UDF handles queries involving UDF. When a query uses UDF, the query module is responsible for scheduling the UDF Daemon to perform the UDF computation and retrieve the results.
UDF Daemon is an independent computing component responsible for executing user-defined functions. It can handle various types of data, including time-series data and tabular data. By distributing UDF computation tasks to the UDF Daemon, the query module can separate the computational load from the main query processing flow, enhancing the overall performance and scalability of the system.
During the execution of UDF, the query module works closely with the UDF Daemon to ensure the correct execution of computation tasks and the timely return of results.
Query Strategy
To better meet user needs, the TDengine cluster provides a query policy configuration item, queryPolicy, allowing users to choose the query execution framework according to their needs. This configuration item is located in the taosc configuration file, and each configuration item is only effective for a single taosc, allowing different strategies to be mixed in different taoscs within a cluster.
The values and meanings of queryPolicy are as follows.
- 1: Indicates that all queries only use vnode (default value).
- 2: Indicates mixed use of vnode/qnode (hybrid mode).
- 3: Indicates that in addition to the table scanning function using vnode, other query computation functions only use qnode.
- 4: Indicates the use of client aggregation mode.
By selecting appropriate query strategies, users can flexibly allocate and control query resources across different nodes, achieving purposes such as computation-storage separation and pursuing ultimate performance.
SQL Description
TDengine significantly reduces the learning curve for users by adopting SQL as the query language. Based on standard SQL, it extends several features to better support the unique query requirements of time-series databases.
- Grouping function extension: TDengine extends the standard SQL grouping function by introducing the
partition byclause. Users can split input data based on custom dimensions and perform any form of query operations within each group, such as constants, aggregates, scalars, expressions, etc. - Limit function extension: For grouped queries where there is a need to limit the number of outputs, TDengine introduces the
slimitandsoffsetclauses to restrict the number of groups. Whenlimitis used together with thepartition byclause, its meaning changes to a limit within the group rather than a global limit. - Tag query support: TDengine extends support for tag queries. Tags, as subtable attributes, can be used as pseudocolumns in queries. For scenarios that only query tag columns without concerning time-series data, TDengine introduces tag keywords to accelerate queries, avoiding scanning time-series data.
- Window query support: TDengine supports various window queries, including time windows, state windows, session windows, event windows, count windows, etc. In the future, it will also support more flexible user-defined window queries.
- Join query extension: In addition to traditional Inner, Outer, Semi, and Anti-Semi Joins, TDengine also supports time-series database-specific ASOF Joins and Window Joins. These extensions make it more convenient and flexible for users to perform the desired association queries.
Query Process
The complete query process is as follows.
- Step 1, taosc parses SQL and generates AST. The Catalog module requests metadata information for the specified tables in the query from vnode or mnode as needed. Then, it performs permission checks, syntax verification, and legality verification based on the metadata information.
- Step 2, after completing legality verification, a logical query plan is generated. All optimization strategies are applied sequentially, scanning and rewriting the execution plan. Based on the metadata information about the number of vgroups and qnodes, a corresponding physical query plan is generated from the logical query plan.
- Step 3, the client's query scheduler starts task scheduling. A query subtask is dispatched to a dnode belonging to a certain vnode or qnode based on its data affinity or load information.
- Step 4, the dnode, upon receiving the query task, identifies the targeted vnode or qnode and forwards the message to the query execution queue of the vnode or qnode.
- Step 5, the query execution thread of the vnode or qnode retrieves task information from the query queue, establishes a basic query execution environment, and immediately executes the query. After obtaining some available query results, it notifies the client scheduler.
- Step 6, the client scheduler completes the scheduling of all tasks according to the execution plan. Driven by the user API, it sends data retrieval requests to the query execution node where the topmost operator is located, reading the data request results.
- Step 7, operators retrieve and return data from downstream operators according to their parent-child relationships.
- Step 8, taosc returns all retrieved query results to the upper-level application.
Multi-table Aggregation Query Process
To address the need for efficient aggregation of data from different collection points in practical applications, TDengine introduces the concept of supertables. A supertable is a special table structure representing a category of data collection points with the same data schema. Essentially, a supertable is a collection of tables, each with the same field definitions but unique static tags. These tags can be multiple and can be added, deleted, or modified at any time.
Through supertables, applications can easily perform aggregation or statistical operations on all or part of the tables under a supertable by specifying tag filtering conditions. This design greatly simplifies the development process of applications, enhancing the efficiency and flexibility of data processing. The multi-table aggregation query process in TDengine is illustrated as follows:
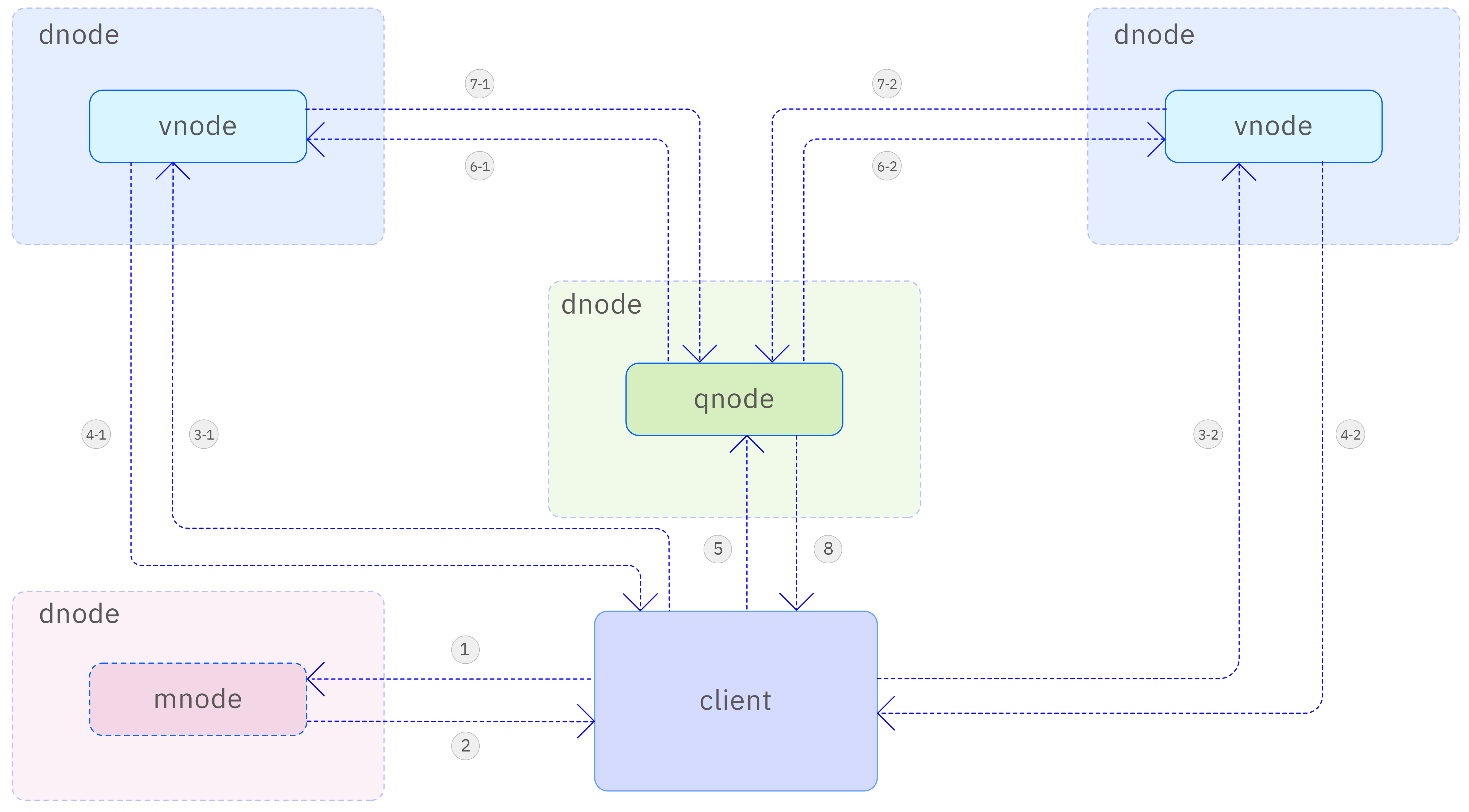
Specific steps are as follows. Step 1, taosc retrieves metadata information about databases and tables from mnode. Step 2, mnode returns the requested metadata information. Step 3, taosc sends query requests to each vnode belonging to the supertable. Step 4, vnode initiates a local query, returning the query response after obtaining the results. Step 5, taosc sends a query request to the aggregation node (in this case, qnode). Step 6, qnode sends data request messages to each vnode to pull data. Step 7, vnode returns the query results from this node. Step 8, qnode completes multi-node data aggregation and returns the final query results to the client.
To enhance aggregation computation speed, TDengine implements separate storage of tag data and time-series data within vnode. Initially, the system filters tag data in memory to determine the set of tables involved in the aggregation operation. This significantly reduces the dataset that needs to be scanned, thereby greatly improving the speed of aggregation computation.
Additionally, thanks to the data being distributed across multiple vnodes, aggregation operations can be performed concurrently across multiple vnodes. This distributed processing approach further speeds up aggregation, enabling TDengine to handle large-scale time-series data more efficiently.
It is worth noting that aggregation queries on regular tables and most operations are also applicable to supertables, and the syntax is completely identical. For details, please refer to the manual.
Query Cache
To enhance the efficiency of queries and computations, caching technology plays a crucial role. TDengine fully utilizes caching technology throughout the process of querying and computing to optimize system performance.
In TDengine, caching is widely used at various stages, including data storage, query optimization, execution plan generation, and data retrieval. By caching hot data and computation results, TDengine can significantly reduce the number of accesses to the underlying storage system, lower computational overhead, and thus improve the overall efficiency of querying and computing.
Moreover, TDengine's caching mechanism also features intelligence, capable of dynamically adjusting caching strategies based on data access patterns and system load conditions. This enables TDengine to maintain good performance in the face of complex and varying query demands.
Types of Cached Data
The types of data cached are as follows:
- Metadata (database, table meta, stable vgroup).
- Connection data (rpc session, http session).
- Time-series data (buffer pool, multilevel storage).
- Latest data (last, last_row).
Caching Scheme
TDengine adopts corresponding caching management strategies for different types of cache objects. For metadata, RPC objects, and query objects, TDengine uses a hash cache management method. This caching management method is managed through a list, each element of which is a cache structure containing cache information, hash table, garbage collection linked list, statistics, locks, and refresh frequency.
To ensure the effectiveness of the cache and system performance, TDengine also periodically checks for expired data in the cache list through a refresh thread and deletes expired data. This regular cleaning mechanism helps avoid storing too much useless data in the cache, reducing system resource consumption while maintaining the timeliness and accuracy of cached data. The caching scheme is shown in the following image:
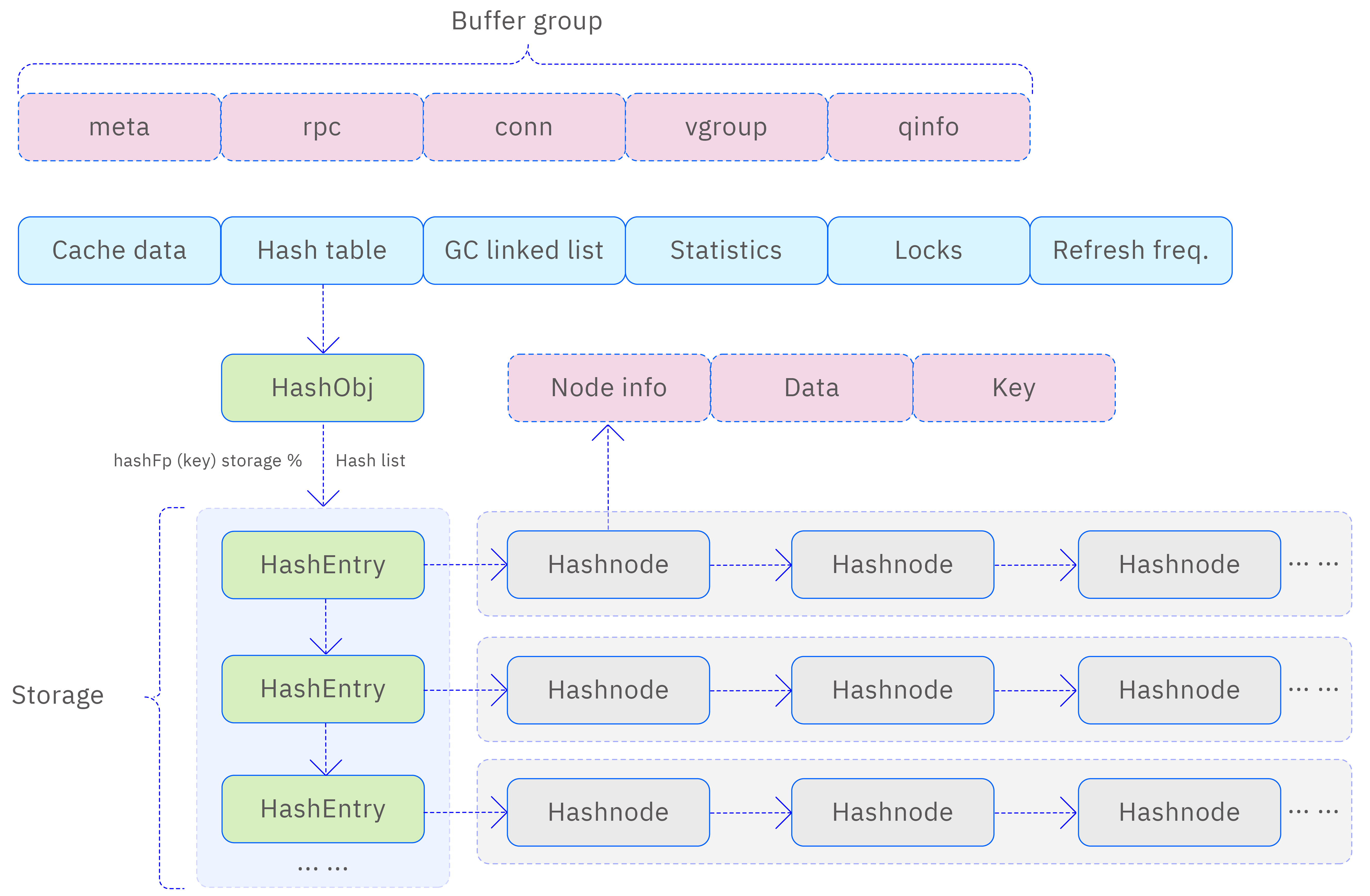
- Metadata cache (meta data): Includes information such as databases, supertables, users, nodes, views, virtual nodes, as well as the schema of tables and their mapping relationships with virtual nodes. Caching metadata in taosc can avoid frequent requests for metadata from mnode/vnode. taosc uses a fixed-size cache space for metadata, first-come, first-served, until the cache space is exhausted. When the cache space is exhausted, the cache undergoes partial eviction to cache metadata required for new incoming requests.
- Time-series data cache (time-series data): Time-series data is first cached in the memory of vnode in the form of SkipList. When conditions for disk writing are met, the time-series data is compressed, written into data storage files, and cleared from the cache.
- Latest data cache (last/last_row): Caching the latest data in time-series data can improve the query efficiency of the latest data. The latest data is organized into a KV form by subtable, where K is the subtable ID, and V is the last non-NULL and the latest row of data for each column in that subtable.