

Ingesting Data Efficiently
To help users easily build data ingestion pipelines with million-level throughput, the TDengine connector provides a high-performance write feature. When this feature is enabled, the TDengine connector automatically creates write threads and dedicated queues, caches data sharded by sub-tables, and sends data in batches when the data volume threshold is reached or a timeout condition occurs. This approach reduces network requests and increases throughput, allowing users to achieve high-performance writes without needing to master multithreaded programming knowledge or data sharding techniques.
Usage of Efficient Writing
The following introduces the usage methods of the efficient writing feature for each connector:
- Java
Introduction to the JDBC Efficient Writing Feature
Starting from version 3.6.0, the JDBC driver provides an efficient writing feature over WebSocket connections. The JDBC driver's efficient writing feature has the following characteristics:
- It supports the JDBC standard parameter binding interface.
- Under the condition of sufficient resources, the writing capacity is linearly related to the configuration of the number of writing threads.
- It supports the configuration of the writing timeout, the number of retries, and the retry interval after a connection is disconnected and re - established.
- It supports calling the
executeUpdateinterface to obtain the number of written data records. If there is an exception during writing, it can be caught at this time.
The following details its usage method. This section assumes that the user is already familiar with the JDBC standard parameter binding interface (refer to Parameter Binding for reference).
How to Enable the Efficient Writing Feature
For the JDBC connector, there are two ways to enable the efficient writing feature:
- Setting
PROPERTY_KEY_ASYNC_WRITEtostmtin the connection properties or addingasyncWrite = stmtto the JDBC URL can enable efficient writing on this connection. After enabling the efficient writing feature on the connection, all subsequentPreparedStatementobjects created will use the efficient writing mode. - When using parameter binding to create a
PreparedStatement, usingASYNC_INSERT INTOinstead ofINSERT INTOin the SQL statement can enable efficient writing for this parameter - bound object.
How to Check if the Writing is Successful
The client application uses the addBatch method of the JDBC standard interface to add a record and executeBatch to submit all added records. In the efficient writing mode, the executeUpdate method can be used to synchronously obtain the number of successfully written records. If there is a data writing failure, calling executeUpdate will catch an exception at this time.
Important Configuration Parameters for Efficient Writing
-
TSDBDriver.PROPERTY_KEY_BACKEND_WRITE_THREAD_NUM: The number of background writing threads in the efficient writing mode. It only takes effect when using a WebSocket connection. The default value is 10. -
TSDBDriver.PROPERTY_KEY_BATCH_SIZE_BY_ROW: The batch size of the written data in the efficient writing mode, with the unit of rows. It only takes effect when using a WebSocket connection. The default value is 1000. -
TSDBDriver.PROPERTY_KEY_CACHE_SIZE_BY_ROW: The size of the cache in the efficient writing mode, with the unit of rows. It only takes effect when using a WebSocket connection. The default value is 10000. -
TSDBDriver.PROPERTY_KEY_ENABLE_AUTO_RECONNECT: Whether to enable automatic reconnection. It only takes effect when using a WebSocket connection.truemeans enable,falsemeans disable. The default isfalse. It is recommended to enable it in the efficient writing mode. -
TSDBDriver.PROPERTY_KEY_RECONNECT_INTERVAL_MS: The retry interval for automatic reconnection, with the unit of milliseconds. The default value is 2000. It only takes effect whenPROPERTY_KEY_ENABLE_AUTO_RECONNECTistrue. -
TSDBDriver.PROPERTY_KEY_RECONNECT_RETRY_COUNT: The number of retry attempts for automatic reconnection. The default value is 3. It only takes effect whenPROPERTY_KEY_ENABLE_AUTO_RECONNECTistrue.
For other configuration parameters, please refer to Efficient Writing Configuration.
Instructions for Using JDBC Efficient Writing
The following is a simple example of using JDBC efficient writing, which illustrates the relevant configurations and interfaces for efficient writing.
Sample of Using JDBC Efficient Writing
public class WSHighVolumeDemo {
// modify host to your own
private static final String HOST = "127.0.0.1";
private static final int port = 6041;
private static final Random random = new Random(System.currentTimeMillis());
private static final int NUM_OF_SUB_TABLE = 10000;
private static final int NUM_OF_ROW = 10;
public static void main(String[] args) throws SQLException {
String url = "jdbc:TAOS-WS://" + HOST + ":" + port + "/?user=root&password=taosdata";
Properties properties = new Properties();
// Use an efficient writing mode
properties.setProperty(TSDBDriver.PROPERTY_KEY_ASYNC_WRITE, "stmt");
// The maximum number of rows to be batched in a single write request
properties.setProperty(TSDBDriver.PROPERTY_KEY_BATCH_SIZE_BY_ROW, "10000");
// The maximum number of rows to be cached in the queue (for each backend write
// thread)
properties.setProperty(TSDBDriver.PROPERTY_KEY_CACHE_SIZE_BY_ROW, "100000");
// Number of backend write threads
properties.setProperty(TSDBDriver.PROPERTY_KEY_BACKEND_WRITE_THREAD_NUM, "5");
// Enable this option to automatically reconnect when the connection is broken
properties.setProperty(TSDBDriver.PROPERTY_KEY_ENABLE_AUTO_RECONNECT, "true");
// The maximum time to wait for a write request to be processed by the server in
// milliseconds
properties.setProperty(TSDBDriver.PROPERTY_KEY_MESSAGE_WAIT_TIMEOUT, "5000");
// Enable this option to copy data when modifying binary data after the
// `addBatch` method is called
properties.setProperty(TSDBDriver.PROPERTY_KEY_COPY_DATA, "false");
// Enable this option to check the length of the sub-table name and the length
// of variable-length data types
properties.setProperty(TSDBDriver.PROPERTY_KEY_STRICT_CHECK, "false");
try (Connection conn = DriverManager.getConnection(url, properties)) {
init(conn);
// If you are certain that the child table exists, you can avoid binding the tag
// column to improve performance.
String sql = "INSERT INTO power.meters (tbname, groupid, location, ts, current, voltage, phase) VALUES (?,?,?,?,?,?,?)";
try (PreparedStatement pstmt = conn.prepareStatement(sql)) {
long current = System.currentTimeMillis();
int rows = 0;
for (int j = 0; j < NUM_OF_ROW; j++) {
// To simulate real-world scenarios, we adopt the approach of writing a batch of
// sub-tables, with one record per sub-table.
for (int i = 1; i <= NUM_OF_SUB_TABLE; i++) {
pstmt.setString(1, "d_" + i);
pstmt.setInt(2, i);
pstmt.setString(3, "location_" + i);
pstmt.setTimestamp(4, new Timestamp(current + j));
pstmt.setFloat(5, random.nextFloat() * 30);
pstmt.setInt(6, random.nextInt(300));
pstmt.setFloat(7, random.nextFloat());
// when the queue of backend cached data reaches the maximum size, this method
// will be blocked
pstmt.addBatch();
rows++;
}
pstmt.executeBatch();
if (rows % 50000 == 0) {
// The semantics of executeUpdate in efficient writing mode is to synchronously
// retrieve the number of rows written between the previous call and the current
// one.
int affectedRows = pstmt.executeUpdate();
Assert.equals(50000, affectedRows);
}
}
}
} catch (Exception ex) {
// please refer to the JDBC specifications for detailed exceptions info
System.out.printf("Failed to insert to table meters using efficient writing, %sErrMessage: %s%n",
ex instanceof SQLException ? "ErrCode: " + ((SQLException) ex).getErrorCode() + ", " : "",
ex.getMessage());
// Print stack trace for context in examples. Use logging in production.
ex.printStackTrace();
throw ex;
}
}
private static void init(Connection conn) throws SQLException {
try (Statement stmt = conn.createStatement()) {
stmt.execute("CREATE DATABASE IF NOT EXISTS power");
stmt.execute("USE power");
stmt.execute(
"CREATE STABLE IF NOT EXISTS power.meters (ts TIMESTAMP, current FLOAT, voltage INT, phase FLOAT) TAGS (groupId INT, location BINARY(24))");
}
}
}
Efficient Writing Example
Scenario Design
The following sample program demonstrates how to efficiently write data, with the scenario designed as follows:
- The TDengine client program continuously reads data from other data sources. In the sample program, simulated data generation is used to mimic data source reading, while also providing an example of pulling data from Kafka and writing it to TDengine.
- To improve the data reading speed of the TDengine client program, multi-threading is used for reading. To avoid out-of-order issues, the sets of tables read by multiple reading threads should be non-overlapping.
- To match the data reading speed of each data reading thread, a set of write threads is launched in the background. Each write thread has an exclusive fixed-size message queue.
Sample Code
This section provides sample code for the above scenario. The principle of efficient writing is the same for other scenarios, but the code needs to be modified accordingly.
This sample code assumes that the source data belongs to different subtables of the same supertable (meters). The program has already created this supertable in the test database before starting to write data. For subtables, they will be automatically created by the application according to the received data. If the actual scenario involves multiple supertables, only the code for automatic table creation in the write task needs to be modified.
- Java
Program Listing:
| Class Name | Functional Description |
|---|---|
| FastWriteExample | The main program responsible for command-line argument parsing, thread pool creation, and waiting for task completion. |
| WorkTask | Reads data from a simulated source and writes it using the JDBC standard interface. |
| MockDataSource | Simulates and generates data for a certain number of meters child tables. |
| DataBaseMonitor | Tracks write speed and prints the current write speed to the console every 10 seconds. |
| CreateSubTableTask | Creates child tables within a specified range for invocation by the main program. |
| Meters | Provides serialization and deserialization of single records in the meters table, used for sending messages to Kafka and receiving messages from Kafka. |
| ProducerTask | A producer that sends messages to Kafka. |
| ConsumerTask | A consumer that receives messages from Kafka, writes data to TDengine using the JDBC efficient writing interface, and commits offsets according to progress. |
| Util | Provides basic functionalities, including creating connections, creating Kafka topics, and counting write operations. |
Below are the complete codes and more detailed function descriptions for each class.
FastWriteExample
Introduction to Main Program Command-Line Arguments:
-b,--batchSizeByRow <arg> Specifies the `batchSizeByRow` parameter for Efficient Writing, default is 1000
-c,--cacheSizeByRow <arg> Specifies the `cacheSizeByRow` parameter for Efficient Writing, default is 10000
-d,--dbName <arg> Specifies the database name, default is `test`
--help Prints help information
-K,--useKafka Enables Kafka mode, creating a producer to send messages and a consumer to receive messages for writing to TDengine. Otherwise, uses worker threads to subscribe to simulated data for writing.
-r,--readThreadCount <arg> Specifies the number of worker threads, default is 5. In Kafka mode, this parameter also determines the number of producer and consumer threads.
-R,--rowsPerSubTable <arg> Specifies the number of rows to write per child table, default is 100
-s,--subTableNum <arg> Specifies the total number of child tables, default is 1000000
-w,--writeThreadPerReadThread <arg> Specifies the number of write threads per worker thread, default is 5
JDBC URL and Kafka Cluster Address Configuration:
-
The JDBC URL is configured via an environment variable, for example:
export TDENGINE_JDBC_URL="jdbc:TAOS-WS://localhost:6041?user=root&password=taosdata" -
The Kafka cluster address is configured via an environment variable, for example:
export KAFKA_BOOTSTRAP_SERVERS=localhost:9092
Usage:
1. Simulated data writing mode:
java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 1000
2. Kafka subscription writing mode:
java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 100 -K
Responsibilities of the Main Program:
- Parses command-line arguments.
- Creates child tables.
- Creates worker threads or Kafka producers and consumers.
- Tracks write speed.
- Waits for writing to complete and releases resources.
package com.taos.example.highvolume;
import org.apache.commons.cli.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.atomic.AtomicInteger;
public class FastWriteExample {
static final Logger logger = LoggerFactory.getLogger(FastWriteExample.class);
static ThreadPoolExecutor writerThreads;
static ThreadPoolExecutor producerThreads;
static final ThreadPoolExecutor statThread = (ThreadPoolExecutor) Executors.newFixedThreadPool(1);
private static final List<Stoppable> allTasks = new ArrayList<>();
private static int readThreadCount = 5;
private static int writeThreadPerReadThread = 5;
private static int batchSizeByRow = 1000;
private static int cacheSizeByRow = 10000;
private static int subTableNum = 1000000;
private static int rowsPerSubTable = 100;
private static String dbName = "test";
public static void forceStopAll() {
logger.info("shutting down");
for (Stoppable task : allTasks) {
task.stop();
}
if (producerThreads != null) {
producerThreads.shutdown();
}
if (writerThreads != null) {
writerThreads.shutdown();
}
statThread.shutdown();
}
private static void createSubTables(){
writerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, getNamedThreadFactory("FW-CreateSubTable-thread-"));
int range = (subTableNum + readThreadCount - 1) / readThreadCount;
for (int i = 0; i < readThreadCount; i++) {
int startIndex = i * range;
int endIndex;
if (i == readThreadCount - 1) {
endIndex = subTableNum - 1;
} else {
endIndex = startIndex + range - 1;
}
logger.debug("create sub table task {} {} {}", i, startIndex, endIndex);
CreateSubTableTask createSubTableTask = new CreateSubTableTask(i,
startIndex,
endIndex,
dbName);
writerThreads.submit(createSubTableTask);
}
logger.info("create sub table task started.");
while (writerThreads.getActiveCount() != 0) {
try {
Thread.sleep(1);
} catch (InterruptedException ignored) {
Thread.currentThread().interrupt();
}
}
logger.info("create sub table task finished.");
}
public static void startStatTask() throws SQLException {
StatTask statTask = new StatTask(dbName, subTableNum);
allTasks.add(statTask);
statThread.submit(statTask);
}
public static ThreadFactory getNamedThreadFactory(String namePrefix) {
return new ThreadFactory() {
private final AtomicInteger threadNumber = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, namePrefix + threadNumber.getAndIncrement());
}
};
}
private static void invokeKafkaDemo() throws SQLException {
producerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, getNamedThreadFactory("FW-kafka-producer-thread-"));
writerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, getNamedThreadFactory("FW-kafka-consumer-thread-"));
int range = (subTableNum + readThreadCount - 1) / readThreadCount;
for (int i = 0; i < readThreadCount; i++) {
int startIndex = i * range;
int endIndex;
if (i == readThreadCount - 1) {
endIndex = subTableNum - 1;
} else {
endIndex = startIndex + range - 1;
}
ProducerTask producerTask = new ProducerTask(i,
rowsPerSubTable,
startIndex,
endIndex);
allTasks.add(producerTask);
producerThreads.submit(producerTask);
ConsumerTask consumerTask = new ConsumerTask(i,
writeThreadPerReadThread,
batchSizeByRow,
cacheSizeByRow,
dbName);
allTasks.add(consumerTask);
writerThreads.submit(consumerTask);
}
startStatTask();
Runtime.getRuntime().addShutdownHook(new Thread(FastWriteExample::forceStopAll));
while (writerThreads.getActiveCount() != 0) {
try {
Thread.sleep(10);
} catch (InterruptedException ignored) {
Thread.currentThread().interrupt();
}
}
}
private static void invokeMockDataDemo() throws SQLException {
ThreadFactory namedThreadFactory = new ThreadFactory() {
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix = "FW-work-thread-";
@Override
public Thread newThread(Runnable r) {
return new Thread(r, namePrefix + threadNumber.getAndIncrement());
}
};
writerThreads = (ThreadPoolExecutor) Executors.newFixedThreadPool(readThreadCount, namedThreadFactory);
int range = (subTableNum + readThreadCount - 1) / readThreadCount;
for (int i = 0; i < readThreadCount; i++) {
int startIndex = i * range;
int endIndex;
if (i == readThreadCount - 1) {
endIndex = subTableNum - 1;
} else {
endIndex = startIndex + range - 1;
}
WorkTask task = new WorkTask(i,
writeThreadPerReadThread,
batchSizeByRow,
cacheSizeByRow,
rowsPerSubTable,
startIndex,
endIndex,
dbName);
allTasks.add(task);
writerThreads.submit(task);
}
startStatTask();
Runtime.getRuntime().addShutdownHook(new Thread(FastWriteExample::forceStopAll));
while (writerThreads.getActiveCount() != 0) {
try {
Thread.sleep(10);
} catch (InterruptedException ignored) {
Thread.currentThread().interrupt();
}
}
}
// print help
private static void printHelp(Options options) {
HelpFormatter formatter = new HelpFormatter();
formatter.printHelp("java -jar highVolume.jar", options);
System.out.println();
}
public static void main(String[] args) throws SQLException, InterruptedException {
Options options = new Options();
Option readThdcountOption = new Option("r", "readThreadCount", true, "Specify the readThreadCount, default is 5");
readThdcountOption.setRequired(false);
options.addOption(readThdcountOption);
Option writeThdcountOption = new Option("w", "writeThreadPerReadThread", true, "Specify the writeThreadPerReadThread, default is 5");
writeThdcountOption.setRequired(false);
options.addOption(writeThdcountOption);
Option batchSizeOption = new Option("b", "batchSizeByRow", true, "Specify the batchSizeByRow, default is 1000");
batchSizeOption.setRequired(false);
options.addOption(batchSizeOption);
Option cacheSizeOption = new Option("c", "cacheSizeByRow", true, "Specify the cacheSizeByRow, default is 10000");
cacheSizeOption.setRequired(false);
options.addOption(cacheSizeOption);
Option subTablesOption = new Option("s", "subTableNum", true, "Specify the subTableNum, default is 1000000");
subTablesOption.setRequired(false);
options.addOption(subTablesOption);
Option rowsPerTableOption = new Option("R", "rowsPerSubTable", true, "Specify the rowsPerSubTable, default is 100");
rowsPerTableOption.setRequired(false);
options.addOption(rowsPerTableOption);
Option dbNameOption = new Option("d", "dbName", true, "Specify the database name, default is test");
dbNameOption.setRequired(false);
options.addOption(dbNameOption);
Option kafkaOption = new Option("K", "useKafka", false, "use kafka demo to test");
kafkaOption.setRequired(false);
options.addOption(kafkaOption);
Option helpOption = new Option(null, "help", false, "print help information");
helpOption.setRequired(false);
options.addOption(helpOption);
CommandLineParser parser = new DefaultParser();
CommandLine cmd;
try {
cmd = parser.parse(options, args);
} catch (ParseException e) {
System.out.println(e.getMessage());
printHelp(options);
System.exit(1);
return;
}
if (cmd.hasOption("help")) {
printHelp(options);
return;
}
if (cmd.getOptionValue("readThreadCount") != null) {
readThreadCount = Integer.parseInt(cmd.getOptionValue("readThreadCount"));
if (readThreadCount <= 0){
logger.error("readThreadCount must be greater than 0");
return;
}
}
if (cmd.getOptionValue("writeThreadPerReadThread") != null) {
writeThreadPerReadThread = Integer.parseInt(cmd.getOptionValue("writeThreadPerReadThread"));
if (writeThreadPerReadThread <= 0){
logger.error("writeThreadPerReadThread must be greater than 0");
return;
}
}
if (cmd.getOptionValue("batchSizeByRow") != null) {
batchSizeByRow = Integer.parseInt(cmd.getOptionValue("batchSizeByRow"));
if (batchSizeByRow <= 0){
logger.error("batchSizeByRow must be greater than 0");
return;
}
}
if (cmd.getOptionValue("cacheSizeByRow") != null) {
cacheSizeByRow = Integer.parseInt(cmd.getOptionValue("cacheSizeByRow"));
if (cacheSizeByRow <= 0){
logger.error("cacheSizeByRow must be greater than 0");
return;
}
}
if (cmd.getOptionValue("subTableNum") != null) {
subTableNum = Integer.parseInt(cmd.getOptionValue("subTableNum"));
if (subTableNum <= 0){
logger.error("subTableNum must be greater than 0");
return;
}
}
if (cmd.getOptionValue("rowsPerSubTable") != null) {
rowsPerSubTable = Integer.parseInt(cmd.getOptionValue("rowsPerSubTable"));
if (rowsPerSubTable <= 0){
logger.error("rowsPerSubTable must be greater than 0");
return;
}
}
if (cmd.getOptionValue("dbName") != null) {
dbName = cmd.getOptionValue("dbName");
}
logger.info("readThreadCount={}, writeThreadPerReadThread={} batchSizeByRow={} cacheSizeByRow={}, subTableNum={}, rowsPerSubTable={}",
readThreadCount, writeThreadPerReadThread, batchSizeByRow, cacheSizeByRow, subTableNum, rowsPerSubTable);
logger.info("create database begin.");
Util.prepareDatabase(dbName);
logger.info("create database end.");
logger.info("create sub tables start.");
createSubTables();
logger.info("create sub tables end.");
if (cmd.hasOption("K")) {
Util.createKafkaTopic();
// use kafka demo
invokeKafkaDemo();
} else {
// use mock data source demo
invokeMockDataDemo();
}
}
}
WorkTask
The worker thread is responsible for reading data from the simulated data source. Each read task is associated with a simulated data source, which can generate data for a specific range of sub-tables. Different simulated data sources generate data for different tables.
The worker thread uses a blocking approach to invoke the JDBC standard interface addBatch. This means that if the corresponding efficient writing backend queue is full, the write operation will block.
package com.taos.example.highvolume;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.util.Iterator;
class WorkTask implements Runnable, Stoppable {
private static final Logger logger = LoggerFactory.getLogger(WorkTask.class);
private final int taskId;
private final int writeThreadCount;
private final int batchSizeByRow;
private final int cacheSizeByRow;
private final int rowsPerTable;
private final int subTableStartIndex;
private final int subTableEndIndex;
private final String dbName;
private volatile boolean active = true;
public WorkTask(int taskId,
int writeThradCount,
int batchSizeByRow,
int cacheSizeByRow,
int rowsPerTable,
int subTableStartIndex,
int subTableEndIndex,
String dbName) {
this.taskId = taskId;
this.writeThreadCount = writeThradCount;
this.batchSizeByRow = batchSizeByRow;
this.cacheSizeByRow = cacheSizeByRow;
this.rowsPerTable = rowsPerTable;
this.subTableStartIndex = subTableStartIndex; // for this task, the start index of sub table
this.subTableEndIndex = subTableEndIndex; // for this task, the end index of sub table
this.dbName = dbName;
}
@Override
public void run() {
logger.info("task {} started", taskId);
Iterator<Meters> it = new MockDataSource(subTableStartIndex, subTableEndIndex, rowsPerTable);
try (Connection connection = Util.getConnection(batchSizeByRow, cacheSizeByRow, writeThreadCount);
PreparedStatement pstmt = connection.prepareStatement("INSERT INTO " + dbName +".meters (tbname, ts, current, voltage, phase) VALUES (?,?,?,?,?)")) {
long i = 0L;
while (it.hasNext() && active) {
i++;
Meters meters = it.next();
pstmt.setString(1, meters.getTableName());
pstmt.setTimestamp(2, meters.getTs());
pstmt.setFloat(3, meters.getCurrent());
pstmt.setInt(4, meters.getVoltage());
pstmt.setFloat(5, meters.getPhase());
pstmt.addBatch();
if (i % batchSizeByRow == 0) {
pstmt.executeBatch();
}
if (i % (10L * batchSizeByRow) == 0){
pstmt.executeUpdate();
}
}
} catch (Exception e) {
logger.error("Work Task {} Error", taskId, e);
}
logger.info("task {} stopped", taskId);
}
public void stop() {
logger.info("task {} stopping", taskId);
this.active = false;
}
}
MockDataSource
A simulated data generator that produces data for a certain range of sub-tables. To mimic real-world scenarios, it generates data in a round-robin fashion, one row per subtable.
package com.taos.example.highvolume;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Iterator;
import java.util.Random;
import java.util.concurrent.ThreadLocalRandom;
/**
* Generate test data
*/
class MockDataSource implements Iterator<Meters> {
private final static Logger logger = LoggerFactory.getLogger(MockDataSource.class);
private final int tableStartIndex;
private final int tableEndIndex;
private final long maxRowsPerTable;
long currentMs = System.currentTimeMillis();
private int index = 0;
// mock values
public MockDataSource(int tableStartIndex, int tableEndIndex, int maxRowsPerTable) {
this.tableStartIndex = tableStartIndex;
this.tableEndIndex = tableEndIndex;
this.maxRowsPerTable = maxRowsPerTable;
}
@Override
public boolean hasNext() {
return index < (tableEndIndex - tableStartIndex + 1) * maxRowsPerTable;
}
@Override
public Meters next() {
// use interlace rows to simulate the data distribution in real world
if (index % (tableEndIndex - tableStartIndex + 1) == 0) {
currentMs += 1000;
}
long currentTbId = index % (tableEndIndex - tableStartIndex + 1) + tableStartIndex;
Meters meters = new Meters();
meters.setTableName(Util.getTableNamePrefix() + currentTbId);
meters.setTs(new java.sql.Timestamp(currentMs));
meters.setCurrent((float) (Math.random() * 100));
meters.setVoltage(ThreadLocalRandom.current().nextInt());
meters.setPhase((float) (Math.random() * 100));
index ++;
return meters;
}
}
CreateSubTableTask
Creates sub-tables within a specified range using a batch SQL creation approach.
package com.taos.example.highvolume;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
class CreateSubTableTask implements Runnable {
private static final Logger logger = LoggerFactory.getLogger(CreateSubTableTask.class);
private final int taskId;
private final int subTableStartIndex;
private final int subTableEndIndex;
private final String dbName;
public CreateSubTableTask(int taskId,
int subTableStartIndex,
int subTableEndIndex,
String dbName) {
this.taskId = taskId;
this.subTableStartIndex = subTableStartIndex;
this.subTableEndIndex = subTableEndIndex;
this.dbName = dbName;
}
@Override
public void run() {
try (Connection connection = Util.getConnection();
Statement statement = connection.createStatement()){
statement.execute("use " + dbName);
StringBuilder sql = new StringBuilder();
sql.append("create table");
int i = 0;
for (int tableNum = subTableStartIndex; tableNum <= subTableEndIndex; tableNum++) {
sql.append(" if not exists " + Util.getTableNamePrefix() + tableNum + " using meters" + " tags(" + tableNum + ", " + "\"location_" + tableNum + "\"" + ")");
if (i < 1000) {
i++;
} else {
statement.execute(sql.toString());
sql = new StringBuilder();
sql.append("create table");
i = 0;
}
}
if (sql.length() > "create table".length()) {
statement.execute(sql.toString());
}
} catch (SQLException e) {
logger.error("task id {}, failed to create sub table", taskId, e);
}
}
}
Meters
A data model class that provides serialization and deserialization methods for sending data to Kafka and receiving data from Kafka.
package com.taos.example.highvolume;
import java.sql.Timestamp;
public class Meters {
String tableName;
Timestamp ts;
float current;
int voltage;
float phase;
public String getTableName() {
return tableName;
}
public void setTableName(String tableName) {
this.tableName = tableName;
}
public Timestamp getTs() {
return ts;
}
public void setTs(Timestamp ts) {
this.ts = ts;
}
public float getCurrent() {
return current;
}
public void setCurrent(float current) {
this.current = current;
}
public int getVoltage() {
return voltage;
}
public void setVoltage(int voltage) {
this.voltage = voltage;
}
public float getPhase() {
return phase;
}
public void setPhase(float phase) {
this.phase = phase;
}
@Override
public String toString() {
return tableName + "," +
ts.toString() + "," +
current + "," +
voltage + "," +
phase;
}
public static Meters fromString(String str) {
String[] parts = str.split(",");
if (parts.length != 5) {
throw new IllegalArgumentException("Invalid input format");
}
Meters meters = new Meters();
meters.setTableName(parts[0]);
meters.setTs(Timestamp.valueOf(parts[1]));
meters.setCurrent(Float.parseFloat(parts[2]));
meters.setVoltage(Integer.parseInt(parts[3]));
meters.setPhase(Float.parseFloat(parts[4]));
return meters;
}
}
ProducerTask
A message producer that writes data generated by the simulated data generator to all partitions using a hash method different from JDBC efficient writing.
package com.taos.example.highvolume;
import com.taosdata.jdbc.utils.ReqId;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Iterator;
import java.util.Properties;
class ProducerTask implements Runnable, Stoppable {
private final static Logger logger = LoggerFactory.getLogger(ProducerTask.class);
private final int taskId;
private final int subTableStartIndex;
private final int subTableEndIndex;
private final int rowsPerTable;
private volatile boolean active = true;
public ProducerTask(int taskId,
int rowsPerTable,
int subTableStartIndex,
int subTableEndIndex) {
this.taskId = taskId;
this.subTableStartIndex = subTableStartIndex;
this.subTableEndIndex = subTableEndIndex;
this.rowsPerTable = rowsPerTable;
}
@Override
public void run() {
logger.info("kafak producer {}, started", taskId);
Iterator<Meters> it = new MockDataSource(subTableStartIndex, subTableEndIndex, rowsPerTable);
Properties props = new Properties();
props.put("bootstrap.servers", Util.getKafkaBootstrapServers());
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("batch.size", 1024 * 1024);
props.put("linger.ms", 500);
// create a Kafka producer
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
try {
while (it.hasNext() && active) {
Meters meters = it.next();
String key = meters.getTableName();
String value = meters.toString();
// to avoid the data of the sub-table out of order. we use the partition key to ensure the data of the same sub-table is sent to the same partition.
// Because efficient writing use String hashcode,here we use another hash algorithm to calculate the partition key.
long hashCode = Math.abs(ReqId.murmurHash32(key.getBytes(), 0));
ProducerRecord<String, String> metersRecord = new ProducerRecord<>(Util.getKafkaTopic(), (int)(hashCode % Util.getPartitionCount()), key, value);
producer.send(metersRecord);
}
} catch (Exception e) {
logger.error("task id {}, send message error: ", taskId, e);
}
finally {
producer.close();
}
logger.info("kafka producer {} stopped", taskId);
}
public void stop() {
logger.info("kafka producer {} stopping", taskId);
this.active = false;
}
}
ConsumerTask
A message consumer that receives messages from Kafka and writes them to TDengine.
package com.taos.example.highvolume;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.time.Duration;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
class ConsumerTask implements Runnable, Stoppable {
private static final Logger logger = LoggerFactory.getLogger(ConsumerTask.class);
private final int taskId;
private final int writeThreadCount;
private final int batchSizeByRow;
private final int cacheSizeByRow;
private final String dbName;
private volatile boolean active = true;
public ConsumerTask(int taskId,
int writeThreadCount,
int batchSizeByRow,
int cacheSizeByRow,
String dbName) {
this.taskId = taskId;
this.writeThreadCount = writeThreadCount;
this.batchSizeByRow = batchSizeByRow;
this.cacheSizeByRow = cacheSizeByRow;
this.dbName = dbName;
}
@Override
public void run() {
logger.info("Consumer Task {} started", taskId);
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Util.getKafkaBootstrapServers());
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, String.valueOf(batchSizeByRow));
props.put(ConsumerConfig.FETCH_MAX_WAIT_MS_CONFIG, "3000");
props.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG, String.valueOf(2 * 1024 * 1024));
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, "15000");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "60000");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
List<String> topics = Collections.singletonList(Util.getKafkaTopic());
try {
consumer.subscribe(topics);
} catch (Exception e) {
logger.error("Consumer Task {} Error", taskId, e);
return;
}
try (Connection connection = Util.getConnection(batchSizeByRow, cacheSizeByRow, writeThreadCount);
PreparedStatement pstmt = connection.prepareStatement("INSERT INTO " + dbName +".meters (tbname, ts, current, voltage, phase) VALUES (?,?,?,?,?)")) {
long i = 0L;
long lastTimePolled = System.currentTimeMillis();
while (active) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> metersRecord : records) {
i++;
Meters meters = Meters.fromString(metersRecord.value());
pstmt.setString(1, meters.getTableName());
pstmt.setTimestamp(2, meters.getTs());
pstmt.setFloat(3, meters.getCurrent());
pstmt.setInt(4, meters.getVoltage());
pstmt.setFloat(5, meters.getPhase());
pstmt.addBatch();
if (i % batchSizeByRow == 0) {
pstmt.executeBatch();
}
if (i % (10L * batchSizeByRow) == 0){
pstmt.executeUpdate();
consumer.commitSync();
}
}
if (!records.isEmpty()){
lastTimePolled = System.currentTimeMillis();
} else {
if (System.currentTimeMillis() - lastTimePolled > 1000 * 60) {
lastTimePolled = System.currentTimeMillis();
logger.error("Consumer Task {} has been idle for 10 seconds, stopping", taskId);
}
}
}
} catch (Exception e) {
logger.error("Consumer Task {} Error", taskId, e);
} finally {
consumer.close();
}
logger.info("Consumer Task {} stopped", taskId);
}
public void stop() {
logger.info("consumer task {} stopping", taskId);
this.active = false;
}
}
StatTask
Provides a periodic function to count the number of written records.
package com.taos.example.highvolume;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.sql.Connection;
import java.sql.SQLException;
import java.sql.Statement;
class StatTask implements Runnable, Stoppable {
private final static Logger logger = LoggerFactory.getLogger(StatTask.class);
private final int subTableNum;
private final String dbName;
private final Connection conn;
private final Statement stmt;
private volatile boolean active = true;
public StatTask(String dbName,
int subTableNum) throws SQLException {
this.dbName = dbName;
this.subTableNum = subTableNum;
this.conn = Util.getConnection();
this.stmt = conn.createStatement();
}
@Override
public void run() {
long lastCount = 0;
while (active) {
try {
Thread.sleep(10000);
long count = Util.count(stmt, dbName);
logger.info("numberOfTable={} count={} speed={}", subTableNum, count, (count - lastCount) / 10);
lastCount = count;
} catch (InterruptedException e) {
logger.error("interrupted", e);
break;
} catch (SQLException e) {
logger.error("execute sql error: ", e);
break;
}
}
try {
stmt.close();
conn.close();
} catch (SQLException e) {
logger.error("close connection error: ", e);
}
}
public void stop() {
active = false;
}
}
Util
A utility class that provides functions such as creating connections, creating databases, and creating topics.
package com.taos.example.highvolume;
import com.taosdata.jdbc.TSDBDriver;
import java.sql.*;
import java.util.Properties;
import org.apache.kafka.clients.admin.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.*;
import java.util.concurrent.ExecutionException;
public class Util {
private final static Logger logger = LoggerFactory.getLogger(Util.class);
public static String getTableNamePrefix() {
return "d_";
}
public static Connection getConnection() throws SQLException {
String jdbcURL = System.getenv("TDENGINE_JDBC_URL");
if (jdbcURL == null || jdbcURL == "") {
jdbcURL = "jdbc:TAOS-WS://localhost:6041/?user=root&password=taosdata";
}
return DriverManager.getConnection(jdbcURL);
}
public static Connection getConnection(int batchSize, int cacheSize, int writeThreadNum) throws SQLException {
String jdbcURL = System.getenv("TDENGINE_JDBC_URL");
if (jdbcURL == null || jdbcURL == "") {
jdbcURL = "jdbc:TAOS-WS://localhost:6041/?user=root&password=taosdata";
}
Properties properties = new Properties();
properties.setProperty(TSDBDriver.PROPERTY_KEY_ASYNC_WRITE, "stmt");
properties.setProperty(TSDBDriver.PROPERTY_KEY_BATCH_SIZE_BY_ROW, String.valueOf(batchSize));
properties.setProperty(TSDBDriver.PROPERTY_KEY_CACHE_SIZE_BY_ROW, String.valueOf(cacheSize));
properties.setProperty(TSDBDriver.PROPERTY_KEY_BACKEND_WRITE_THREAD_NUM, String.valueOf(writeThreadNum));
properties.setProperty(TSDBDriver.PROPERTY_KEY_ENABLE_AUTO_RECONNECT, "true");
return DriverManager.getConnection(jdbcURL, properties);
}
public static void prepareDatabase(String dbName) throws SQLException {
try (Connection conn = Util.getConnection();
Statement stmt = conn.createStatement()) {
stmt.execute("DROP DATABASE IF EXISTS " + dbName);
stmt.execute("CREATE DATABASE IF NOT EXISTS " + dbName + " vgroups 20");
stmt.execute("use " + dbName);
stmt.execute("CREATE STABLE " + dbName
+ ".meters (ts TIMESTAMP, current FLOAT, voltage INT, phase FLOAT) TAGS (groupId INT, location BINARY(64))");
}
}
public static long count(Statement stmt, String dbName) throws SQLException {
try (ResultSet result = stmt.executeQuery("SELECT count(*) from " + dbName + ".meters")) {
result.next();
return result.getLong(1);
}
}
public static String getKafkaBootstrapServers() {
String kafkaBootstrapServers = System.getenv("KAFKA_BOOTSTRAP_SERVERS");
if (kafkaBootstrapServers == null || kafkaBootstrapServers == "") {
kafkaBootstrapServers = "localhost:9092";
}
return kafkaBootstrapServers;
}
public static String getKafkaTopic() {
return "test-meters-topic";
}
public static void createKafkaTopic() {
Properties config = new Properties();
config.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, getKafkaBootstrapServers());
try (AdminClient adminClient = AdminClient.create(config)) {
String topicName = getKafkaTopic();
int numPartitions = getPartitionCount();
short replicationFactor = 1;
ListTopicsResult topics = adminClient.listTopics();
Set<String> existingTopics = topics.names().get();
if (!existingTopics.contains(topicName)) {
NewTopic newTopic = new NewTopic(topicName, numPartitions, replicationFactor);
CreateTopicsResult createTopicsResult = adminClient.createTopics(Collections.singleton(newTopic));
createTopicsResult.all().get();
logger.info("Topic " + topicName + " created successfully.");
}
} catch (InterruptedException | ExecutionException e) {
logger.error("Failed to delete/create topic: " + e.getMessage());
throw new RuntimeException(e);
}
}
public static int getPartitionCount() {
return 5;
}
}
Execution Steps:
Execute the Java Example Program
Execute the example program in a local integrated development environment:
-
Clone the TDengine repository
git clone git@github.com:taosdata/TDengine.git --depth 1 -
Open the
TDengine/docs/examples/JDBC/highvolumedirectory with the integrated development environment. -
Configure the environment variable
TDENGINE_JDBC_URLin the development environment. If the global environment variableTDENGINE_JDBC_URLhas already been configured, you can skip this step. -
If you want to run the Kafka example, you need to set the environment variable
KAFKA_BOOTSTRAP_SERVERSfor the Kafka cluster address. -
Specify command-line arguments, such as
-r 3 -w 3 -b 100 -c 1000 -s 1000 -R 100. -
Run the class
com.taos.example.highvolume.FastWriteExample.
Execute the example program on a remote server:
To execute the example program on a server, follow these steps:
-
Package the sample code. Navigate to the directory
TDengine/docs/examples/JDBC/highvolumeand run the following command to generatehighVolume.jar:mvn package -
Copy the program to the specified directory on the server:
scp -r .\target\highVolume.jar <user>@<host>:~/dest-path -
Configure the environment variable. Edit
~/.bash_profileor~/.bashrcand add the following content for example:export TDENGINE_JDBC_URL="jdbc:TAOS-WS://localhost:6041?user=root&password=taosdata"The above uses the default JDBC URL for a locally deployed TDengine Server. Modify it according to your actual environment. If you want to use Kafka subscription mode, additionally configure the Kafka cluster environment variable:
export KAFKA_BOOTSTRAP_SERVERS=localhost:9092 -
Start the sample program with the Java command. Use the following template (append
-Kfor Kafka subscription mode):java -jar highVolume.jar -r 5 -w 5 -b 10000 -c 100000 -s 1000000 -R 1000 -
Terminate the test program. The program does not exit automatically. Once a stable write speed is achieved under the current configuration, press CTRL + C to terminate it. Below is a sample log output from an actual run on a machine with a 40-core CPU, 256GB RAM, and SSD storage.
---------------$ java -jar highVolume.jar -r 2 -w 10 -b 10000 -c 100000 -s 1000000 -R 100
[INFO ] 2025-03-24 18:03:17.980 com.taos.example.highvolume.FastWriteExample main 309 main readThreadCount=2, writeThreadPerReadThread=10 batchSizeByRow=10000 cacheSizeByRow=100000, subTableNum=1000000, rowsPerSubTable=100
[INFO ] 2025-03-24 18:03:17.983 com.taos.example.highvolume.FastWriteExample main 312 main create database begin.
[INFO ] 2025-03-24 18:03:34.499 com.taos.example.highvolume.FastWriteExample main 315 main create database end.
[INFO ] 2025-03-24 18:03:34.500 com.taos.example.highvolume.FastWriteExample main 317 main create sub tables start.
[INFO ] 2025-03-24 18:03:34.502 com.taos.example.highvolume.FastWriteExample createSubTables 73 main create sub table task started.
[INFO ] 2025-03-24 18:03:55.777 com.taos.example.highvolume.FastWriteExample createSubTables 82 main create sub table task finished.
[INFO ] 2025-03-24 18:03:55.778 com.taos.example.highvolume.FastWriteExample main 319 main create sub tables end.
[INFO ] 2025-03-24 18:03:55.781 com.taos.example.highvolume.WorkTask run 41 FW-work-thread-2 started
[INFO ] 2025-03-24 18:03:55.781 com.taos.example.highvolume.WorkTask run 41 FW-work-thread-1 started
[INFO ] 2025-03-24 18:04:06.580 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=12235906 speed=1223590
[INFO ] 2025-03-24 18:04:17.531 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=31185614 speed=1894970
[INFO ] 2025-03-24 18:04:28.490 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=51464904 speed=2027929
[INFO ] 2025-03-24 18:04:40.851 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=71498113 speed=2003320
[INFO ] 2025-03-24 18:04:51.948 com.taos.example.highvolume.StatTask run 36 pool-1-thread-1 numberOfTable=1000000 count=91242103 speed=1974399
Key Factors for Write Performance
From the Client Application Perspective
From the client application's perspective, the following factors should be considered for efficient data writing:
- Batch Writing: Generally, larger batch sizes improve efficiency (but the advantage diminishes beyond a certain threshold). When using SQL to write to TDengine, include as much data as possible in a single SQL statement. The maximum allowed SQL length in TDengine is 1MB (1,048,576 characters).
- Multithreaded Writing: Before system resource bottlenecks are reached, increasing the number of write threads can improve throughput (performance may decline due to server-side processing limitations beyond the threshold). It is recommended to assign independent connections to each write thread to reduce connection resource contention.
- Write Locality: The distribution of data across different tables (or sub-tables), i.e., the locality of data to be written. Writing to a single table (or sub-table) in each batch is more efficient than writing to multiple tables (or sub-tables).
- Pre-Creating Tables: Pre-creating tables improves write performance as it eliminates the need to check table existence and allows omitting tag column data during writing.
- Write Methods:
- Parameter binding writes are more efficient than raw SQL writes, as they avoid SQL parsing.
- SQL writes without automatic table creation are more efficient than those with automatic table creation, as the latter requires frequent table existence checks.
- SQL writes are more efficient than schema-less writes, as schema-less writes enable automatic table creation and dynamic schema changes.
- Order Preservation: Data for the same sub-table must be submitted in ascending order of timestamps. Out-of-order data causes additional sorting operations on the server, impacting write performance.
- Enabling Compression: When network bandwidth is a bottleneck or there is significant data duplication, enabling compression can effectively improve overall performance.
Client applications should fully and appropriately utilize these factors. For example, choosing parameter binding, pre-creating sub-tables, writing to a single table (or sub-table) in each batch, and configuring batch size and concurrent thread count through testing to achieve the optimal write speed for the current system.
From the Data Source Perspective
Client applications usually need to read data from a data source before writing it to TDengine. From the data source's perspective, the following situations require adding a queue between the reading and writing threads:
- There are multiple data sources, and the data generation speed of a single data source is much lower than the writing speed of a single thread, but the overall data volume is relatively large. In this case, the role of the queue is to aggregate data from multiple sources to increase the amount of data written at once.
- The data generation speed of a single data source is much greater than the writing speed of a single thread. In this case, the role of the queue is to increase the concurrency of writing.
- Data for a single table is scattered across multiple data sources. In this case, the role of the queue is to aggregate the data for the same table in advance, improving the adjacency of the data during writing.
If the data source for the writing application is Kafka, and the writing application itself is a Kafka consumer, then Kafka's features can be utilized for efficient writing. For example:
- Write data from the same table to the same Topic and the same Partition to increase data adjacency.
- Aggregate data by subscribing to multiple Topics.
- Increase the concurrency of writing by increasing the number of Consumer threads.
- Increase the maximum amount of data fetched each time to increase the maximum amount of data written at once.
From the Server Configuration Perspective
First, consider several important performance-related parameters in the database creation options:
- vgroups: When creating a database on the server, reasonably set the number of vgroups based on the number of disks, disk I/O capability, and processor capacity to fully unleash system performance. Too few vgroups will underutilize performance, while too many will cause unnecessary resource contention. It is recommended to keep the number of tables per vgroup within 1 million, and within 10,000 under sufficient hardware resources for better results.
- buffer: Refers to the write memory size allocated for a vnode, with a default of 256 MB. When the actual written data in a vnode reaches about 1/3 of the buffer size, a data flush to disk is triggered. Increasing this parameter appropriately can cache more data for batch flushing, improving write efficiency. However, an excessively large value will prolong recovery time in case of a system crash.
- cachemodel: Controls whether to cache the latest data of sub-tables in memory. Enabling this feature affects write performance as it updates each table's
last_rowand each column'slastvalue during writing. Reducing the impact by changing the option frombothtolast_roworlast_value. - stt_trigger: Controls the TSDB data flush policy and the number of files triggering background file merging. The default for the enterprise edition is 2, while the open-source edition can only be configured to 1.
stt_trigger = 1is suitable for scenarios with few tables and high write frequency;stt_trigger > 1is better for scenarios with many tables and low write frequency.
For other parameters, refer to Database Management.
Next, consider performance-related parameters in the taosd configuration:
- compressMsgSize: Enabling RPC message compression improves performance when bandwidth is a bottleneck.
- numOfCommitThreads: Number of background flush threads on the server, default 4. More threads do not always mean better performance, as they can cause disk write contention. Servers with multiple disks can consider increasing this parameter to utilize concurrent I/O capabilities.
- Log Level: Parameters like
debugFlagcontrol log output levels. Higher log levels increase output pressure and impact write performance, so the default configuration is recommended.
For other parameters, refer to Server Configuration.
Implementation Principle of Efficient Writing
From the factors affecting write performance discussed above, developing high-performance data writing programs requires knowledge of multithreaded programming and data sharding, posing a technical threshold. To reduce user development costs, the TDengine connector provides the efficient writing feature, allowing users to leverage TDengine's powerful writing capabilities without dealing with underlying thread management and data sharding logic.
Below is a schematic diagram of the connector's efficient writing feature implementation:
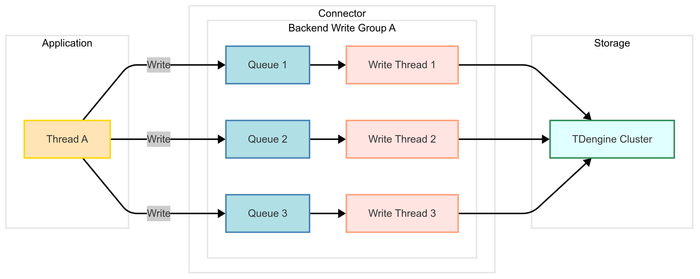
Design Principles
-
Automatic Thread and Queue Creation:
The connector dynamically creates independent write threads and corresponding write queues based on configuration parameters. Each queue is bound to a sub-table, forming a processing chain of "sub-table data - dedicated queue - independent thread". -
Data Sharding and Batch Triggering:
When the application writes data, the connector automatically shards the data by sub-table and caches it in the corresponding queue. Batch sending is triggered when either of the following conditions is met:- The queue data volume reaches the preset threshold.
- The preset waiting timeout is reached (to avoid excessive latency).
This mechanism significantly improves write throughput by reducing the number of network requests.
Functional Advantages
- Single-Thread High-Performance Writing:
The application layer only needs to call the write interface via a single thread. The connector's underlying layer automatically handles multithreaded concurrency, achieving performance close to traditional client multithreaded writing while hiding all underlying thread management complexity. - Reliability Enhancement Mechanisms:
- Synchronous Validation Interface: Provides synchronous methods to ensure traceability of write success status for submitted data.
- Connection Self-Healing: Supports automatic reconnection after disconnection, combined with configurable timeout retry policies (retry count and interval) to ensure no data loss.
- Error Isolation: Exceptions in a single queue or thread do not affect data writing for other sub-tables, improving system fault tolerance.
The connector's efficient writing feature only supports writing to supertables, not ordinary tables.


