Edge–Cloud Orchestration
Why Edge-Cloud Collaboration is Needed
In industrial Internet scenarios, edge devices are used only to handle local data, and decision-makers cannot form a global understanding of the entire system based solely on information collected by edge devices. In practical applications, edge devices need to report data to cloud computing platforms (public or private clouds), where data aggregation and information integration are carried out, providing decision-makers with a global insight into the entire dataset. This edge-cloud collaboration architecture has gradually become an important pillar supporting the development of the industrial Internet.
Edge devices mainly monitor and alert on specific data on the production line, such as real-time production data in a particular workshop, and then synchronize this edge-side production data to the big data platform in the cloud. On the edge side, there is a high requirement for real-time performance, but the data volume may not be large, typically ranging from a few thousand to tens of thousands of monitoring points in a workshop. On the central side, computing resources are generally abundant, capable of aggregating data from the edge side for analysis and computation.
To achieve this operation, the requirements for the database or data storage layer are to ensure that data can be reported step by step and selectively. In some scenarios, where the overall data volume is very large, selective reporting is necessary. For example, raw records collected every second on the edge side, when reported to the central side, are downsampled to once a minute, which greatly reduces the data volume but still retains key information for long-term data analysis and prediction.
In the past industrial data collection process, data was collected from industrial logic controllers PLCs, then entered into Historian, the industrial real-time database, to support business applications. These systems are not easy to scale horizontally, and are heavily dependent on the Windows ecosystem, which is relatively closed.
TDengine's Edge-Cloud Collaboration Solution
TDengine Enterprise is committed to providing powerful edge-cloud collaboration capabilities, with the following notable features:
- Efficient data synchronization: Supports synchronization efficiency of millions of data per second, ensuring fast and stable data transmission between the edge side and the cloud.
- Multi-data source integration: Compatible with various external data sources, such as AVEVA PI System, OPC-UA, OPC-DA, MQTT, etc., to achieve broad data access and integration.
- Flexible configuration of synchronization rules: Provides configurable synchronization rules, allowing users to customize the strategy and method of data synchronization according to actual needs.
- Offline continuation and re-subscription: Supports offline continuation and re-subscription functions, ensuring the continuity and integrity of data synchronization in the event of unstable or interrupted networks.
- Historical data migration: Supports the migration of historical data, facilitating users to seamlessly migrate historical data to a new system when upgrading or replacing systems.
TDengine's data subscription feature offers great flexibility to subscribers, allowing users to configure subscription objects as needed. Users can subscribe to a database, a supertable, or even a query statement with filtering conditions. This enables users to implement selective data synchronization, syncing truly relevant data (including offline and out-of-order data) from one cluster to another to meet the data needs of various complex scenarios.
The following diagram illustrates the implementation of an edge-cloud collaboration architecture in TDengine Enterprise using a specific production workshop example. In the production workshop, real-time data generated by equipment is stored in TDengine deployed on the edge side. The TDengine deployed in the branch factory subscribes to the data from the TDengine in the production workshop. To better meet business needs, data analysts set some subscription rules, such as data downsampling or syncing only data exceeding a specified threshold. Similarly, the TDengine deployed on the corporate side then subscribes to data from various branch factories, achieving corporate-level data aggregation, ready for further analysis and processing.
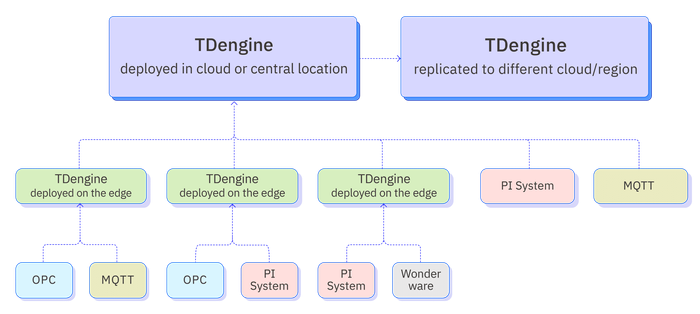
This implementation approach has the following advantages:
- No coding required, just simple configuration on the edge side and cloud.
- Greatly improved automation of cross-regional data synchronization, reducing error rates.
- No need for data caching, reducing batch sending, avoiding traffic peak congestion bandwidth.
- Data synchronization through subscription, with configurable rules, simple, flexible, and highly real-time.
- Both edge and cloud use TDengine, completely unifying the data model, reducing data governance difficulty.
Manufacturing enterprises often face a pain point in data synchronization. Many enterprises currently use offline methods to synchronize data, but TDengine Enterprise achieves real-time data synchronization with configurable rules. This method can avoid the resource waste and bandwidth congestion risks caused by regular large data transfers.
Advantages of Edge-Cloud Collaboration
The IT and OT (Operational Technology) construction conditions of traditional industries vary, and compared to the internet industry, most enterprises are significantly behind in digital investment. Many enterprises still use outdated systems to process data, which are often independent of each other, forming so-called data silos.
In this context, to inject new vitality into traditional industries with AI, the primary task is to integrate systems scattered in various corners and their collected data, breaking the limitations of data silos. However, this process is full of challenges, as it involves multiple systems and a plethora of industrial Internet protocols, and data aggregation is not a simple merging task. It requires cleaning, processing, and handling data from different sources to integrate it into a unified platform.
When all data is aggregated into one system, the efficiency of accessing and processing data is significantly improved. Enterprises can respond more quickly to real-time data, solve problems more effectively, and achieve efficient collaboration among internal and external staff, enhancing overall operational efficiency.
Additionally, after data aggregation, advanced third-party AI analysis tools can be utilized for improved anomaly detection, real-time alerts, and provide more accurate predictions for production capacity, cost, and equipment maintenance. This will enable decision-makers to better grasp the overall macro situation, provide strong support for the development of the enterprise, and help traditional industries achieve digital transformation and intelligent upgrades.