Data Model and Architecture
Data Model
A Typical IoT Scenario
In typical industry IoT, Internet of Vehicles and Operation Monitoring scenarios, there are often many different types of data collecting devices that collect one or more different physical metrics. However, for the data collection devices of the same type, there are often many specific collection devices distributed in places. Big Data processing system aims to collect all kinds of data, then store and analyze them. For the same kind of devices, the data collected are very structured. Taking smart meters as an example, assuming that each smart meter collects three metrics of current, voltage and phase, the collected data are similar to the following table:
| Device ID | Time Stamp | Collected Metrics | Tags | |||
|---|---|---|---|---|---|---|
| Device ID | Time Stamp | current | voltage | phase | location | groupId |
| d1001 | 1538548685000 | 10.3 | 219 | 0.31 | Beijing.Chaoyang | 2 |
| d1002 | 1538548684000 | 10.2 | 220 | 0.23 | Beijing.Chaoyang | 3 |
| d1003 | 1538548686500 | 11.5 | 221 | 0.35 | Beijing.Haidian | 3 |
| d1004 | 1538548685500 | 13.4 | 223 | 0.29 | Beijing.Haidian | 2 |
| d1001 | 1538548695000 | 12.6 | 218 | 0.33 | Beijing.Chaoyang | 2 |
| d1004 | 1538548696600 | 11.8 | 221 | 0.28 | Beijing.Haidian | 2 |
| d1002 | 1538548696650 | 10.3 | 218 | 0.25 | Beijing.Chaoyang | 3 |
| d1001 | 1538548696800 | 12.3 | 221 | 0.31 | Beijing.Chaoyang | 2 |
Each data record contains the device ID, timestamp, collected metrics (current, voltage, phase as above), and static tags (Location and groupId in Table 1) associated with the devices. Each device generates a data record in a pre-defined timer or triggered by an external event. It is a sequence of data points like a stream.
Data Characteristics
As the data points are a series of data points over time, the data points generated by IoT, Internet of Vehicles, and Operation Monitoring have some strong common characteristics:
- Metrics are always structured data;
- There are rarely delete/update operations on collected data;
- Unlike traditional databases, transaction processing is not required;
- The ratio of writing over reading is much higher than typical Internet applications;
- Data volume is stable and can be predicted according to the number of devices and sampling rate;
- The user pays attention to the trend of data, not a specific value at a specific time;
- There is always a data retention policy;
- The data query is always executed in a given time range and a subset of space;
- In addition to storage and query operations, various statistical and real-time computing are also required;
- Data volume is huge, a system may generate over 10 billion data points in a day.
By utilizing the above characteristics, TDengine designs the storage and computing engine in a special and optimized way for time-series data, resulting in massive improvements in system efficiency.
Relational Database Model
Since time-series data is most likely to be structured data, TDengine adopts the traditional relational database model to process them with a short learning curve. You need to create a database, create tables with schema definitions, then insert data points and execute queries to explore the data. SQL like syntax is used, instead of NoSQL’s key-value storage.
One Table for One Data Collection Point
To utilize this time-series and other data features, TDengine requires the user to create a table for each data collection point to store collected time-series data. For example, if there are over 10 million smart meters, it means 10 million tables shall be created. For the table above, 4 tables shall be created for devices D1001, D1002, D1003, and D1004 to store the data collected. This design has several advantages:
- Guarantee that all data from a data collection point can be saved in a continuous memory/hard disk space block by block. If queries are applied only on one data collection point in a time range, this design will reduce the random read latency significantly, thus increase read and query speed by orders of magnitude.
- Since the data generation process of each data collection device is completely independent, and each data collection point has its unique data source, thus writes can be carried out in a lock-free manner to greatly improve the performance.
- Write latency can be significantly reduced too as the data points generated by the same device will arrive in time order, the new data point will be simply appended to a block.
If the data of multiple devices are traditionally written into a table, due to the uncontrollable network delay, the timing of the data from different devices arriving at the server cannot be guaranteed, the writing operation must be protected by locks, and the data of one device cannot be guaranteed to be continuously stored together. One table for each data collection point can ensure the optimal performance of insert and query of a single data collection point to the greatest extent.
TDengine suggests using data collection point ID as the table name (like D1001 in the above table). Each point may collect one or more metrics (like the current, voltage, phase as above). Each metric has a column in the table. The data type for a column can be int, float, string and others. In addition, the first column in the table must be a timestamp. TDengine uses the time stamp as the index, and won’t build the index on any metrics stored. All data will be stored in columns.
STable: A Collection of Data Points in the Same Type
The design of one table for each data collection point will require a huge number of tables, which is difficult to manage. Moreover, applications often need to take aggregation operations between data collection points, thus aggregation operations will become complicated. To support aggregation over multiple tables efficiently, the STable(Super Table) concept is introduced by TDengine.
STable is an abstract set for a type of data collection point. A STable contains a set of data collection points (tables) that have the same schema or data structure, but with different static attributes (tags). To describe a STable (a set of data collection points of a specific type), in addition to defining the table structure of the collected metrics, it is also necessary to define the schema of its tags. The data type of tags can be int, float, string, and there can be multiple tags, which can be added, deleted, or modified afterward. If the whole system has N different types of data collection points, N STables need to be established.
In the design of TDengine, a table is used to represent a specific data collection point, and STable is used to represent a set of data collection points of the same type. When creating a table for a specific data collection point, the user uses the definition of STable as a template and specifies the tag value of the specific collection point (table). Compared with the traditional relational database, the table (a data collection point) has static tags, and these tags can be added, deleted, and modified afterward. A STable contains multiple tables with the same time-series data schema but different tag values.
When aggregating multiple data collection points with the same data type, TDengine will first find out the tables that meet the tag filter conditions from the STables, then scan the time-series data of these tables to perform aggregation operation, which can greatly reduce the data sets to be scanned, thus greatly improving the performance of data aggregation.
Cluster and Primary Logic Unit
The design of TDengine is based on the assumption that one single node or software system is unreliable and that no single node can provide sufficient computing and storage resources to process massive data. Therefore, TDengine has been designed in a distributed and high-reliability architecture since day one of the development, so that hardware failure or software failure of any single or multiple servers will not affect the availability and reliability of the system. At the same time, through node virtualization and automatic load-balancing technology, TDengine can make the most efficient use of computing and storage resources in heterogeneous clusters to reduce hardware investment.
Primary Logic Unit
Logical structure diagram of TDengine distributed architecture as following:
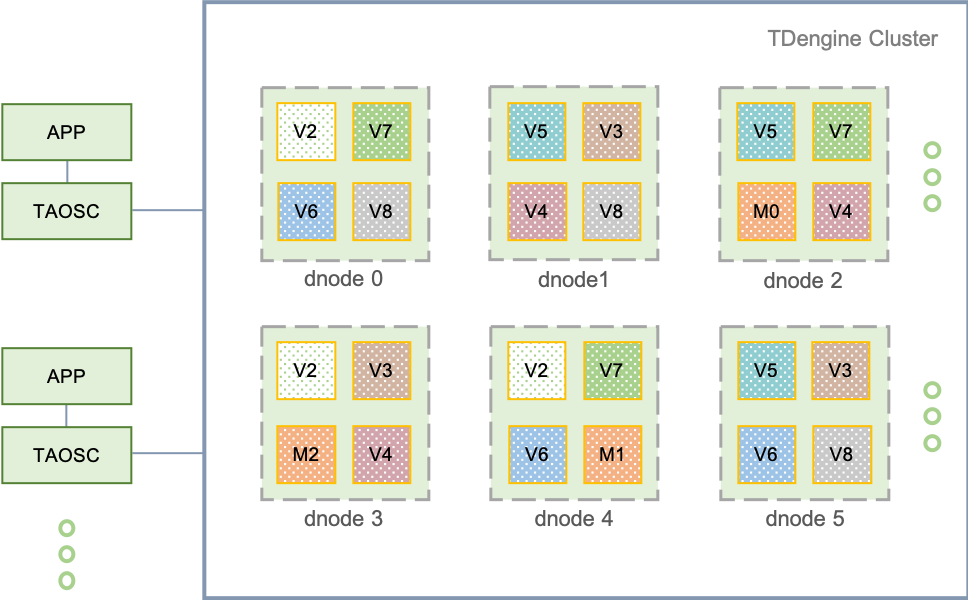
A complete TDengine system runs on one or more physical nodes. Logically, it includes data node (dnode), TDengine application driver (TAOSC) and application (app). There are one or more data nodes in the system, which form a cluster. The application interacts with the TDengine cluster through TAOSC's API. The following is a brief introduction to each logical unit.
Physical node (pnode): A pnode is a computer that runs independently and has its own computing, storage and network capabilities. It can be a physical machine, virtual machine, or Docker container installed with OS. The physical node is identified by its configured FQDN (Fully Qualified Domain Name). TDengine relies entirely on FQDN for network communication.
Data node (dnode): A dnode is a running instance of the TDengine server-side execution code taosd on a physical node. A working system must have at least one data node. A dnode contains zero to multiple logical virtual nodes (VNODE), zero or at most one logical management node (mnode). The unique identification of a dnode in the system is determined by the instance's End Point (EP). EP is a combination of FQDN (Fully Qualified Domain Name) of the physical node where the dnode is located and the network port number (Port) configured by the system. By configuring different ports, a physical node (a physical machine, virtual machine or container) can run multiple instances or have multiple data nodes.
Virtual node (vnode): To better support data sharding, load balancing and prevent data from overheating or skewing, data nodes are virtualized into multiple virtual nodes (vnode, V2, V3, V4, etc. in the figure). Each vnode is a relatively independent work unit, which is the basic unit of time-series data storage and has independent running threads, memory space and persistent storage path. A vnode contains a certain number of tables (data collection points). When a new table is created, the system checks whether a new vnode needs to be created. The number of vnodes that can be created on a data node depends on the hardware capacities of the physical node where the data node is located. A vnode belongs to only one DB, but a DB can have multiple vnodes. In addition to the stored time-series data, a vnode also stores the schema and tag values of the included tables. A virtual node is uniquely identified in the system by the EP of the data node and the VGroup ID to which it belongs and is created and managed by the management node.
Management node (mnode): A virtual logical unit responsible for monitoring and maintaining the running status of all data nodes and load balancing among nodes (M in the figure). At the same time, the management node is also responsible for the storage and management of metadata (including users, databases, tables, static tags, etc.), so it is also called Meta Node. Multiple (up to 5) mnodes can be configured in a TDengine cluster, and they are automatically constructed into a virtual management node group (M0, M1, M2 in the figure). The leader/follower mechanism is adopted for the mnode group and the data synchronization is carried out in a strongly consistent way. Any data update operation can only be executed on the leader. The creation of mnode cluster is completed automatically by the system without manual intervention. There is at most one mnode on each dnode, which is uniquely identified by the EP of the data node to which it belongs. Each dnode automatically obtains the EP of the dnode where all mnodes in the whole cluster are located through internal messaging interaction.
Virtual node group (VGroup): Vnodes on different data nodes can form a virtual node group to ensure the high availability of the system. The virtual node group is managed in a leader/follower mechanism. Write operations can only be performed on the leader vnode, and then replicated to follower vnodes, thus ensuring that one single replica of data is copied on multiple physical nodes. The number of virtual nodes in a vgroup equals the number of data replicas. If the number of replicas of a DB is N, the system must have at least N data nodes. The number of replicas can be specified by the parameter “replica” when creating DB, and the default is 1. Using the multi-replication feature of TDengine, the same high data reliability can be achieved without the need for expensive storage devices such as disk arrays. Virtual node group is created and managed by the management node, and the management node assigns a system unique ID, aka VGroup ID. If two virtual nodes have the same vnode group ID, means that they belong to the same group and the data is backed up to each other. The number of virtual nodes in a virtual node group can be dynamically changed, allowing only one, that is, no data replication. VGroup ID is never changed. Even if a virtual node group is deleted, its ID will not be reused.
TAOSC: TAOSC is the driver provided by TDengine to applications, which is responsible for dealing with the interaction between application and cluster, and provides the native interface of C/C++ language, which is embedded in JDBC, C #, Python, Go, Node.js language connection libraries. Applications interact with the whole cluster through TAOSC instead of directly connecting to data nodes in the cluster. This module is responsible for obtaining and caching metadata; forwarding requests for insertion, query, etc. to the correct data node; when returning the results to the application, TAOSC also needs to be responsible for the final level of aggregation, sorting, filtering and other operations. For JDBC, C/C++/C #/Python/Go/Node.js interfaces, this module runs on the physical node where the application is located. At the same time, in order to support the fully distributed RESTful interface, TAOSC has a running instance on each dnode of TDengine cluster.
Node Communication
Communication mode: The communication among each data node of TDengine system, and among the application driver and each data node is carried out through TCP/UDP. Considering an IoT scenario, the data writing packets are generally not large, so TDengine uses UDP in addition to TCP for transmission, because UDP is more efficient and is not limited by the number of connections. TDengine implements its own timeout, retransmission, confirmation and other mechanisms to ensure reliable transmission of UDP. For packets with a data volume of less than 15K, UDP is adopted for transmission, and TCP is automatically adopted for transmission of packets with a data volume of more than 15K or query operations. At the same time, TDengine will automatically compress/decompress the data, digital sign/authenticate the data according to the configuration and data packet. For data replication among data nodes, only TCP is used for data transportation.
FQDN configuration: A data node has one or more FQDNs, which can be specified in the system configuration file taos.cfg with the parameter “fqdn”. If it is not specified, the system will automatically use the hostname of the computer as its FQDN. If the node is not configured with FQDN, you can directly set the configuration parameter “fqdn” of the node to its IP address. However, IP is not recommended because IP address may be changed, and once it changes, the cluster will not work properly. The EP (End Point) of a data node consists of FQDN + Port. With FQDN, it is necessary to ensure the DNS service is running, or hosts files on nodes are configured properly.
Port configuration: The external port of a data node is determined by the system configuration parameter “serverPort” in TDengine, and the port for internal communication of cluster is serverPort+5. The data replication operation among data nodes in the cluster also occupies a TCP port, which is serverPort+10. In order to support multithreading and efficient processing of UDP data, each internal and external UDP connection needs to occupy 5 consecutive ports. Therefore, the total port range of a data node will be serverPort to serverPort + 10, for a total of 11 TCP/UDP ports. To run the system, make sure that the firewall keeps these ports open. Each data node can be configured with a different serverPort.
Cluster external connection: TDengine cluster can accommodate one single, multiple or even thousands of data nodes. The application only needs to initiate a connection to any data node in the cluster. The network parameter required for connection is the End Point (FQDN plus configured port number) of a data node. When starting the application taos through CLI, the FQDN of the data node can be specified through the option -h, and the configured port number can be specified through -p. If the port is not configured, the system configuration parameter “serverPort” of TDengine will be adopted.
Inter-cluster communication: Data nodes connect with each other through TCP/UDP. When a data node starts, it will obtain the EP information of the dnode where the mnode is located, and then establish a connection with the mnode in the system to exchange information. There are three steps to obtain EP information of the mnode:
- Check whether the mnodeEpList file exists, if it does not exist or cannot be opened normally to obtain EP information of the mnode, skip to the second step;
- Check the system configuration file taos.cfg to obtain node configuration parameters “firstEp” and “secondEp” (the node specified by these two parameters can be a normal node without mnode, in this case, the node will try to redirect to the mnode node when connected). If these two configuration parameters do not exist or do not exist in taos.cfg, or are invalid, skip to the third step;
- Set your own EP as a mnode EP and run it independently. After obtaining the mnode EP list, the data node initiates the connection. It will successfully join the working cluster after connection. If not successful, it will try the next item in the mnode EP list. If all attempts are made, but the connection still fails, sleep for a few seconds before trying again.
The choice of MNODE: TDengine logically has a management node, but there is no separated execution code. The server-side only has a set of execution code taosd. So which data node will be the management node? This is determined automatically by the system without any manual intervention. The principle is as follows: when a data node starts, it will check its End Point and compare it with the obtained mnode EP List. If its EP exists in it, the data node shall start the mnode module and become a mnode. If your own EP is not in the mnode EP List, the mnode module will not start. During the system operation, due to load balancing, downtime and other reasons, mnode may migrate to the new dnode, while totally transparent without manual intervention. The modification of configuration parameters is the decision made by mnode itself according to resources usage.
Add new data nodes: After the system has a data node, it has become a working system. There are two steps to add a new node into the cluster. Step1: Connect to the existing working data node using TDengine CLI, and then add the End Point of the new data node with the command "create dnode"; Step 2: In the system configuration parameter file taos.cfg of the new data node, set the “firstEp” and “secondEp” parameters to the EP of any two data nodes in the existing cluster. Please refer to the detailed user tutorial for detailed steps. In this way, the cluster will be established step by step.
Redirection: No matter about dnode or TAOSC, the connection to the mnode shall be initiated first, but the mnode is automatically created and maintained by the system, so the user does not know which dnode is running the mnode. TDengine only requires a connection to any working dnode in the system. Because any running dnode maintains the currently running mnode EP List, when receiving a connecting request from the newly started dnode or TAOSC, if it’s not a mnode by self, it will reply to the mnode EP List back. After receiving this list, TAOSC or the newly started dnode will try to establish the connection again. When the mnode EP List changes, each data node quickly obtains the latest list and notifies TAOSC through messaging interaction among nodes.
A Typical Data Writing Process
To explain the relationship between vnode, mnode, TAOSC and application and their respective roles, the following is an analysis of a typical data writing process.
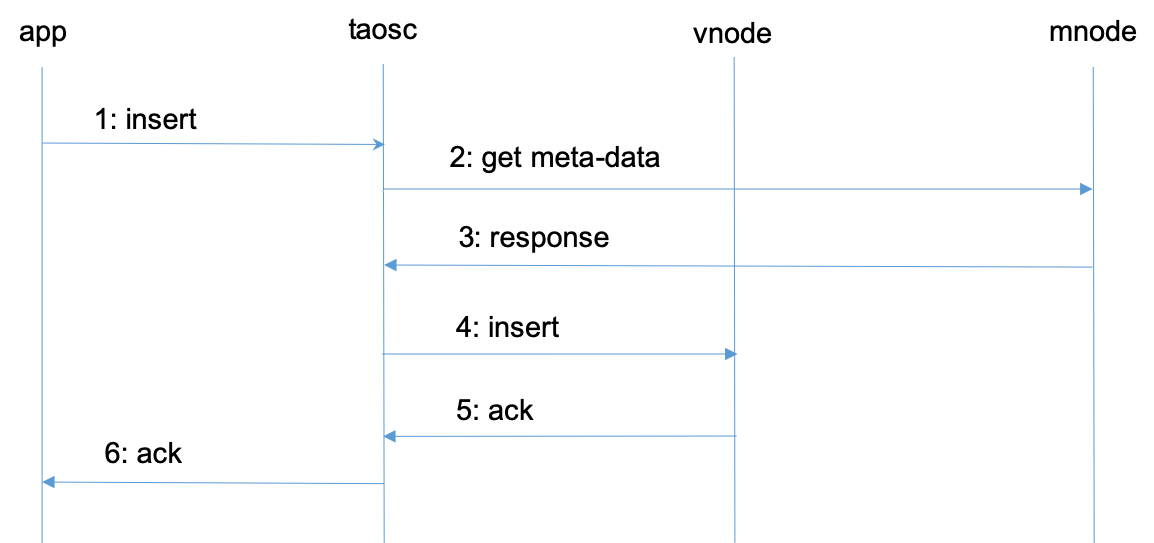
- Application initiates a request to insert data through JDBC, ODBC, or other APIs.
- TAOSC checks if meta data existing for the table in the cache. If so, go straight to Step 4. If not, TAOSC sends a get meta-data request to mnode.
- Mnode returns the meta-data of the table to TAOSC. Meta-data contains the schema of the table, and also the vgroup information to which the table belongs (the vnode ID and the End Point of the dnode where the table belongs. If the number of replicas is N, there will be N groups of End Points). If TAOSC does not receive a response from the mnode for a long time, and there are multiple mnodes, TAOSC will send a request to the next mnode.
- TAOSC initiates an insert request to leader vnode.
- After vnode inserts the data, it gives a reply to TAOSC, indicating that the insertion is successful. If TAOSC doesn't get a response from vnode for a long time, TAOSC will treat this node as offline. In this case, if there are multiple replicas of the inserted database, TAOSC will issue an insert request to the next vnode in vgroup.
- TAOSC notifies APP that writing is successful.
For Step 2 and 3, when TAOSC starts, it does not know the End Point of mnode, so it will directly initiate a request to the configured serving End Point of the cluster. If the dnode that receives the request does not have a mnode configured, it will inform the mnode EP list in a reply message, so that TAOSC will re-issue a request to obtain meta-data to the EP of another new mnode.
For Step 4 and 5, without caching, TAOSC can't recognize the leader in the virtual node group, so assumes that the first vnode is the leader and sends a request to it. If this vnode is not the leader, it will reply to the actual leader as a new target where TAOSC shall send a request to. Once the reply of successful insertion is obtained, TAOSC will cache the information of leader node.
The above is the process of inserting data, and the processes of querying and computing are the same. TAOSC encapsulates and hides all these complicated processes, and it is transparent to applications.
Through TAOSC caching mechanism, mnode needs to be accessed only when a table is accessed for the first time, so mnode will not become a system bottleneck. However, because schema and vgroup may change (such as load balancing), TAOSC will interact with mnode regularly to automatically update the cache.
Storage Model and Data Partitioning/Sharding
Storage Model
The data stored by TDengine include collected time-series data, metadata related to database and tables, tag data, etc. These data are specifically divided into three parts:
- Time-series data: stored in vnode and composed of data, head and last files. The amount of data is large and query amount depends on the application scenario. Out-of-order writing is allowed, but delete operation is not supported for the time being, and update operation is only allowed when database “update” parameter is set to 1. By adopting the model with one table for each data collection point, the data of a given time period is continuously stored, and the writing against one single table is a simple appending operation. Multiple records can be read at one time, thus ensuring the insert and query operation of a single data collection point with the best performance.
- Tag data: meta files stored in vnode. Four standard operations of create, read, update and delete are supported. The amount of data is not large. If there are N tables, there are N records, so all can be stored in memory. To make tag filtering efficient, TDengine supports multi-core and multi-threaded concurrent queries. As long as the computing resources are sufficient, even in face of millions of tables, the tag filtering results will return in milliseconds.
- Metadata: stored in mnode, including system node, user, DB, Table Schema and other information. Four standard operations of create, delete, update and read are supported. The amount of these data are not large and can be stored in memory, moreover, the query amount is not large because of the client cache. Therefore, TDengine uses centralized storage management, however, there will be no performance bottleneck.
Compared with the typical NoSQL storage model, TDengine stores tag data and time-series data completely separately, which has two major advantages:
- Greatly reduce the redundancy of tag data storage: general NoSQL database or time-series database adopts K-V storage, in which Key includes a timestamp, a device ID and various tags. Each record carries these duplicated tags, so storage space is wasted. Moreover, if the application needs to add, modify or delete tags on historical data, it has to traverse the data and rewrite them again, which is extremely expensive to operate.
- Aggregate data efficiently between multiple tables: when aggregating data between multiple tables, it first finds out the tables which satisfy the filtering conditions, and then find out the corresponding data blocks of these tables to greatly reduce the data sets to be scanned, thus greatly improving the aggregation efficiency. Moreover, tag data is managed and maintained in a full-memory structure, and tag data queries in tens of millions can return in milliseconds.
Data Sharding
For large-scale data management, to achieve scale-out, it is generally necessary to adopt the Partitioning or Sharding strategy. TDengine implements data sharding via vnode, and time-series data partitioning via one data file for each time range.
VNode (Virtual Data Node) is responsible for providing writing, query and computing functions for collected time-series data. To facilitate load balancing, data recovery and support heterogeneous environments, TDengine splits a data node into multiple vnodes according to its computing and storage resources. The management of these vnodes is done automatically by TDengine and is completely transparent to the application.
For a single data collection point, regardless of the amount of data, a vnode (or vnode group, if the number of replicas is greater than 1) has enough computing resource and storage resource to process (if a 16-byte record is generated per second, the original data generated in one year will be less than 0.5 G), so TDengine stores all the data of a table (a data collection point) in one vnode instead of distributing the data to two or more dnodes. Moreover, a vnode can store data from multiple data collection points (tables), and the upper limit of the tables’ quantity for a vnode is one million. By design, all tables in a vnode belong to the same DB. On a data node, unless specially configured, the number of vnodes owned by a DB will not exceed the number of system cores.
When creating a DB, the system does not allocate resources immediately. However, when creating a table, the system will check if there is an allocated vnode with free tablespace. If so, the table will be created in the vacant vnode immediately. If not, the system will create a new vnode on a dnode from the cluster according to the current workload, and then a table. If there are multiple replicas of a DB, the system does not create only one vnode, but a vgroup (virtual data node group). The system has no limit on the number of vnodes, which is just limited by the computing and storage resources of physical nodes.
The meta data of each table (including schema, tags, etc.) is also stored in vnode instead of centralized storage in mnode. In fact, this means sharding of meta data, which is good for efficient and parallel tag filtering operations.
Data Partitioning
In addition to vnode sharding, TDengine partitions the time-series data by time range. Each data file contains only one time range of time-series data, and the length of the time range is determined by DB's configuration parameter “days”. This method of partitioning by time rang is also convenient to efficiently implement the data retention policy. As long as the data file exceeds the specified number of days (system configuration parameter “keep”), it will be automatically deleted. Moreover, different time ranges can be stored in different paths and storage media, so as to facilitate the tiered-storage. Cold/hot data can be stored in different storage media to reduce the storage cost.
In general, TDengine splits big data by vnode and time range in two dimensions to manage the data efficiently with horizontal scalability.
Load Balancing
Each dnode regularly reports its status (including hard disk space, memory size, CPU, network, number of virtual nodes, etc.) to the mnode (virtual management node), so mnode knows the status of the entire cluster. Based on the overall status, when the mnode finds a dnode is overloaded, it will migrate one or more vnodes to other dnodes. During the process, TDengine services keep running and the data insertion, query and computing operations are not affected.
If the mnode has not received the dnode status for a period of time, the dnode will be treated as offline. When offline lasts a certain period of time (configured by parameter “offlineThreshold”), the dnode will be forcibly removed from the cluster by mnode. If the number of replicas of vnodes on this dnode is greater than one, the system will automatically create new replicas on other dnodes to ensure the replica number. If there are other mnodes on this dnode and the number of mnodes replicas is greater than one, the system will automatically create new mnodes on other dnodes to ensure the replica number.
When new data nodes are added to the cluster, with new computing and storage resources are added, the system will automatically start the load balancing process.
The load balancing process does not require any manual intervention, and it is transparent to the application. Note: load balancing is controlled by parameter “balance”, which determines to turn on/off automatic load balancing.
Data Writing and Replication Process
If a database has N replicas, thus a virtual node group has N virtual nodes, but only one as leader and all others are followers. When the application writes a new record to system, only the leader vnode can accept the writing request. If a follower vnode receives a writing request, the system will notifies TAOSC to redirect.
Leader vnode Writing Process
Leader Vnode uses a writing process as follows:
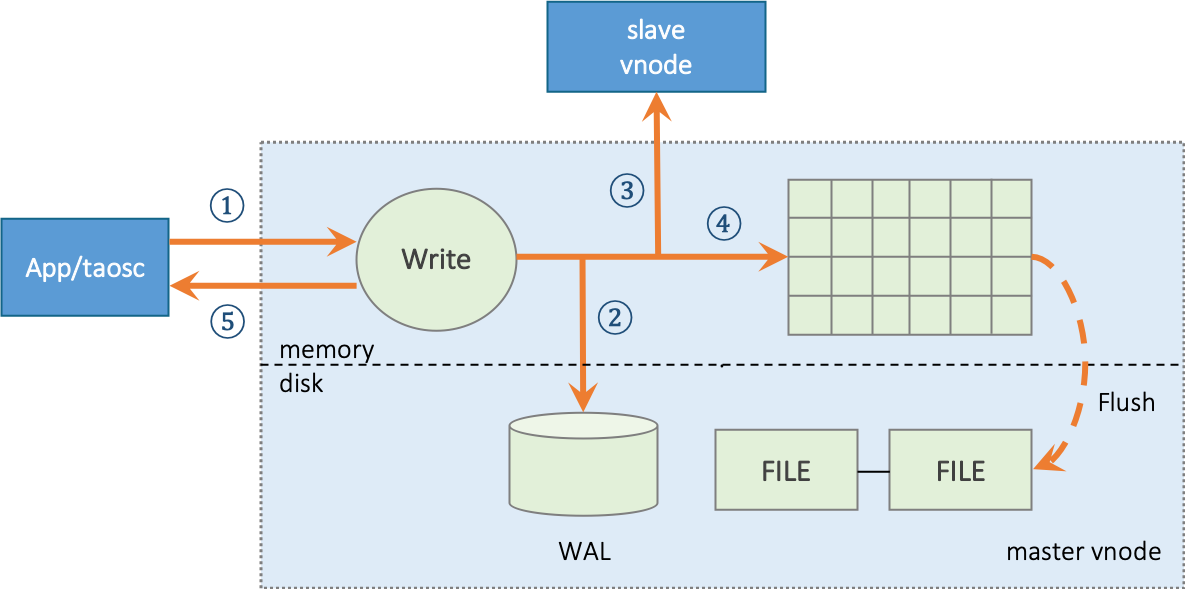
- Leader vnode receives the application data insertion request, verifies, and moves to next step;
- If the system configuration parameter
“walLevel”is greater than 0, vnode will write the original request packet into database log file WAL. If walLevel is set to 2 and fsync is set to 0, TDengine will make WAL data written immediately to ensure that even system goes down, all data can be recovered from database log file; - If there are multiple replicas, vnode will forward data packet to follower vnodes in the same virtual node group, and the forwarded packet has a version number with data;
- Write into memory and add the record to “skip list”;
- Leader vnode returns a confirmation message to the application, indicating a successful writing.
- If any of Step 2, 3 or 4 fails, the error will directly return to the application.
Follower vnode Writing Process
For a follower vnode, the write process as follows:
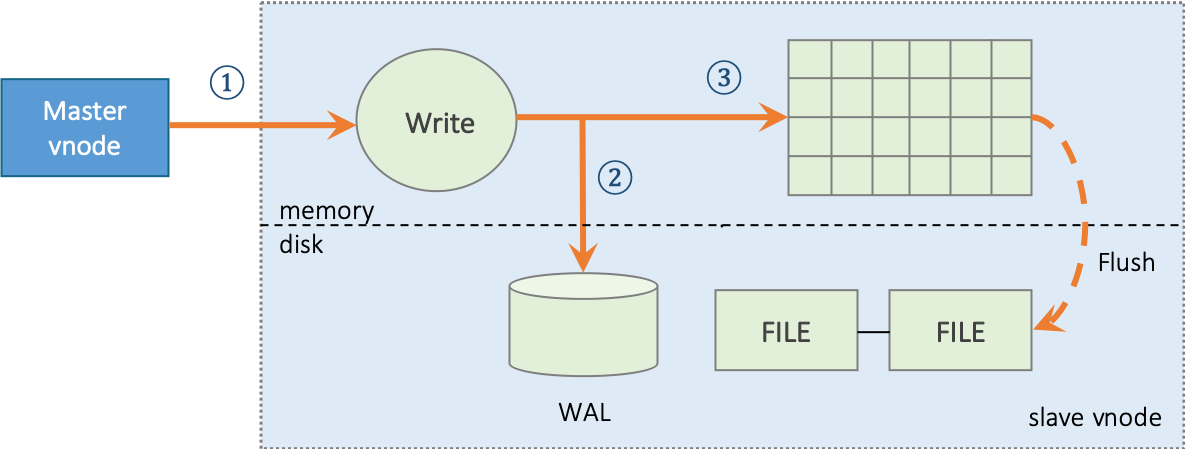
- Follower vnode receives a data insertion request forwarded by Leader vnode;
- If the system configuration parameter
“walLevel”is greater than 0, vnode will write the original request packet into database log file WAL. If walLevel is set to 2 and fsync is set to 0, TDengine will make WAL data written immediately to ensure that even system goes down, all data can be recovered from database log file; - Write into memory and add the record to “skip list”.
Compared with Leader vnode, follower vnode has no forwarding or reply confirmation step, means two steps less. But writing into memory and WAL is exactly the same.
Remote Disaster Recovery and IDC Migration
As above leader and follower processes discussed, TDengine adopts asynchronous replication for data synchronization. This method can greatly improve the writing performance, with no obvious impact from network delay. By configuring IDC and rack number for each physical node, it can be ensured that for a virtual node group, virtual nodes are composed of physical nodes from different IDC and different racks, thus implementing remote disaster recovery without other tools.
On the other hand, TDengine supports dynamic modification of the replicas number. Once the number of replicas increases, the newly added virtual nodes will immediately enter the data synchronization process. After synchronization completed, added virtual nodes can provide services. In the synchronization process, leader and other synchronized virtual nodes keep serving. With this feature, TDengine can provide IDC migration without service interruption. It is only necessary to add new physical nodes to the existing IDC cluster, and then remove old physical nodes after the data synchronization is completed.
However, the asynchronous replication has a tiny time window where data can be lost. The specific scenario is as follows:
- Leader vnode has finished its 5-step operations, confirmed the success of writing to APP, and then went down;
- Follower vnode receives the write request, then processing fails before writing to the log in Step 2;
- Follower vnode will become the new leader, thus losing one record.
In theory, for asynchronous replication, there is no guarantee to prevent data loss. However, this window is extremely small, only if mater and follower fail at the same time, and just confirm the successful write to the application before.
Note: Remote disaster recovery and no-downtime IDC migration are only supported by Enterprise Edition. Hint: This function is not available yet
Leader and Follower Selection
Vnode maintains a version number. When memory data is persisted, the version number will also be persisted. For each data update operation, whether it is time-series data or metadata, this version number will be increased by one.
When a vnode starts, the roles (leader, follower) are uncertain, and the data is in an unsynchronized state. It’s necessary to establish TCP connections with other nodes in the virtual node group and exchange status, including version and its own roles. Through the exchange, the system implements a leader-selection process. The rules are as follows:
- If there’s only one replica, it’s always leader
- When all replicas are online, the one with latest version is leader
- Over half of online nodes are virtual nodes, and some virtual node is follower, it will automatically become leader
- For 2 and 3, if multiple virtual nodes meet the requirement, the first vnode in virtual node group list will be selected as leader
Synchronous Replication
For scenarios with strong data consistency requirements, asynchronous data replication is not applicable, because there is a small probability of data loss. So, TDengine provides a synchronous replication mechanism for users. When creating a database, in addition to specifying the number of replicas, user also needs to specify a new parameter “quorum”. If quorum is greater than one, it means that every time the leader forwards a message to the replica, it needs to wait for “quorum-1” reply confirms before informing the application that data has been successfully written in follower. If “quorum-1” reply confirms are not received within a certain period of time, the leader vnode will return an error to the application.
With synchronous replication, performance of system will decrease and latency will increase. Because metadata needs strong consistent, the default for data synchronization between mnodes is synchronous replication.
Caching and Persistence
Caching
TDengine adopts a time-driven cache management strategy (First-In-First-Out, FIFO), also known as a Write-driven Cache Management Mechanism. This strategy is different from the read-driven data caching mode (Least-Recent-Used, LRU), which directly put the most recently written data in the system buffer. When the buffer reaches a threshold, the earliest data are written to disk in batches. Generally speaking, for the use of IoT data, users are most concerned about the newly generated data, that is, the current status. TDengine takes full advantage of this feature to put the most recently arrived (current state) data in the buffer.
TDengine provides millisecond-level data collecting capability to users through query functions. Putting the recently arrived data directly in the buffer can respond to users' analysis query for the latest piece or batch of data more quickly, and provide faster database query response capability as a whole. In this sense, TDengine can be used as a data buffer by setting appropriate configuration parameters without deploying Redis or other additional cache systems, which can effectively simplify the system architecture and reduce the operation costs. It should be noted that after the TDengine is restarted, the buffer of the system will be emptied, the previously cached data will be written to disk in batches, and the previously cached data will not be reloaded into the buffer as so in a proprietary key-value cache system.
Each vnode has its own independent memory, and it is composed of multiple memory blocks of fixed size, and different vnodes are completely isolated. When writing data, similar to the writing of logs, data is sequentially added to memory, but each vnode maintains its own skip list for quick search. When more than one third of the memory block are used, the disk writing operation will start, and the subsequent writing operation is carried out in a new memory block. By this design, one third of the memory blocks in a vnode keep the latest data, so as to achieve the purpose of caching and quick search. The number of memory blocks of a vnode is determined by the configuration parameter “blocks”, and the size of memory blocks is determined by the configuration parameter “cache”.
Persistent Storage
TDengine uses a data-driven method to write the data from buffer into hard disk for persistent storage. When the cached data in vnode reaches a certain volume, TDengine will also pull up the disk-writing thread to write the cached data into persistent storage in order not to block subsequent data writing. TDengine will open a new database log file when the data is written, and delete the old database log file after written successfully to avoid unlimited log growth.
To make full use of the characteristics of time-series data, TDengine splits the data stored in persistent storage by a vnode into multiple files, each file only saves data for a fixed number of days, which is determined by the system configuration parameter “days”. By so, for the given start and end date of a query, you can locate the data files to open immediately without any index, thus greatly speeding up reading operations.
For time-series data, there is generally a retention policy, which is determined by the system configuration parameter “keep”. Data files exceeding this set number of days will be automatically deleted by the system to free up storage space.
Given “days” and “keep” parameters, the total number of data files in a vnode is: keep/days. The total number of data files should not be too large or too small. 10 to 100 is appropriate. Based on this principle, reasonable days can be set. In the current version, parameter “keep” can be modified, but parameter “days” cannot be modified once it is set.
In each data file, the data of a table is stored by blocks. A table can have one or more data file blocks. In a file block, data is stored in columns, occupying a continuous storage space, thus greatly improving the reading speed. The size of file block is determined by the system parameter “maxRows” (the maximum number of records per block), and the default value is 4096. This value should not be too large or too small. If it is too large, the data locating in search will cost longer; if too small, the index of data block is too large, and the compression efficiency will be low with slower reading speed.
Each data file (with a .data postfix) has a corresponding index file (with a .head postfix). The index file has summary information of a data block for each table, recording the offset of each data block in the data file, start and end time of data and other information, so as to lead system quickly locate the data to be found. Each data file also has a corresponding last file (with a .last postfix), which is designed to prevent data block fragmentation when written in disk. If the number of written records from a table does not reach the system configuration parameter “minRows” (minimum number of records per block), it will be stored in the last file first. When write to disk next time, the newly written records will be merged with the records in last file and then written into data file.
When data is written to disk, it is decided whether to compress the data according to system configuration parameter “comp”. TDengine provides three compression options: no compression, one-stage compression and two-stage compression, corresponding to comp values of 0, 1 and 2 respectively. One-stage compression is carried out according to the type of data. Compression algorithms include delta-delta coding, simple 8B method, zig-zag coding, LZ4 and other algorithms. Two-stage compression is based on one-stage compression and compressed by general compression algorithm, which has higher compression ratio.
Tiered Storage
By default, TDengine saves all data in /var/lib/taos directory, and the data files of each vnode are saved in a different directory under this directory. In order to expand the storage space, minimize the bottleneck of file reading and improve the data throughput rate, TDengine can configure the system parameter “dataDir” to allow multiple mounted hard disks to be used by system at the same time. In addition, TDengine also provides the function of tiered data storage, i.e. storage on different storage media according to the time stamps of data files. For example, the latest data is stored on SSD, the data for more than one week is stored on local hard disk, and the data for more than four weeks is stored on network storage device, thus reducing the storage cost and ensuring efficient data access. The movement of data on different storage media is automatically done by the system and completely transparent to applications. Tiered storage of data is also configured through the system parameter “dataDir”.
dataDir format is as follows:
dataDir data_path [tier_level]
Where data_path is the folder path of mount point and tier_level is the media storage-tier. The higher the media storage-tier, means the older the data file. Multiple hard disks can be mounted at the same storage-tier, and data files on the same storage-tier are distributed on all hard disks within the tier. TDengine supports up to 3 tiers of storage, so tier_level values are 0, 1, and 2. When configuring dataDir, there must be only one mount path without specifying tier_level, which is called special mount disk (path). The mount path defaults to level 0 storage media and contains special file links, which cannot be removed, otherwise it will have a devastating impact on the written data.
Suppose a physical node with six mountable hard disks/mnt/disk1,/mnt/disk2, …,/mnt/disk6, where disk1 and disk2 need to be designated as level 0 storage media, disk3 and disk4 are level 1 storage media, and disk5 and disk6 are level 2 storage media. Disk1 is a special mount disk, you can configure it in/etc/taos/taos.cfg as follows:
dataDir /mnt/disk1/taos
dataDir /mnt/disk2/taos 0
dataDir /mnt/disk3/taos 1
dataDir /mnt/disk4/taos 1
dataDir /mnt/disk5/taos 2
dataDir /mnt/disk6/taos 2
Mounted disks can also be a non-local network disk, as long as the system can access it.
Note: Tiered Storage is only supported in Enterprise Edition
Data Query
TDengine provides a variety of query processing functions for tables and STables. In addition to common aggregation queries, TDengine also provides window queries and statistical aggregation functions for time-series data. The query processing of TDengine needs the collaboration of client, vnode and mnode.
Single Table Query
The parsing and verification of SQL statements are completed on the client side. SQL statements are parsed and generate an Abstract Syntax Tree (AST), which is then checksummed. Then request metadata information (table metadata) for the table specified in the query from management node (mnode).
According to the End Point information in metadata information, the query request is serialized and sent to the data node (dnode) where the table is located. After receiving the query, the dnode identifies the virtual node (vnode) pointed to and forwards the message to the query execution queue of the vnode. The query execution thread of vnode establishes the basic query execution environment, immediately returns the query request and starts executing the query at the same time.
When client obtains query result, the worker thread in query execution queue of dnode will wait for the execution of vnode execution thread to complete before returning the query result to the requesting client.
Aggregation by Time Axis, Downsampling, Interpolation
The remarkable feature that time-series data is different from ordinary data is that each record has a timestamp, so aggregating data with timestamps on the time axis is an important and distinct feature from common databases. From this point of view, it is similar to the window query of stream computing engine.
The keyword interval is introduced into TDengine to split fixed length time windows on time axis, and the data are aggregated based on time windows, and the data within window range are aggregated as needed. For example:
select count(*) from d1001 interval(1h);
For the data collected by device D1001, the number of records stored per hour is returned by a 1-hour time window.
In application scenarios where query results need to be obtained continuously, if there is data missing in a given time interval, the data results in this interval will also be lost. TDengine provides a strategy to interpolate the results of timeline aggregation calculation. The results of time axis aggregation can be interpolated by using keyword Fill. For example:
select count(*) from d1001 interval(1h) fill(prev);
For the data collected by device D1001, the number of records per hour is counted. If there is no data in a certain hour, statistical data of the previous hour is returned. TDengine provides forward interpolation (prev), linear interpolation (linear), NULL value populating (NULL), and specific value populating (value).
Multi-table Aggregation Query
TDengine creates a separate table for each data collection point, but in practical applications, it is often necessary to aggregate data from different data collection points. In order to perform aggregation operations efficiently, TDengine introduces the concept of STable. STable is used to represent a specific type of data collection point. It is a table set containing multiple tables. The schema of each table in the set is the same, but each table has its own static tag. The tags can be multiple and be added, deleted and modified at any time. Applications can aggregate or statistically operate all or a subset of tables under a STABLE by specifying tag filters, thus greatly simplifying the development of applications. The process is shown in the following figure:
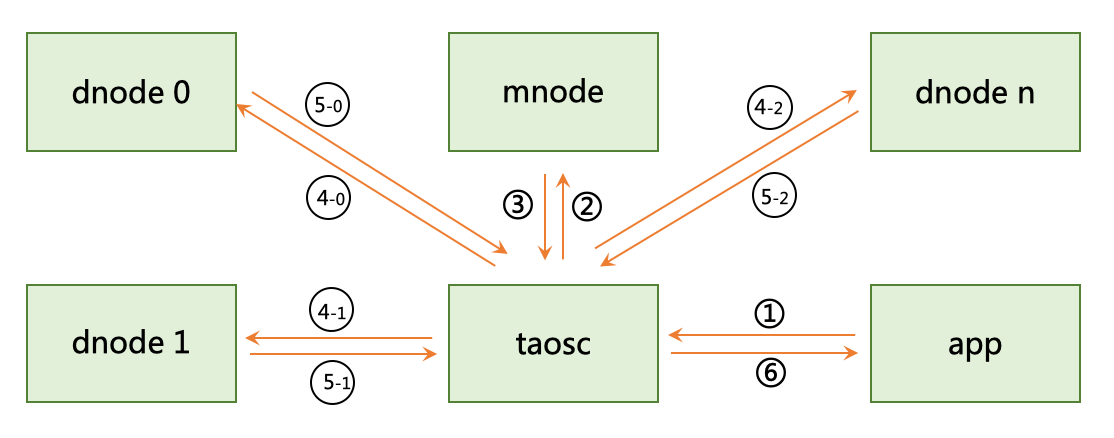
- Application sends a query condition to system;
- TAOSC sends the STable name to Meta Node(management node);
- Management node sends the vnode list owned by the STable back to TAOSC;
- TAOSC sends the computing request together with tag filters to multiple data nodes corresponding to these vnodes;
- Each vnode first finds out the set of tables within its own node that meet the tag filters from memory, then scans the stored time-series data, completes corresponding aggregation calculations, and returns result to TAOSC;
- TAOSC finally aggregates the results returned by multiple data nodes and send them back to application.
Since TDengine stores tag data and time-series data separately in vnode, by filtering tag data in memory, the set of tables that need to participate in aggregation operation is first found, which greatly reduces the volume of data scanned and improves aggregation speed. At the same time, because the data is distributed in multiple vnodes/dnodes, the aggregation operation is carried out concurrently in multiple vnodes, which further improves the aggregation speed. Aggregation functions for ordinary tables and most operations are applicable to STables. The syntax is exactly the same. Please see TAOS SQL for details.
Precomputation
In order to effectively improve the performance of query processing, based-on the unchangeable feature of IoT data, statistical information of data stored in data block is recorded in the head of data block, including max value, min value, and sum. We call it a precomputing unit. If the query processing involves all the data of a whole data block, the pre-calculated results are directly used, and no need to read the data block contents at all. Since the amount of pre-calculated data is much smaller than the actual size of data block stored on disk, for query processing with disk IO as bottleneck, the use of pre-calculated results can greatly reduce the pressure of reading IO and accelerate the query process. The precomputation mechanism is similar to the index BRIN (Block Range Index) of PostgreSQL.