TDengine Introduction
About TDengine
TDengine is a high-performance, scalable time-series database with SQL support. Its code, including its cluster feature is open source under GNU AGPL v3.0. Besides the database engine, it provides caching, stream processing, data subscription and other functionalities to reduce the complexity and cost of development and operation. TDengine differentiates itself from other TSDBs with the following advantages.
-
High Performance: TDengine outperforms other time series databases in data ingestion and querying while significantly reducing storage cost and compute costs, with an innovatively designed and purpose-built storage engine.
-
Scalable: TDengine provides out-of-box scalability and high-availability through its native distributed design. Nodes can be added through simple configuration to achieve greater data processing power. In addition, this feature is open source.
-
SQL Support: TDengine uses SQL as the query language, thereby reducing learning and migration costs, while adding SQL extensions to handle time-series data better, and supporting convenient and flexible schemaless data ingestion.
-
All in One: TDengine has built-in caching, stream processing and data subscription functions. It is no longer necessary to integrate Kafka/Redis/HBase/Spark or other software in some scenarios. It makes the system architecture much simpler, cost-effective and easier to maintain.
-
Seamless Integration: Without a single line of code, TDengine provide seamless, configurable integration with third-party tools such as Telegraf, Grafana, EMQX, Prometheus, StatsD, collectd, etc. More third-party tools are being integrated.
-
Zero Management: Installation and cluster setup can be done in seconds. Data partitioning and sharding are executed automatically. TDengine’s running status can be monitored via Grafana or other DevOps tools.
-
Zero Learning Cost: With SQL as the query language, support for ubiquitous tools like Python, Java, C/C++, Go, Rust, Node.js connectors, there is zero learning cost.
-
Interactive Console: TDengine provides convenient console access to the database to run ad hoc queries, maintain the database, or manage the cluster without any programming.
With TDengine, the total cost of ownership of typical IoT, Connected Vehicles, Industrial Internet, Energy, Financial, DevOps and other Big Data applications can be greatly reduced. Note that because TDengine makes full use of the characteristics of IoT time-series data and is highly optimized for it, TDengine cannot be used as a general purpose database engine to process general data from web crawlers, microblogs, WeChat, e-commerce, ERP, CRM, and other sources.
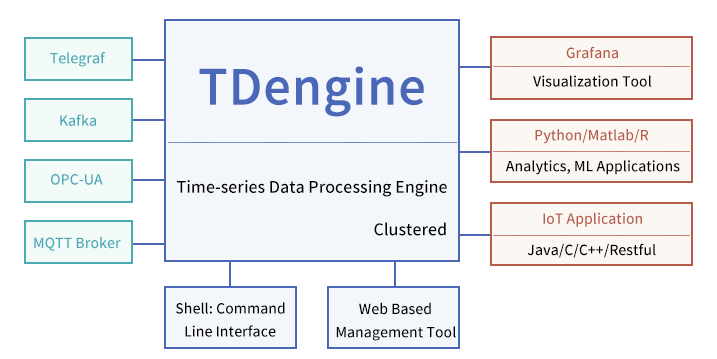
Overall Scenarios of TDengine
As an IoT time-series Big Data platform, TDengine is optimal for application scenarios with the requirements described below. Therefore the following sections of this document are mainly aimed at IoT-relevant systems. Other systems, such as CRM, ERP, etc., are beyond the scope of this article.
Characteristics and Requirements of Data Sources
From the perspective of data sources, designers can analyze the applicability of TDengine in target application systems as follows.
| Data Source Characteristics and Requirements | Not Applicable | Might Be Applicable | Very Applicable | Description |
|---|---|---|---|---|
| A massive amount of total data | √ | TDengine provides excellent scale-out functions in terms of capacity, and has a storage structure with matching high compression ratio to achieve the best storage efficiency in the industry. | ||
| Data input velocity is extremely high | √ | TDengine's performance is much higher than that of other similar products. It can continuously process larger amounts of input data in the same hardware environment, and provides a performance evaluation tool that can easily run in the user environment. | ||
| A huge number of data sources | √ | TDengine is optimized specifically for a huge number of data sources. It is especially suitable for efficiently ingesting, writing and querying data from billions of data sources. |
System Architecture Requirements
| System Architecture Requirements | Not Applicable | Might Be Applicable | Very Applicable | Description |
|---|---|---|---|---|
| A simple and reliable system architecture | √ | TDengine's system architecture is very simple and reliable, with its own message queue, cache, stream computing, monitoring and other functions. There is no need to integrate any additional third-party products. | ||
| Fault-tolerance and high-reliability | √ | TDengine has cluster functions to automatically provide high-reliability and high-availability functions such as fault tolerance and disaster recovery. | ||
| Standardization support | √ | TDengine supports standard SQL and also provides extensions specifically to analyze time-series data. |
System Function Requirements
| System Function Requirements | Not Applicable | Might Be Applicable | Very Applicable | Description |
|---|---|---|---|---|
| Complete data processing algorithms built-in | √ | While TDengine implements various general data processing algorithms, industry specific algorithms and special types of processing will need to be implemented at the application level. | ||
| A large number of crosstab queries | √ | This type of processing is better handled by general purpose relational database systems but TDengine can work in concert with relational database systems to provide more complete solutions. |
System Performance Requirements
| System Performance Requirements | Not Applicable | Might Be Applicable | Very Applicable | Description |
|---|---|---|---|---|
| Very large total processing capacity | √ | TDengine’s cluster functions can easily improve processing capacity via multi-server coordination. | ||
| Extremely high-speed data processing | √ | TDengine’s storage and data processing are optimized for IoT, and can process data many times faster than similar products. | ||
| Extremely fast processing of fine-grained data | √ | TDengine has achieved the same or better performance than other relational and NoSQL data processing systems. |
System Maintenance Requirements
| System Maintenance Requirements | Not Applicable | Might Be Applicable | Very Applicable | Description |
|---|---|---|---|---|
| Native high-reliability | √ | TDengine has a very robust, reliable and easily configurable system architecture to simplify routine operation. Human errors and accidents are eliminated to the greatest extent, with a streamlined experience for operators. | ||
| Minimize learning and maintenance costs | √ | In addition to being easily configurable, standard SQL support and the Taos shell for ad hoc queries makes maintenance simpler, allows reuse and reduces learning costs. | ||
| Abundant talent supply | √ | Given the above, and given the extensive training and professional services provided by TDengine, it is easy to migrate from existing solutions or create a new and lasting solution based on TDengine. |