TDengine System Architecture
Storage Design
TDengine data mainly include metadata and data that we will introduce in the following sections.
Metadata Storage
Metadata include the information of databases, tables, etc. Metadata files are saved in /var/lib/taos/mgmt/ directory by default. The directory tree is as below:
/var/lib/taos/
+--mgmt/
+--db.db
+--meters.db
+--user.db
+--vgroups.db
A metadata structure (database, table, etc.) is saved as a record in a metadata file. All metadata files are appended only, and even a drop operation adds a deletion record at the end of the file.
Data storage
Data in TDengine are sharded according to the time range. Data of tables in the same vnode in a certain time range are saved in the same filegroup, such as files v0f1804*. This sharding strategy can effectively improve data searching speed. By default, a group of files contains data in 10 days, which can be configured by daysPerFile in the configuration file or by DAYS keyword in CREATE DATABASE clause. Data in files are blockwised. A data block only contains one table's data. Records in the same data block are sorted according to the primary timestamp, which helps to improve the compression rate and save storage. The compression algorithms used in TDengine include simple8B, delta-of-delta, RLE, LZ4, etc.
By default, TDengine data are saved in /var/lib/taos/data/ directory. /var/lib/taos/tsdb/ directory contains vnode informations and data file linkes.
/var/lib/taos/
+--tsdb/
| +--vnode0
| +--meterObj.v0
| +--db/
| +--v0f1804.head->/var/lib/taos/data/vnode0/v0f1804.head1
| +--v0f1804.data->/var/lib/taos/data/vnode0/v0f1804.data
| +--v0f1804.last->/var/lib/taos/data/vnode0/v0f1804.last1
| +--v0f1805.head->/var/lib/taos/data/vnode0/v0f1805.head1
| +--v0f1805.data->/var/lib/taos/data/vnode0/v0f1805.data
| +--v0f1805.last->/var/lib/taos/data/vnode0/v0f1805.last1
| :
+--data/
+--vnode0/
+--v0f1804.head1
+--v0f1804.data
+--v0f1804.last1
+--v0f1805.head1
+--v0f1805.data
+--v0f1805.last1
:
meterObj file
There are only one meterObj file in a vnode. Informations bout the vnode, such as created time, configuration information, vnode statistic informations are saved in this file. It has the structure like below:
<start_of_file>
[file_header]
[table_record1_offset&length]
[table_record2_offset&length]
...
[table_recordN_offset&length]
[table_record1]
[table_record2]
...
[table_recordN]
<end_of_file>
The file header takes 512 bytes, which mainly contains informations about the vnode. Each table record is the representation of a table on disk.
head file
The head files contain the index of data blocks in the data file. The inner organization is as below:
<start_of_file>
[file_header]
[table1_offset]
[table2_offset]
...
[tableN_offset]
[table1_index_block]
[table2_index_block]
...
[tableN_index_block]
<end_of_file>
The table offset array in the head file saves the information about the offsets of each table index block. Indices on data blocks in the same table are saved continuously. This also makes it efficient to load data indices on the same table. The data index block has a structure like:
[index_block_info]
[block1_index]
[block2_index]
...
[blockN_index]
The index block info part contains the information about the index block such as the number of index blocks, etc. Each block index corresponds to a real data block in the data file or last file. Information about the location of the real data block, the primary timestamp range of the data block, etc. are all saved in the block index part. The block indices are sorted in ascending order according to the primary timestamp. So we can apply algorithms such as the binary search on the data to efficiently search blocks according to time.
data file
The data files store the real data block. They are append-only. The organization is as:
<start_of_file>
[file_header]
[block1]
[block2]
...
[blockN]
<end_of_file>
A data block in data files only belongs to a table in the vnode and the records in a data block are sorted in ascending order according to the primary timestamp key. Data blocks are column-oriented. Data in the same column are stored contiguously, which improves reading speed and compression rate because of their similarity. A data block has the following organization:
[column1_info]
[column2_info]
...
[columnN_info]
[column1_data]
[column2_data]
...
[columnN_data]
The column info part includes information about column types, column compression algorithm, column data offset and length in the data file, etc. Besides, pre-calculated results of the column data in the block are also in the column info part, which helps to improve reading speed by avoiding loading data block necessarily.
last file
To avoid storage fragment and to import query speed and compression rate, TDengine introduces an extra file, the last file. When the number of records in a data block is lower than a threshold, TDengine will flush the block to the last file for temporary storage. When new data comes, the data in the last file will be merged with the new data and form a larger data block and written to the data file. The organization of the last file is similar to the data file.
Summary
The innovation in architecture and storage design of TDengine improves resource usage. On the one hand, the virtualization makes it easy to distribute resources between different vnodes and for future scaling. On the other hand, sorted and column-oriented storage makes TDengine have a great advantage in writing, querying and compression.
Query Design
Introduction
TDengine provides a variety of query functions for both tables and super tables. In addition to regular aggregate queries, it also provides time window based query and statistical aggregation for time series data. TDengine's query processing requires the client app, management node, and data node to work together. The functions and modules involved in query processing included in each component are as follows:
Client (Client App). The client development kit, embed in a client application, consists of TAOS SQL parser and query executor, the second-stage aggregator (Result Merger), continuous query manager and other major functional modules. The SQL parser is responsible for parsing and verifying the SQL statement and converting it into an abstract syntax tree. The query executor is responsible for transforming the abstract syntax tree into the query execution logic and creates the metadata query according to the query condition of the SQL statement. Since TAOS SQL does not currently include complex nested queries and pipeline query processing mechanism, there is no longer need for query plan optimization and physical query plan conversions. The second-stage aggregator is responsible for performing the aggregation of the independent results returned by query involved data nodes at the client side to generate final results. The continuous query manager is dedicated to managing the continuous queries created by users, including issuing fixed-interval query requests and writing the results back to TDengine or returning to the client application as needed. Also, the client is also responsible for retrying after the query fails, canceling the query request, and maintaining the connection heartbeat and reporting the query status to the management node.
Management Node. The management node keeps the metadata of all the data of the entire cluster system, provides the metadata of the data required for the query from the client node, and divides the query request according to the load condition of the cluster. The super table contains information about all the tables created according to the super table, so the query processor (Query Executor) of the management node is responsible for the query processing of the tags of tables and returns the table information satisfying the tag query. Besides, the management node maintains the query status of the cluster in the Query Status Manager component, in which the metadata of all queries that are currently executing are temporarily stored in-memory buffer. When the client issues show queries command to management node, current running queries information is returned to the client.
Data Node. The data node, responsible for storing all data of the database, consists of query executor, query processing scheduler, query task queue, and other related components. Once the query requests from the client received, they are put into query task queue and waiting to be processed by query executor. The query executor extracts the query request from the query task queue and invokes the query optimizer to perform the basic optimization for the query execution plan. And then query executor scans the qualified data blocks in both cache and disk to obtain qualified data and return the calculated results. Besides, the data node also needs to respond to management information and commands from the management node. For example, after the kill query received from the management node, the query task needs to be stopped immediately.
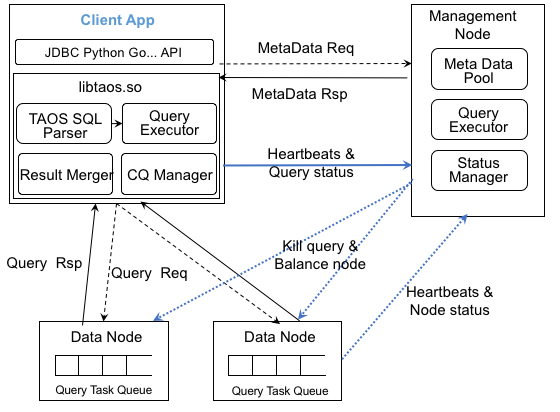
Query Process Design
The client, the management node, and the data node cooperate to complete the entire query processing of TDengine. Let's take a concrete SQL query as an example to illustrate the whole query processing flow. The SQL statement is to query on super table FOO_SUPER_TABLE to get the total number of records generated on January 12, 2019, from the table, of which TAG_LOC equals to 'beijing'. The SQL statement is as follows:
SELECT COUNT(*)
FROM FOO_SUPER_TABLE
WHERE TAG_LOC = 'beijing' AND TS >= '2019-01-12 00:00:00' AND TS < '2019-01-13 00:00:00'
First, the client invokes the TAOS SQL parser to parse and validate the SQL statement, then generates a syntax tree, and extracts the object of the query - the super table FOO_SUPER_TABLE, and then the parser sends requests with filtering information (TAG_LOC='beijing') to management node to get the corresponding metadata about FOO_SUPER_TABLE.
Once the management node receives the request for metadata acquisition, first finds the super table FOO_SUPER_TABLE basic information, and then applies the query condition (TAG_LOC='beijing') to filter all the related tables created according to it. And finally, the query executor returns the metadata information that satisfies the query request to the client.
After the client obtains the metadata information of FOO_SUPER_TABLE, the query executor initiates a query request with timestamp range filtering condition (TS >= '2019- 01-12 00:00:00' AND TS < '2019-01-13 00:00:00') to all nodes that hold the corresponding data according to the information about data distribution in metadata.
The data node receives the query sent from the client, converts it into an internal structure and puts it into the query task queue to be executed by query executor after optimizing the execution plan. When the query result is obtained, the query result is returned to the client. It should be noted that the data nodes perform the query process independently of each other, and rely solely on their data and content for processing.
When all data nodes involved in the query return results, the client aggregates the result sets from each data node. In this case, all results are accumulated to generate the final query result. The second stage of aggregation is not always required for all queries. For example, a column selection query does not require a second-stage aggregation at all.
REST Query Process
In addition to C/C++, Python, and JDBC interface, TDengine also provides a REST interface based on the HTTP protocol, which is different from using the client application programming interface. When the user uses the REST interface, all the query processing is completed on the server-side, and the user's application is not involved in query processing anymore. After the query processing is completed, the result is returned to the client through the HTTP JSON string.
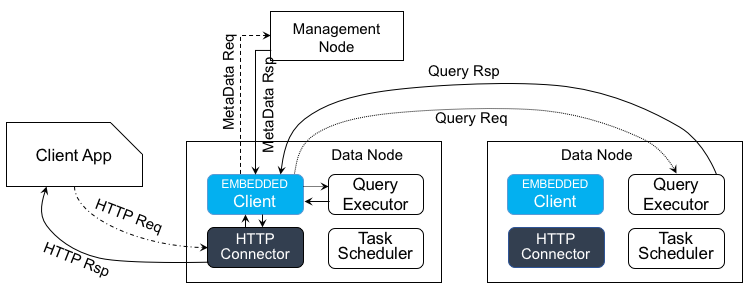
When a client uses an HTTP-based REST query interface, the client first establishes a connection with the HTTP connector at the data node and then uses the token to ensure the reliability of the request through the REST signature mechanism. For the data node, after receiving the request, the HTTP connector invokes the embedded client program to initiate a query processing, and then the embedded client parses the SQL statement from the HTTP connector and requests the management node to get metadata as needed. After that, the embedded client sends query requests to the same data node or other nodes in the cluster and aggregates the calculation results on demand. Finally, you also need to convert the result of the query into a JSON format string and return it to the client via an HTTP response. After the HTTP connector receives the request SQL, the subsequent process processing is completely consistent with the query processing using the client application development kit.
It should be noted that during the entire processing, the client application is no longer involved in, and is only responsible for sending SQL requests through the HTTP protocol and receiving the results in JSON format. Besides, each data node is embedded with an HTTP connector and a client, so any data node in the cluster received requests from a client, the data node can initiate the query and return the result to the client through the HTTP protocol, with transfer the request to other data nodes.
Technology
Because TDengine stores data and tags value separately, the tag value is kept in the management node and directly associated with each table instead of records, resulting in a great reduction of the data storage. Therefore, the tag value can be managed by a fully in-memory structure. First, the filtering of the tag data can drastically reduce the data size involved in the second phase of the query. The query processing for the data is performed at the data node. TDengine takes advantage of the immutable characteristics of IoT data by calculating the maximum, minimum, and other statistics of the data in one data block on each saved data block, to effectively improve the performance of query processing. If the query process involves all the data of the entire data block, the pre-computed result is used directly, and the content of the data block is no longer needed. Since the size of disk space required to store the pre-computation result is much smaller than the size of the specific data, the pre-computation result can greatly reduce the disk IO and speed up the query processing.
TDengine employs column-oriented data storage techniques. When the data block is involved to be loaded from the disk for calculation, only the required column is read according to the query condition, and the read overhead can be minimized. The data of one column is stored in a contiguous memory block and therefore can make full use of the CPU L2 cache to greatly speed up the data scanning. Besides, TDengine utilizes the eagerly responding mechanism and returns a partial result before the complete result is acquired. For example, when the first batch of results is obtained, the data node immediately returns it directly to the client in case of a column select query.